 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring of people entering and exiting private areas using Computer Vision
Aug 28, 2019



Entry-Exit surveillance is a novel research problem that addresses security concerns when people attain absolute privacy in camera forbidden areas such as toilets and changing rooms that are basic amenities to the humans in public places such as Shopping malls, Airports, Bus and Rail stations. The objective is, if not inside these camera forbidden areas, from outside, the individuals are to be monitored to analyze the time spent by them inside and also the suspecting transformations in their appearances if any. In this paper, firstly, a pseudo-annotated dataset of a laboratory observation of people entering and exiting the camera forbidden area captured using two cameras in contrast to the state-of-the-art single-camera based EnEx dataset is presented. Conventionally the proposed dataset is named \textbf{\textit{EnEx2}}. Next, a spatial transition based event detection to determine the entry or exit of individuals is presented with standard results by evaluating the proposed model using the proposed dataset and the publicly available standard video surveillance datasets that are hypothesized to Entry-Exit surveillance scenarios. The proposed dataset is expected to enkindle active research in Entry-Exit Surveillance domain.
Appearance invariant Entry-Exit matching using visual soft biometric traits
Aug 26, 2019

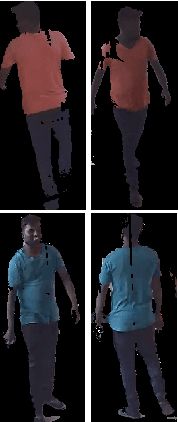

The problem of appearance invariant subject recognition for Entry-Exit surveillance applications is addressed. A novel Semantic Entry-Exit matching model that makes use of ancillary information about subjects such as height, build, complexion and clothing color to endorse exit of every subject who had entered private area is proposed in this paper. The proposed method is robust to variations in clothing. Each describing attribute is given equal weight while computing the matching score and hence the proposed model achieves high rank-k accuracy on benchmark datasets. The soft biometric traits used as a combination though cannot achieve high rank-1 accuracy, it helps to narrow down the search to match using reliable biometric traits such as gait and face whose learning and matching time is costlier when compared to the visual soft biometrics.
Automatic Text Line Segmentation Directly in JPEG Compressed Document Images
Jul 29, 2019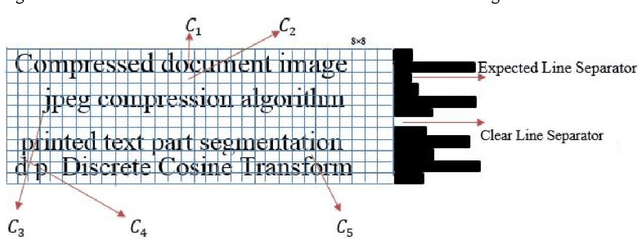
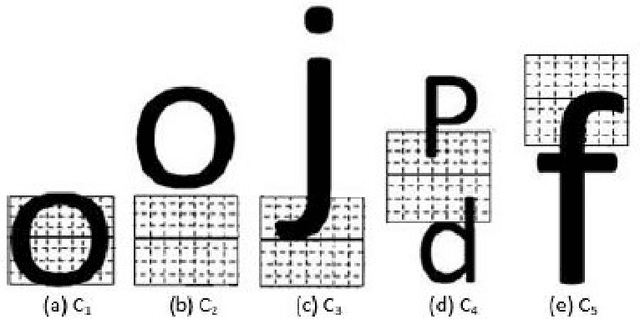


JPEG is one of the popular image compression algorithms that provide efficient storage and transmission capabilities in consumer electronics, and hence it is the most preferred image format over the internet world. In the present digital and Big-data era, a huge volume of JPEG compressed document images are being archived and communicated through consumer electronics on daily basis. Though it is advantageous to have data in the compressed form on one side, however, on the other side processing with off-the-shelf methods becomes computationally expensive because it requires decompression and recompression operations. Therefore, it would be novel and efficient, if the compressed data are processed directly in their respective compressed domains of consumer electronics. In the present research paper, we propose to demonstrate this idea taking the case study of printed text line segmentation. Since, JPEG achieves compression by dividing the image into non overlapping 8x8 blocks in the pixel domain and using Discrete Cosine Transform (DCT); it is very likely that the partitioned 8x8 DCT blocks overlap the contents of two adjacent text-lines without leaving any clue for the line separator, thus making text-line segmentation a challenging problem. Two approaches of segmentation have been proposed here using the DC projection profile and AC coefficients of each 8x8 DCT block. The first approach is based on the strategy of partial decompression of selected DCT blocks, and the second approach is with intelligent analysis of F10 and F11 AC coefficients and without using any type of decompression. The proposed methods have been tested with variable font sizes, font style and spacing between lines, and a good performance is reported.