 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$γ$-Quant: Towards Learnable Quantization for Low-bit Pattern Recognition
Sep 26, 2025Most pattern recognition models are developed on pre-proce\-ssed data. In computer vision, for instance, RGB images processed through image signal processing (ISP) pipelines designed to cater to human perception are the most frequent input to image analysis networks. However, many modern vision tasks operate without a human in the loop, raising the question of whether such pre-processing is optimal for automated analysis. Similarly, human activity recognition (HAR) on body-worn sensor data commonly takes normalized floating-point data arising from a high-bit analog-to-digital converter (ADC) as an input, despite such an approach being highly inefficient in terms of data transmission, significantly affecting the battery life of wearable devices. In this work, we target low-bandwidth and energy-constrained settings where sensors are limited to low-bit-depth capture. We propose $\gamma$-Quant, i.e.~the task-specific learning of a non-linear quantization for pattern recognition. We exemplify our approach on raw-image object detection as well as HAR of wearable data, and demonstrate that raw data with a learnable quantization using as few as 4-bits can perform on par with the use of raw 12-bit data. All code to reproduce our experiments is publicly available via https://github.com/Mishalfatima/Gamma-Quant
DeepConvContext: A Multi-Scale Approach to Timeseries Classification in Human Activity Recognition
May 27, 2025Despite recognized limitations in modeling long-range temporal dependencies, Human Activity Recognition (HAR) has traditionally relied on a sliding window approach to segment labeled datasets. Deep learning models like the DeepConvLSTM typically classify each window independently, thereby restricting learnable temporal context to within-window information. To address this constraint, we propose DeepConvContext, a multi-scale time series classification framework for HAR. Drawing inspiration from the vision-based Temporal Action Localization community, DeepConvContext models both intra- and inter-window temporal patterns by processing sequences of time-ordered windows. Unlike recent HAR models that incorporate attention mechanisms, DeepConvContext relies solely on LSTMs -- with ablation studies demonstrating the superior performance of LSTMs over attention-based variants for modeling inertial sensor data. Across six widely-used HAR benchmarks, DeepConvContext achieves an average 10% improvement in F1-score over the classic DeepConvLSTM, with gains of up to 21%. Code to reproduce our experiments is publicly available via github.com/mariusbock/context_har.
Label Leakage in Federated Inertial-based Human Activity Recognition
May 27, 2025



While prior work has shown that Federated Learning updates can leak sensitive information, label reconstruction attacks, which aim to recover input labels from shared gradients, have not yet been examined in the context of Human Activity Recognition (HAR). Given the sensitive nature of activity labels, this study evaluates the effectiveness of state-of-the-art gradient-based label leakage attacks on HAR benchmark datasets. Our findings show that the number of activity classes, sampling strategy, and class imbalance are critical factors influencing the extent of label leakage, with reconstruction accuracies reaching up to 90% on two benchmark datasets, even for trained models. Moreover, we find that Local Differential Privacy techniques such as gradient noise and clipping offer only limited protection, as certain attacks still reliably infer both majority and minority class labels. We conclude by offering practical recommendations for the privacy-aware deployment of federated HAR systems and identify open challenges for future research. Code to reproduce our experiments is publicly available via github.com/mariusbock/leakage_har.
Weak-Annotation of HAR Datasets using Vision Foundation Models
Aug 09, 2024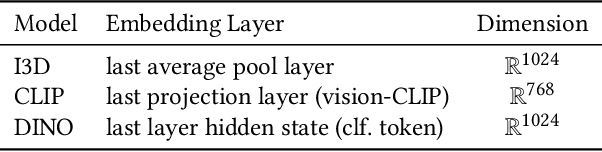
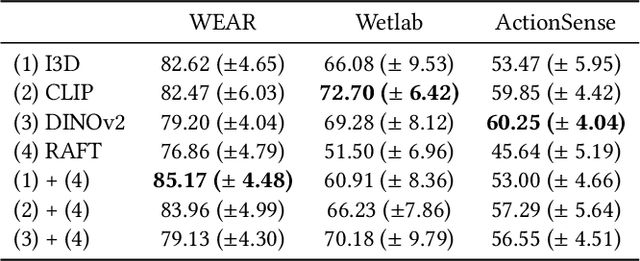
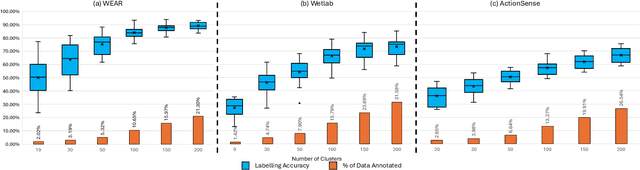
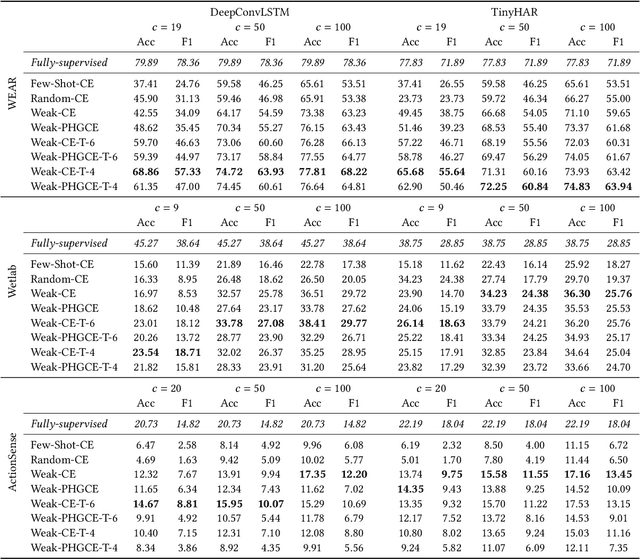
As wearable-based data annotation remains, to date, a tedious, time-consuming task requiring researchers to dedicate substantial time, benchmark datasets within the field of Human Activity Recognition in lack richness and size compared to datasets available within related fields. Recently, vision foundation models such as CLIP have gained significant attention, helping the vision community advance in finding robust, generalizable feature representations. With the majority of researchers within the wearable community relying on vision modalities to overcome the limited expressiveness of wearable data and accurately label their to-be-released benchmark datasets offline, we propose a novel, clustering-based annotation pipeline to significantly reduce the amount of data that needs to be annotated by a human annotator. We show that using our approach, the annotation of centroid clips suffices to achieve average labelling accuracies close to 90% across three publicly available HAR benchmark datasets. Using the weakly annotated datasets, we further demonstrate that we can match the accuracy scores of fully-supervised deep learning classifiers across all three benchmark datasets. Code as well as supplementary figures and results are publicly downloadable via github.com/mariusbock/weak_har.
Temporal Action Localization for Inertial-based Human Activity Recognition
Nov 27, 2023



A persistent trend in Deep Learning has been the applicability of machine learning concepts to other areas than originally introduced for. As of today, state-of-the-art activity recognition from wearable sensors relies on classifiers being trained on fixed windows of data. Contrarily, video-based Human Activity Recognition has followed a segment-based prediction approach, localizing activity occurrences from start to end. This paper is the first to systematically demonstrate the applicability of state-of-the-art TAL models for wearable Human Activity Recongition (HAR) using raw inertial data as input. Our results show that state-of-the-art TAL models are able to outperform popular inertial models on 4 out of 6 wearable activity recognition benchmark datasets, with improvements ranging as much as 25% in F1-score. Introducing the TAL community's most popular metric to inertial-based HAR, namely mean Average Precision, our analysis shows that TAL models are able to produce more coherent segments along with an overall higher NULL-class accuracy across all datasets. Being the first to provide such an analysis, the TAL community offers an interesting new perspective to inertial-based HAR with yet to be explored design choices and training concepts, which could be of significant value for the inertial-based HAR community.
Hang-Time HAR: A Benchmark Dataset for Basketball Activity Recognition using Wrist-worn Inertial Sensors
May 22, 2023



We present a benchmark dataset for evaluating physical human activity recognition methods from wrist-worn sensors, for the specific setting of basketball training, drills, and games. Basketball activities lend themselves well for measurement by wrist-worn inertial sensors, and systems that are able to detect such sport-relevant activities could be used in applications toward game analysis, guided training, and personal physical activity tracking. The dataset was recorded for two teams from separate countries (USA and Germany) with a total of 24 players who wore an inertial sensor on their wrist, during both repetitive basketball training sessions and full games. Particular features of this dataset include an inherent variance through cultural differences in game rules and styles as the data was recorded in two countries, as well as different sport skill levels, since the participants were heterogeneous in terms of prior basketball experience. We illustrate the dataset's features in several time-series analyses and report on a baseline classification performance study with two state-of-the-art deep learning architectures.
WEAR: A Multimodal Dataset for Wearable and Egocentric Video Activity Recognition
Apr 11, 2023
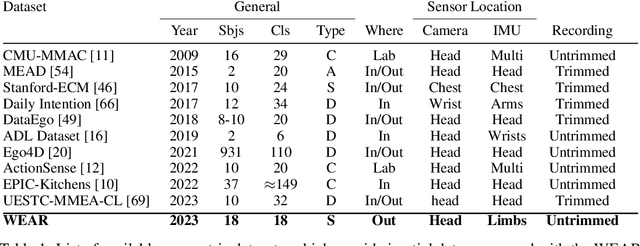


Though research has shown the complementarity of camera- and inertial-based data, datasets which offer both modalities remain scarce. In this paper we introduce WEAR, a multimodal benchmark dataset for both vision- and wearable-based Human Activity Recognition (HAR). The dataset comprises data from 18 participants performing a total of 18 different workout activities with untrimmed inertial (acceleration) and camera (egocentric video) data recorded at 10 different outside locations. WEAR features a diverse set of activities which are low in inter-class similarity and, unlike previous egocentric datasets, not defined by human-object-interactions nor originate from inherently distinct activity categories. Provided benchmark results reveal that single-modality architectures have different strengths and weaknesses in their prediction performance. Further, in light of the recent success of transformer-based video action detection models, we demonstrate their versatility by applying them in a plain fashion using vision, inertial and combined (vision + inertial) features as input. Results show that vision transformers are not only able to produce competitive results using only inertial data, but also can function as an architecture to fuse both modalities by means of simple concatenation, with the multimodal approach being able to produce the highest average mAP, precision and close-to-best F1-scores. Up until now, vision-based transformers have neither been explored in inertial nor in multimodal human activity recognition, making our approach the first to do so. The dataset and code to reproduce experiments is publicly available via: mariusbock.github.io/wear
Tutorial on Deep Learning for Human Activity Recognition
Oct 13, 2021
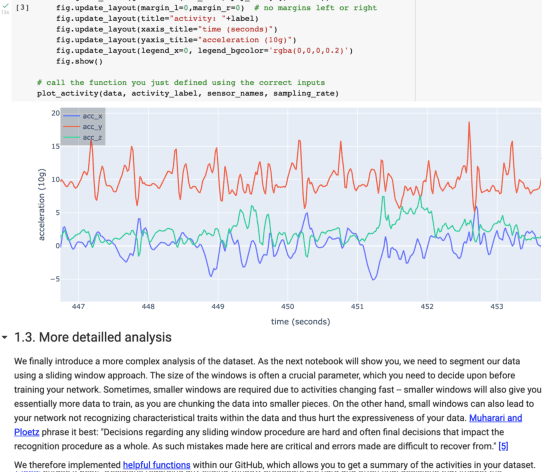
Activity recognition systems that are capable of estimating human activities from wearable inertial sensors have come a long way in the past decades. Not only have state-of-the-art methods moved away from feature engineering and have fully adopted end-to-end deep learning approaches, best practices for setting up experiments, preparing datasets, and validating activity recognition approaches have similarly evolved. This tutorial was first held at the 2021 ACM International Symposium on Wearable Computers (ISWC'21) and International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp'21). The tutorial, after a short introduction in the research field of activity recognition, provides a hands-on and interactive walk-through of the most important steps in the data pipeline for the deep learning of human activities. All presentation slides shown during the tutorial, which also contain links to all code exercises, as well as the link of the GitHub page of the tutorial can be found on: https://mariusbock.github.io/dl-for-har
Improving Deep Learning for HAR with shallow LSTMs
Aug 05, 2021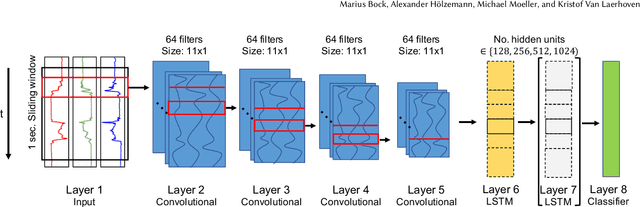
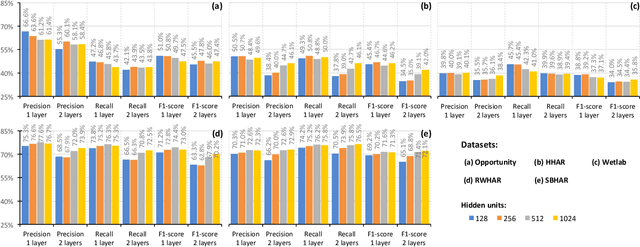
Recent studies in Human Activity Recognition (HAR) have shown that Deep Learning methods are able to outperform classical Machine Learning algorithms. One popular Deep Learning architecture in HAR is the DeepConvLSTM. In this paper we propose to alter the DeepConvLSTM architecture to employ a 1-layered instead of a 2-layered LSTM. We validate our architecture change on 5 publicly available HAR datasets by comparing the predictive performance with and without the change employing varying hidden units within the LSTM layer(s). Results show that across all datasets, our architecture consistently improves on the original one: Recognition performance increases up to 11.7% for the F1-score, and our architecture significantly decreases the amount of learnable parameters. This improvement over DeepConvLSTM decreases training time by as much as 48%. Our results stand in contrast to the belief that one needs at least a 2-layered LSTM when dealing with sequential data. Based on our results we argue that said claim might not be applicable to sensor-based HAR.