 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Multiple Strategies to Improve Multilingual Coreference Resolution in CorefUD
Paper and Code


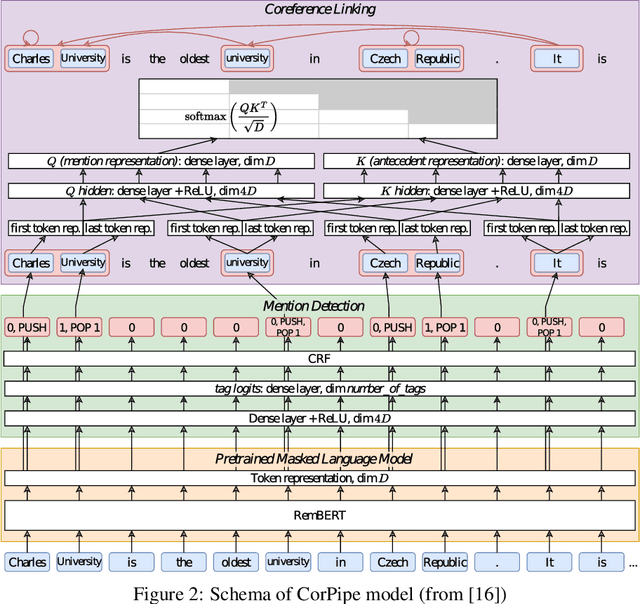

Coreference resolution, the task of identifying expressions in text that refer to the same entity, is a critical component in various natural language processing (NLP) applications. This paper presents our end-to-end neural coreference resolution system, utilizing the CorefUD 1.1 dataset, which spans 17 datasets across 12 languages. We first establish strong baseline models, including monolingual and cross-lingual variations, and then propose several extensions to enhance performance across diverse linguistic contexts. These extensions include cross-lingual training, incorporation of syntactic information, a Span2Head model for optimized headword prediction, and advanced singleton modeling. We also experiment with headword span representation and long-documents modeling through overlapping segments. The proposed extensions, particularly the heads-only approach, singleton modeling, and long document prediction significantly improve performance across most datasets. We also perform zero-shot cross-lingual experiments, highlighting the potential and limitations of cross-lingual transfer in coreference resolution. Our findings contribute to the development of robust and scalable coreference systems for multilingual coreference resolution. Finally, we evaluate our model on CorefUD 1.1 test set and surpass the best model from CRAC 2023 shared task of a comparable size by a large margin. Our nodel is available on GitHub: \url{https://github.com/ondfa/coref-multiling}