 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Machine Learning in Recommender Systems: State of the art and Challenges
Paper and Code
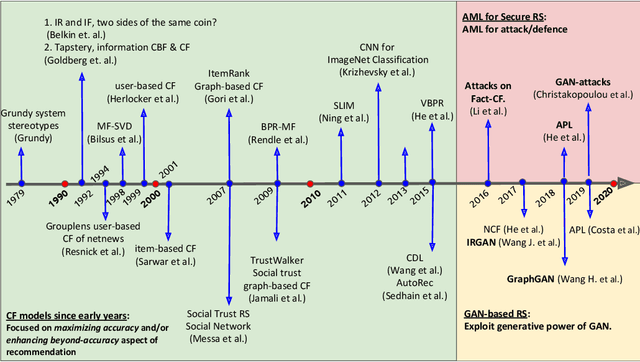
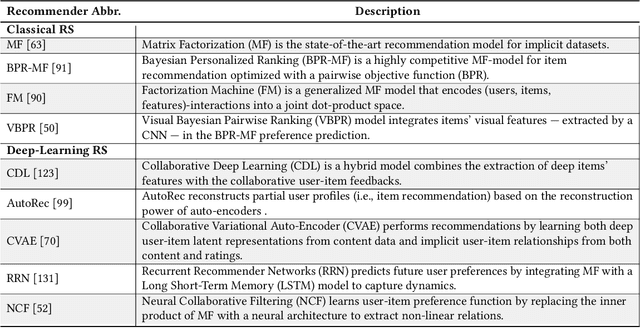

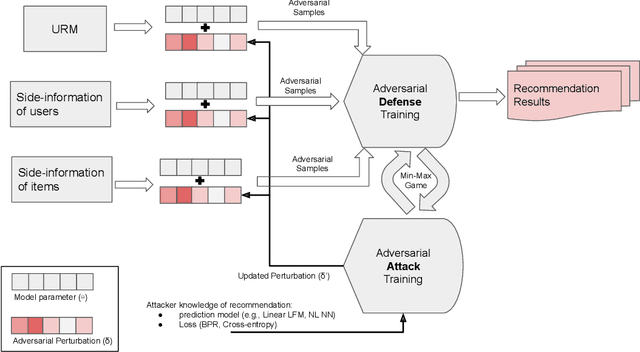
Latent-factor models (LFM) based on collaborative filtering (CF), such as matrix factorization (MF) and deep CF methods, are widely used in modern recommender systems (RS) due to their excellent performance and recommendation accuracy. Notwithstanding their great success, in recent years, it has been shown that these methods are vulnerable to adversarial examples, i.e., subtle but non-random perturbations designed to force recommendation models to produce erroneous outputs. The main reason for this behavior is that user interaction data used for training of LFM can be contaminated by malicious activities or users' misoperation that can induce an unpredictable amount of natural noise and harm recommendation outcomes. On the other side, it has been shown that these systems, conceived originally to attack machine learning applications, can be successfully adopted to strengthen their robustness against attacks as well as to train more precise recommendation engines. In this respect, the goal of this survey is two-fold: (i) to present recent advances on AML-RS for the security of RS (i.e., attacking and defense recommendation models), (ii) to show another successful application of AML in generative adversarial networks (GANs), which use the core concept of learning in AML (i.e., the min-max game) for generative applications. In this survey, we provide an exhaustive literature review of 60 articles published in major RS and ML journals and conferences. This review serves as a reference for the RS community, working on the security of RS and recommendation models leveraging generative models to improve their quality.