 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Feature Quantity on Recommendation Algorithm Performance: A Movielens-100K Case Study
Paper and Code
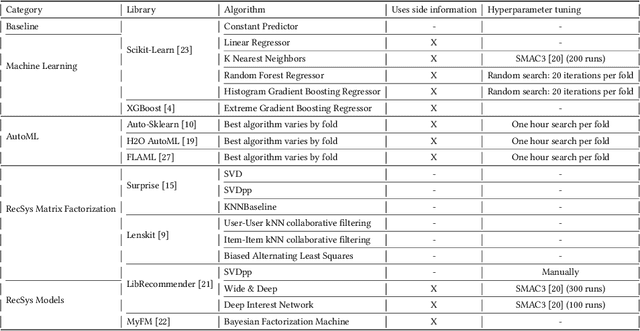
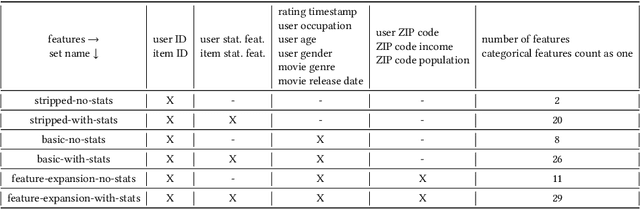
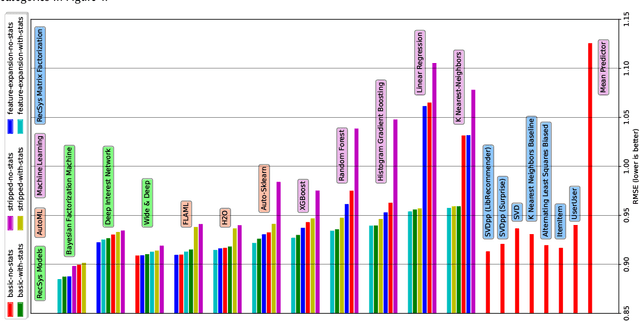
Recent model-based Recommender Systems (RecSys) algorithms emphasize on the use of features, also called side information, in their design similar to algorithms in Machine Learning (ML). In contrast, some of the most popular and traditional algorithms for RecSys solely focus on a given user-item-rating relation without including side information. The goal of this case study is to provide a performance comparison and assessment of RecSys and ML algorithms when side information is included. We chose the Movielens-100K data set since it is a standard for comparing RecSys algorithms. We compared six different feature sets with varying quantities of features which were generated from the baseline data and evaluated on a total of 19 RecSys algorithms, baseline ML algorithms, Automated Machine Learning (AutoML) pipelines, and state-of-the-art RecSys algorithms that incorporate side information. The results show that additional features benefit all algorithms we evaluated. However, the correlation between feature quantity and performance is not monotonous for AutoML and RecSys. In these categories, an analysis of feature importance revealed that the quality of features matters more than quantity. Throughout our experiments, the average performance on the feature set with the lowest number of features is about 6% worse compared to that with the highest in terms of the Root Mean Squared Error. An interesting observation is that AutoML outperforms matrix factorization-based RecSys algorithms when additional features are used. Almost all algorithms that can include side information have higher performance when using the highest quantity of features. In the other cases, the performance difference is negligible (<1%). The results show a clear positive trend for the effect of feature quantity as well as the important effects of feature quality on the evaluated algorithms.