 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Influence of Data Characteristics on the Performance of Point-of-Interest Recommendation Algorithms
Nov 13, 2023The performance of recommendation algorithms is closely tied to key characteristics of the data sets they use, such as sparsity, popularity bias, and preference distributions. In this paper, we conduct a comprehensive explanatory analysis to shed light on the impact of a broad range of data characteristics within the point-of-interest (POI) recommendation domain. To accomplish this, we extend prior methodologies used to characterize traditional recommendation problems by introducing new explanatory variables specifically relevant to POI recommendation. We subdivide a POI recommendation data set on New York City into domain-driven subsamples to measure the effect of varying these characteristics on different state-of-the-art POI recommendation algorithms in terms of accuracy, novelty, and item exposure. Our findings, obtained through the application of an explanatory framework employing multiple-regression models, reveal that the relevant independent variables encompass all categories of data characteristics and account for as much as $R^2 = $ 85-90\% of the accuracy and item exposure achieved by the algorithms. Our study reaffirms the pivotal role of prominent data characteristics, such as density, popularity bias, and the distribution of check-ins in POI recommendation. Additionally, we unveil novel factors, such as the proximity of user activity to the city center and the duration of user activity. In summary, our work reveals why certain POI recommendation algorithms excel in specific recommendation problems and, conversely, offers practical insights into which data characteristics should be modified (or explicitly recognized) to achieve better performance.
Point-of-Interest Recommender Systems: A Survey from an Experimental Perspective
Jun 18, 2021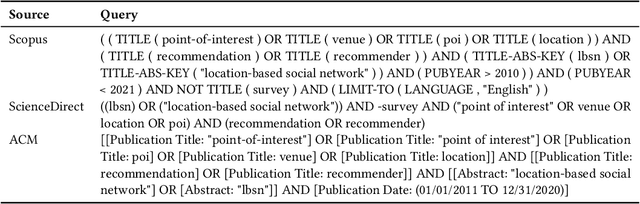
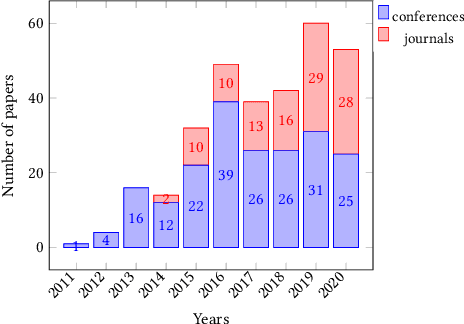

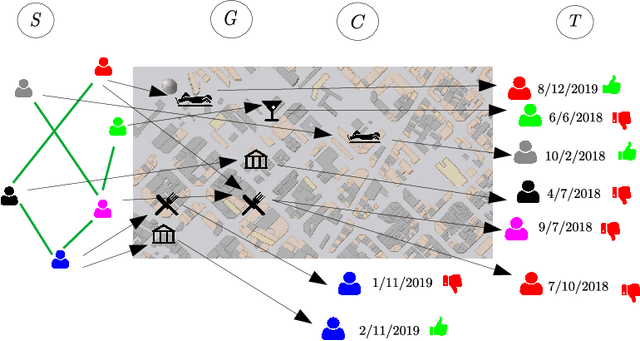
Point-of-Interest recommendation is an increasing research and developing area within the widely adopted technologies known as Recommender Systems. Among them, those that exploit information coming from Location-Based Social Networks (LBSNs) are very popular nowadays and could work with different information sources, which pose several challenges and research questions to the community as a whole. We present a systematic review focused on the research done in the last 10 years about this topic. We discuss and categorize the algorithms and evaluation methodologies used in these works and point out the opportunities and challenges that remain open in the field. More specifically, we report the leading recommendation techniques and information sources that have been exploited more often (such as the geographical signal and deep learning approaches) while we also alert about the lack of reproducibility in the field that may hinder real performance improvements.
A novel approach for venue recommendation using cross-domain techniques
Sep 26, 2018

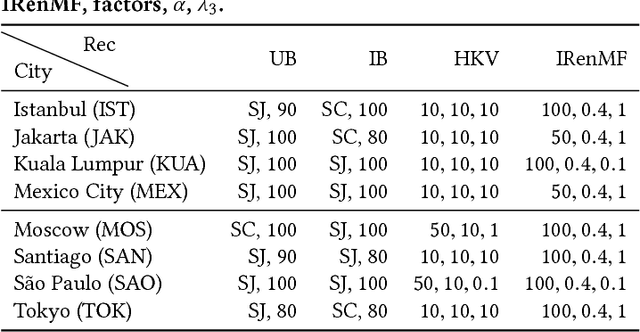
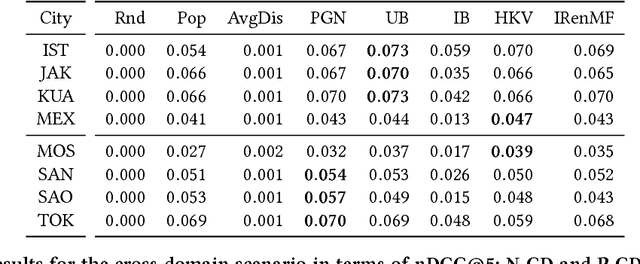
Finding the next venue to be visited by a user in a specific city is an interesting, but challenging, problem. Different techniques have been proposed, combining collaborative, content, social, and geographical signals; however it is not trivial to decide which tech- nique works best, since this may depend on the data density or the amount of activity logged for each user or item. At the same time, cross-domain strategies have been exploited in the recommender systems literature when dealing with (very) sparse situations, such as those inherently arising when recommendations are produced based on information from a single city. In this paper, we address the problem of venue recommendation from a novel perspective: applying cross-domain recommenda- tion techniques considering each city as a different domain. We perform an experimental comparison of several recommendation techniques in a temporal split under two conditions: single-domain (only information from the target city is considered) and cross- domain (information from many other cities is incorporated into the recommendation algorithm). For the latter, we have explored two strategies to transfer knowledge from one domain to another: testing the target city and training a model with information of the k cities with more ratings or only using the k closest cities. Our results show that, in general, applying cross-domain by proximity increases the performance of the majority of the recom- menders in terms of relevance. This is the first work, to the best of our knowledge, where so many domains (eight) are combined in the tourism context where a temporal split is used, and thus we expect these results could provide readers with an overall picture of what can be achieved in a real-world environment.