 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtraction of Projection Profile, Run-Histogram and Entropy Features Straight from Run-Length Compressed Text-Documents
Paper and Code
Apr 02, 2014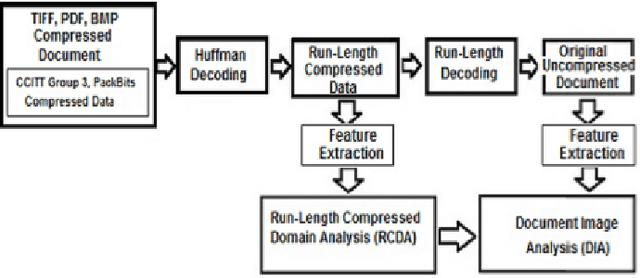
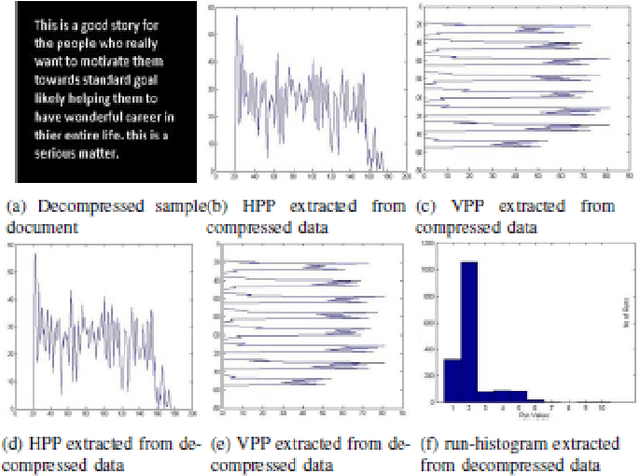
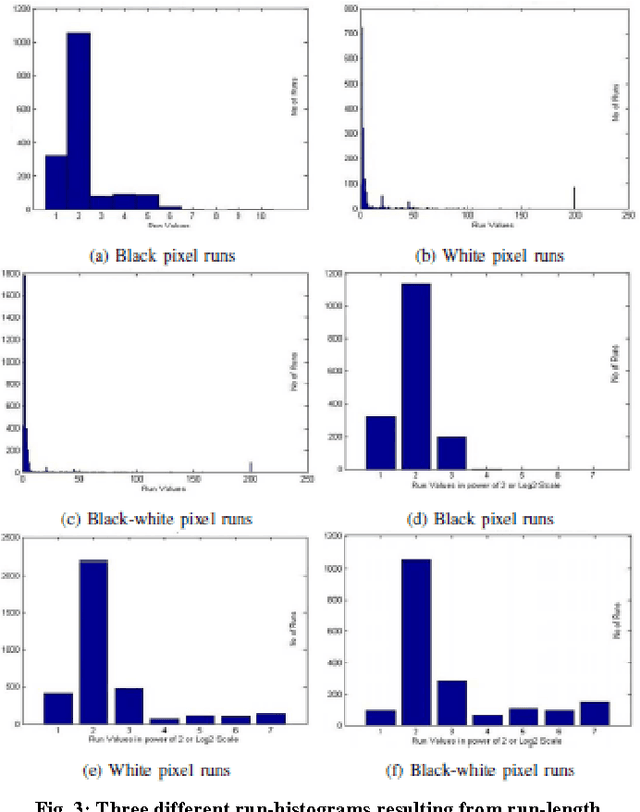
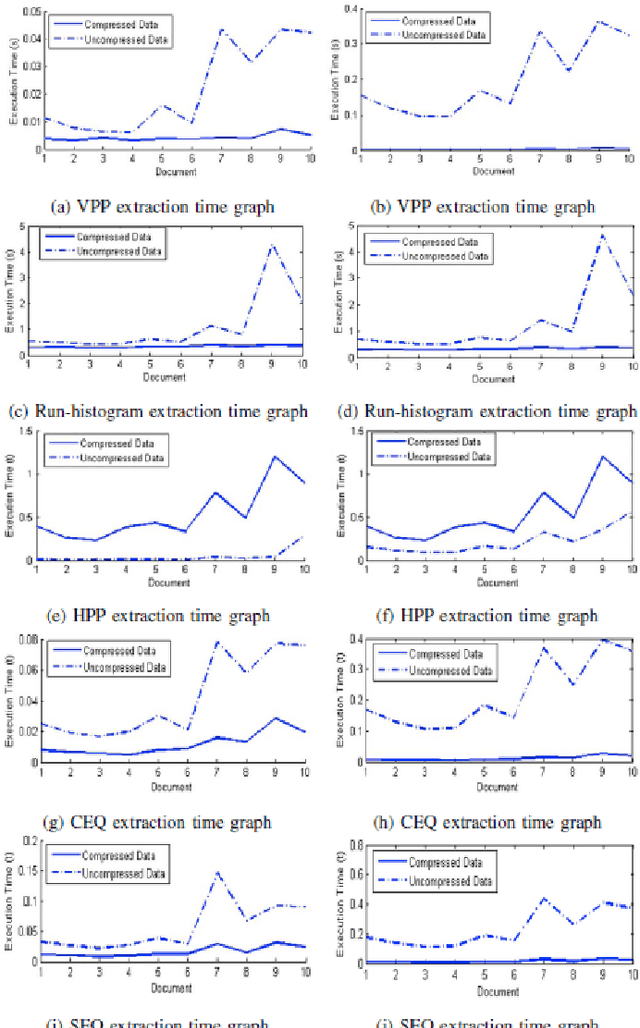
Document Image Analysis, like any Digital Image Analysis requires identification and extraction of proper features, which are generally extracted from uncompressed images, though in reality images are made available in compressed form for the reasons such as transmission and storage efficiency. However, this implies that the compressed image should be decompressed, which indents additional computing resources. This limitation induces the motivation to research in extracting features directly from the compressed image. In this research, we propose to extract essential features such as projection profile, run-histogram and entropy for text document analysis directly from run-length compressed text-documents. The experimentation illustrates that features are extracted directly from the compressed image without going through the stage of decompression, because of which the computing time is reduced. The feature values so extracted are exactly identical to those extracted from uncompressed images.