 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWEAR: A Multimodal Dataset for Wearable and Egocentric Video Activity Recognition
Paper and Code

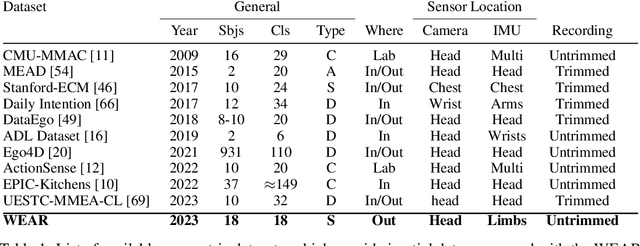


Though research has shown the complementarity of camera- and inertial-based data, datasets which offer both modalities remain scarce. In this paper we introduce WEAR, a multimodal benchmark dataset for both vision- and wearable-based Human Activity Recognition (HAR). The dataset comprises data from 18 participants performing a total of 18 different workout activities with untrimmed inertial (acceleration) and camera (egocentric video) data recorded at 10 different outside locations. WEAR features a diverse set of activities which are low in inter-class similarity and, unlike previous egocentric datasets, not defined by human-object-interactions nor originate from inherently distinct activity categories. Provided benchmark results reveal that single-modality architectures have different strengths and weaknesses in their prediction performance. Further, in light of the recent success of transformer-based video action detection models, we demonstrate their versatility by applying them in a plain fashion using vision, inertial and combined (vision + inertial) features as input. Results show that vision transformers are not only able to produce competitive results using only inertial data, but also can function as an architecture to fuse both modalities by means of simple concatenation, with the multimodal approach being able to produce the highest average mAP, precision and close-to-best F1-scores. Up until now, vision-based transformers have neither been explored in inertial nor in multimodal human activity recognition, making our approach the first to do so. The dataset and code to reproduce experiments is publicly available via: mariusbock.github.io/wear