 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCT-CompCNN: A Novel Image Classification Network Using JPEG Compressed DCT Coefficients
Paper and Code
Jul 26, 2019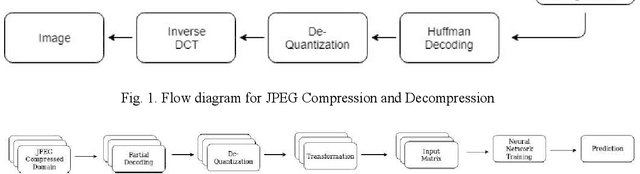
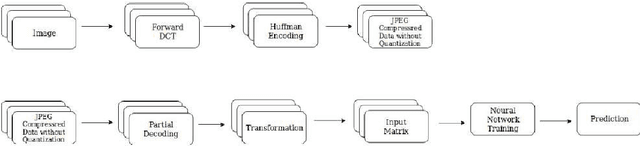
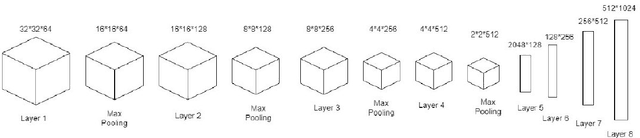
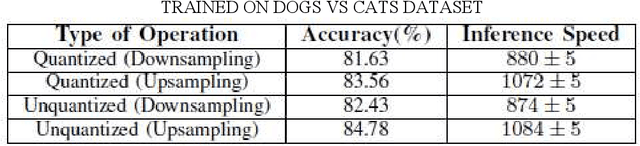
The popularity of Convolutional Neural Network (CNN) in the field of Image Processing and Computer Vision has motivated researchers and industrialist experts across the globe to solve different challenges with high accuracy. The simplest way to train a CNN classifier is to directly feed the original RGB pixels images into the network. However, if we intend to classify images directly with its compressed data, the same approach may not work better, like in case of JPEG compressed images. This research paper investigates the issues of modifying the input representation of the JPEG compressed data, and then feeding into the CNN. The architecture is termed as DCT-CompCNN. This novel approach has shown that CNNs can also be trained with JPEG compressed DCT coefficients, and subsequently can produce a better performance in comparison with the conventional CNN approach. The efficiency of the modified input representation is tested with the existing ResNet-50 architecture and the proposed DCT-CompCNN architecture on a public image classification datasets like Dog Vs Cat and CIFAR-10 datasets, reporting a better performance