 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning
Oct 31, 2020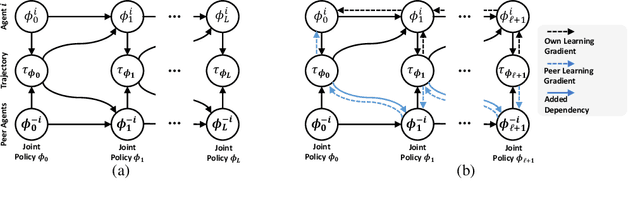
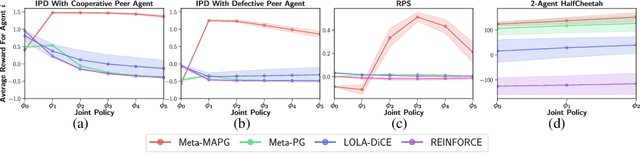

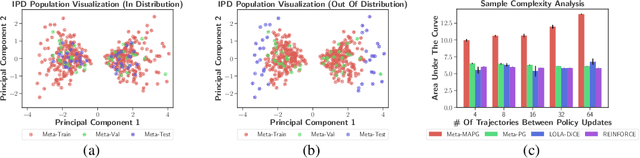
A fundamental challenge in multiagent reinforcement learning is to learn beneficial behaviors in a shared environment with other agents that are also simultaneously learning. In particular, each agent perceives the environment as effectively non-stationary due to the changing policies of other agents. Moreover, each agent is itself constantly learning, leading to natural nonstationarity in the distribution of experiences encountered. In this paper, we propose a novel meta-multiagent policy gradient theorem that directly accommodates for the non-stationary policy dynamics inherent to these multiagent settings. This is achieved by modeling our gradient updates to directly consider both an agent's own non-stationary policy dynamics and the non-stationary policy dynamics of other agents interacting with it in the environment. We find that our theoretically grounded approach provides a general solution to the multiagent learning problem, which inherently combines key aspects of previous state of the art approaches on this topic. We test our method on several multiagent benchmarks and demonstrate a more efficient ability to adapt to new agents as they learn than previous related approaches across the spectrum of mixed incentive, competitive, and cooperative environments.
Learning Hierarchical Teaching in Cooperative Multiagent Reinforcement Learning
Mar 07, 2019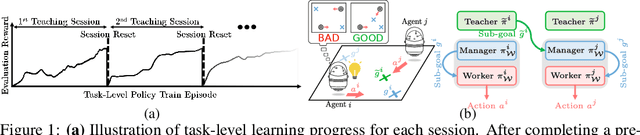
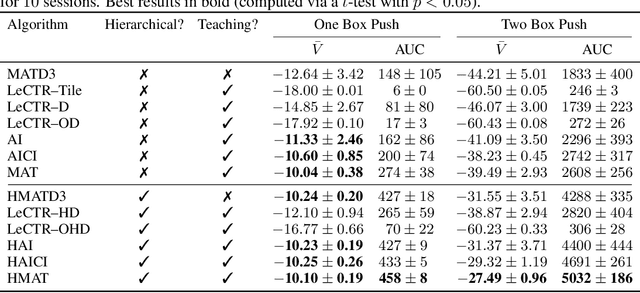
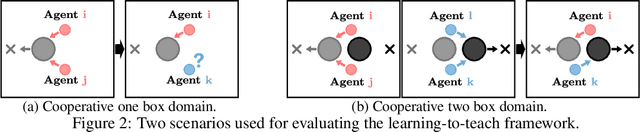

Heterogeneous knowledge naturally arises among different agents in cooperative multiagent reinforcement learning. As such, learning can be greatly improved if agents can effectively pass their knowledge on to other agents. Existing work has demonstrated that peer-to-peer knowledge transfer, a process referred to as action advising, improves team-wide learning. In contrast to previous frameworks that advise at the level of primitive actions, we aim to learn high-level teaching policies that decide when and what high-level action (e.g., sub-goal) to advise a teammate. We introduce a new learning to teach framework, called hierarchical multiagent teaching (HMAT). The proposed framework solves difficulties faced by prior work on multiagent teaching when operating in domains with long horizons, delayed rewards, and continuous states/actions by leveraging temporal abstraction and deep function approximation. Our empirical evaluations show that HMAT accelerates team-wide learning progress in difficult environments that are more complex than those explored in previous work. HMAT also learns teaching policies that can be transferred to different teammates/tasks and can even teach teammates with heterogeneous action spaces.