 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond a Single Reference: Training and Evaluation with Paraphrases in Sign Language Translation
Jan 29, 2026Most Sign Language Translation (SLT) corpora pair each signed utterance with a single written-language reference, despite the highly non-isomorphic relationship between sign and spoken languages, where multiple translations can be equally valid. This limitation constrains both model training and evaluation, particularly for n-gram-based metrics such as BLEU. In this work, we investigate the use of Large Language Models to automatically generate paraphrased variants of written-language translations as synthetic alternative references for SLT. First, we compare multiple paraphrasing strategies and models using an adapted ParaScore metric. Second, we study the impact of paraphrases on both training and evaluation of the pose-based T5 model on the YouTubeASL and How2Sign datasets. Our results show that naively incorporating paraphrases during training does not improve translation performance and can even be detrimental. In contrast, using paraphrases during evaluation leads to higher automatic scores and better alignment with human judgments. To formalize this observation, we introduce BLEUpara, an extension of BLEU that evaluates translations against multiple paraphrased references. Human evaluation confirms that BLEUpara correlates more strongly with perceived translation quality. We release all generated paraphrases, generation and evaluation code to support reproducible and more reliable evaluation of SLT systems.
Learning from What is Already Out There: Few-shot Sign Language Recognition with Online Dictionaries
Jan 10, 2023Today's sign language recognition models require large training corpora of laboratory-like videos, whose collection involves an extensive workforce and financial resources. As a result, only a handful of such systems are publicly available, not to mention their limited localization capabilities for less-populated sign languages. Utilizing online text-to-video dictionaries, which inherently hold annotated data of various attributes and sign languages, and training models in a few-shot fashion hence poses a promising path for the democratization of this technology. In this work, we collect and open-source the UWB-SL-Wild few-shot dataset, the first of its kind training resource consisting of dictionary-scraped videos. This dataset represents the actual distribution and characteristics of available online sign language data. We select glosses that directly overlap with the already existing datasets WLASL100 and ASLLVD and share their class mappings to allow for transfer learning experiments. Apart from providing baseline results on a pose-based architecture, we introduce a novel approach to training sign language recognition models in a few-shot scenario, resulting in state-of-the-art results on ASLLVD-Skeleton and ASLLVD-Skeleton-20 datasets with top-1 accuracy of $30.97~\%$ and $95.45~\%$, respectively.
Combining Efficient and Precise Sign Language Recognition: Good pose estimation library is all you need
Sep 30, 2022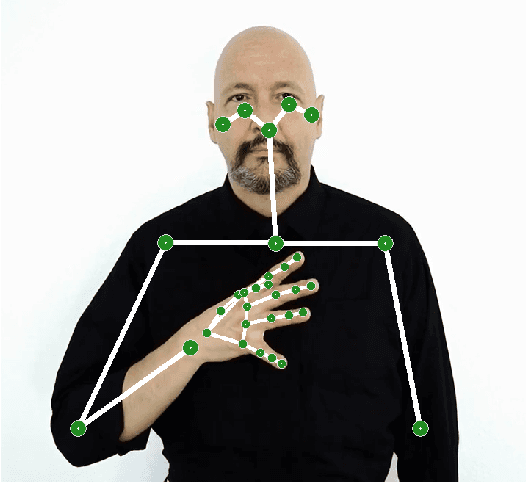

Sign language recognition could significantly improve the user experience for d/Deaf people with the general consumer technology, such as IoT devices or videoconferencing. However, current sign language recognition architectures are usually computationally heavy and require robust GPU-equipped hardware to run in real-time. Some models aim for lower-end devices (such as smartphones) by minimizing their size and complexity, which leads to worse accuracy. This highly scrutinizes accurate in-the-wild applications. We build upon the SPOTER architecture, which belongs to the latter group of light methods, as it came close to the performance of large models employed for this task. By substituting its original third-party pose estimation module with the MediaPipe library, we achieve an overall state-of-the-art result on the WLASL100 dataset. Significantly, our method beats previous larger architectures while still being twice as computationally efficient and almost $11$ times faster on inference when compared to a relevant benchmark. To demonstrate our method's combined efficiency and precision, we built an online demo that enables users to translate sign lemmas of American sign language in their browsers. This is the first publicly available online application demonstrating this task to the best of our knowledge.
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
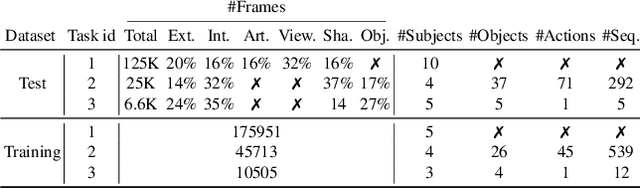
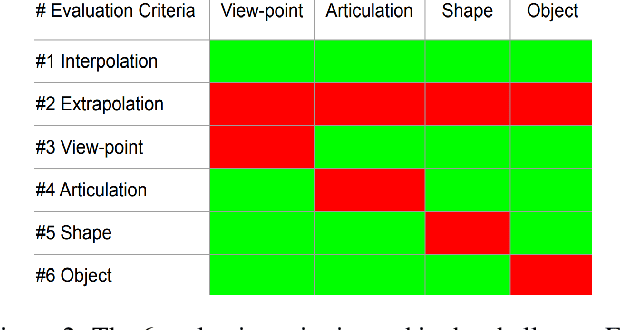
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.