 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Specific Representation Abstraction for Deep Option Learning
Paper and Code

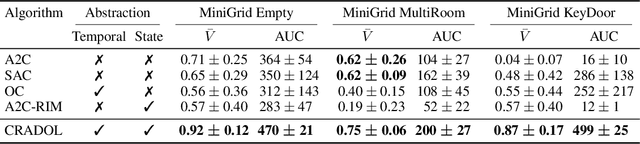
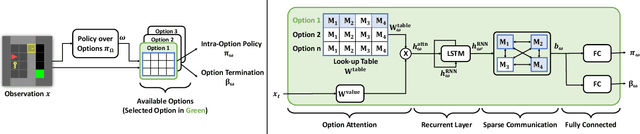
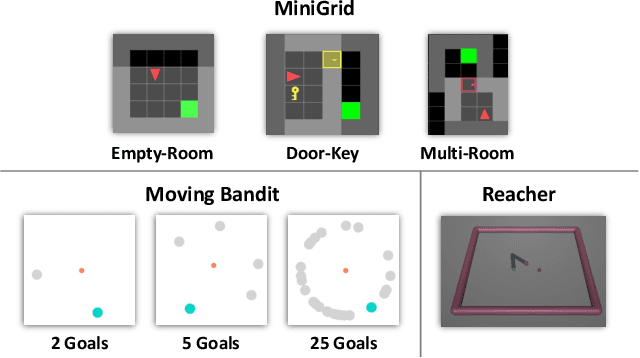
Hierarchical reinforcement learning has focused on discovering temporally extended actions, such as options, that can provide benefits in problems requiring extensive exploration. One promising approach that learns these options end-to-end is the option-critic (OC) framework. We examine and show in this paper that OC does not decompose a problem into simpler sub-problems, but instead increases the size of the search over policy space with each option considering the entire state space during learning. This issue can result in practical limitations of this method, including sample inefficient learning. To address this problem, we introduce Context-Specific Representation Abstraction for Deep Option Learning (CRADOL), a new framework that considers both temporal abstraction and context-specific representation abstraction to effectively reduce the size of the search over policy space. Specifically, our method learns a factored belief state representation that enables each option to learn a policy over only a subsection of the state space. We test our method against hierarchical, non-hierarchical, and modular recurrent neural network baselines, demonstrating significant sample efficiency improvements in challenging partially observable environments.