 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Adaptive Hypergraph Transformer for Skeleton-based Activity Recognition
Nov 08, 2024
Extracting multiscale contextual information and higher-order correlations among skeleton sequences using Graph Convolutional Networks (GCNs) alone is inadequate for effective action classification. Hypergraph convolution addresses the above issues but cannot harness the long-range dependencies. Transformer proves to be effective in capturing these dependencies and making complex contextual features accessible. We propose an Autoregressive Adaptive HyperGraph Transformer (AutoregAd-HGformer) model for in-phase (autoregressive and discrete) and out-phase (adaptive) hypergraph generation. The vector quantized in-phase hypergraph equipped with powerful autoregressive learned priors produces a more robust and informative representation suitable for hyperedge formation. The out-phase hypergraph generator provides a model-agnostic hyperedge learning technique to align the attributes with input skeleton embedding. The hybrid (supervised and unsupervised) learning in AutoregAd-HGformer explores the action-dependent feature along spatial, temporal, and channel dimensions. The extensive experimental results and ablation study indicate the superiority of our model over state-of-the-art hypergraph architectures on NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.
CFAT: Unleashing TriangularWindows for Image Super-resolution
Mar 24, 2024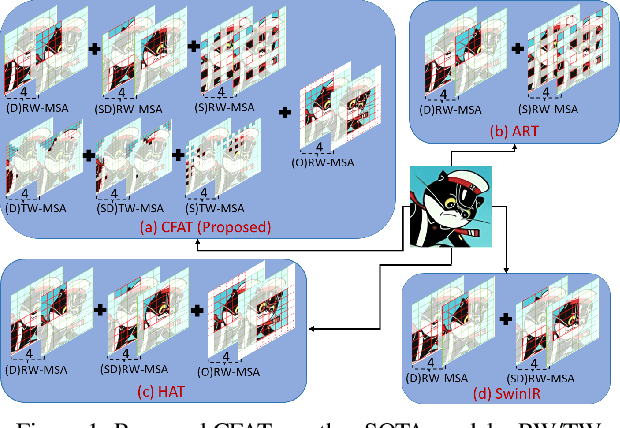
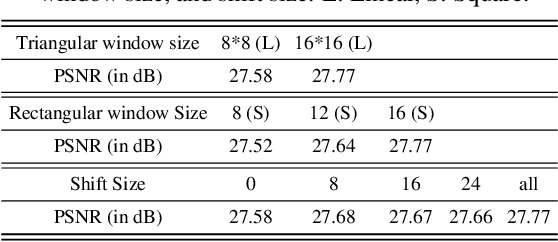
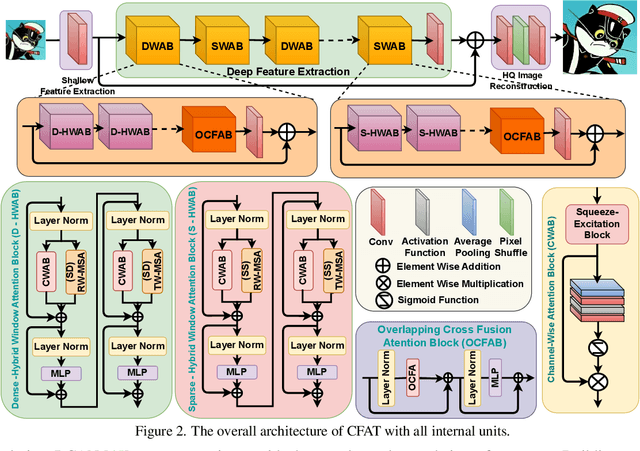
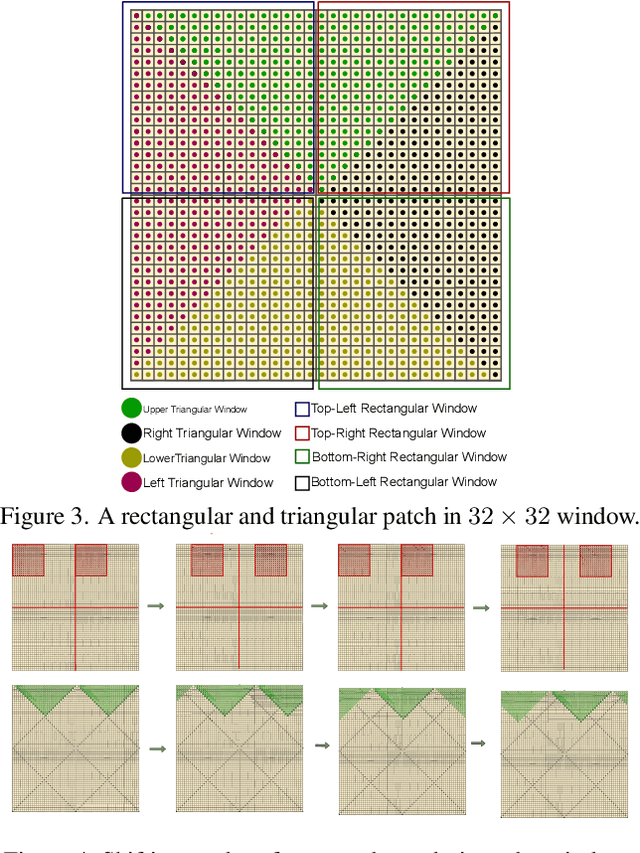
Transformer-based models have revolutionized the field of image super-resolution (SR) by harnessing their inherent ability to capture complex contextual features. The overlapping rectangular shifted window technique used in transformer architecture nowadays is a common practice in super-resolution models to improve the quality and robustness of image upscaling. However, it suffers from distortion at the boundaries and has limited unique shifting modes. To overcome these weaknesses, we propose a non-overlapping triangular window technique that synchronously works with the rectangular one to mitigate boundary-level distortion and allows the model to access more unique sifting modes. In this paper, we propose a Composite Fusion Attention Transformer (CFAT) that incorporates triangular-rectangular window-based local attention with a channel-based global attention technique in image super-resolution. As a result, CFAT enables attention mechanisms to be activated on more image pixels and captures long-range, multi-scale features to improve SR performance. The extensive experimental results and ablation study demonstrate the effectiveness of CFAT in the SR domain. Our proposed model shows a significant 0.7 dB performance improvement over other state-of-the-art SR architectures.
Visual Interest Prediction with Attentive Multi-Task Transfer Learning
May 27, 2020

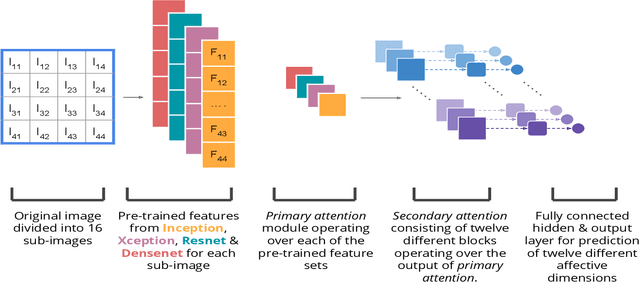

Visual interest & affect prediction is a very interesting area of research in the area of computer vision. In this paper, we propose a transfer learning and attention mechanism based neural network model to predict visual interest & affective dimensions in digital photos. Learning the multi-dimensional affects is addressed through a multi-task learning framework. With various experiments we show the effectiveness of the proposed approach. Evaluation of our model on the benchmark dataset shows large improvement over current state-of-the-art systems.