 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSetting the Record Straight on Transformer Oversmoothing
Jan 09, 2024

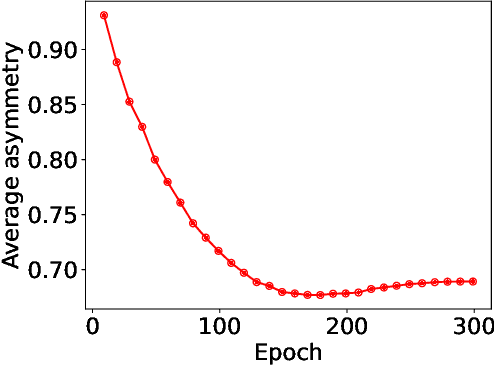
Transformer-based models have recently become wildly successful across a diverse set of domains. At the same time, recent work has shown that Transformers are inherently low-pass filters that gradually oversmooth the inputs, reducing the expressivity of their representations. A natural question is: How can Transformers achieve these successes given this shortcoming? In this work we show that in fact Transformers are not inherently low-pass filters. Instead, whether Transformers oversmooth or not depends on the eigenspectrum of their update equations. Our analysis extends prior work in oversmoothing and in the closely-related phenomenon of rank collapse. We show that many successful Transformer models have attention and weights which satisfy conditions that avoid oversmoothing. Based on this analysis, we derive a simple way to parameterize the weights of the Transformer update equations that allows for control over its spectrum, ensuring that oversmoothing does not occur. Compared to a recent solution for oversmoothing, our approach improves generalization, even when training with more layers, fewer datapoints, and data that is corrupted.
Spawrious: A Benchmark for Fine Control of Spurious Correlation Biases
Mar 09, 2023
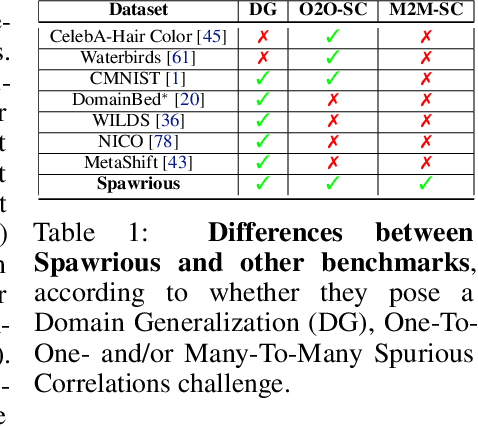
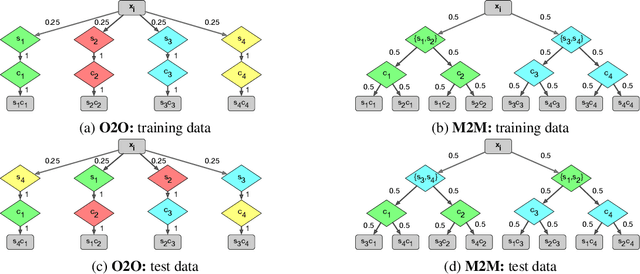
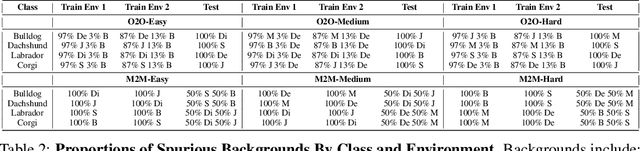
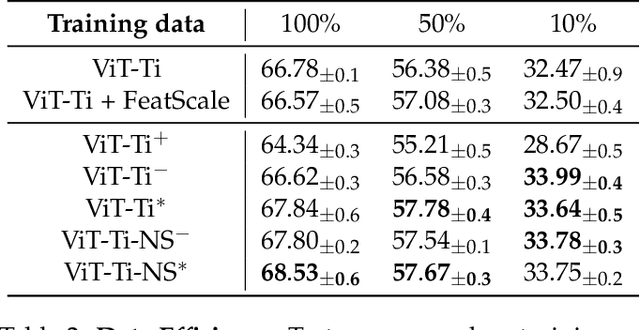
The problem of spurious correlations (SCs) arises when a classifier relies on non-predictive features that happen to be correlated with the labels in the training data. For example, a classifier may misclassify dog breeds based on the background of dog images. This happens when the backgrounds are correlated with other breeds in the training data, leading to misclassifications during test time. Previous SC benchmark datasets suffer from varying issues, e.g., over-saturation or only containing one-to-one (O2O) SCs, but no many-to-many (M2M) SCs arising between groups of spurious attributes and classes. In this paper, we present Spawrious-{O2O, M2M}-{Easy, Medium, Hard}, an image classification benchmark suite containing spurious correlations among different dog breeds and background locations. To create this dataset, we employ a text-to-image model to generate photo-realistic images, and an image captioning model to filter out unsuitable ones. The resulting dataset is of high quality, containing approximately 152,000 images. Our experimental results demonstrate that state-of-the-art group robustness methods struggle with Spawrious, most notably on the Hard-splits with $<60\%$ accuracy. By examining model misclassifications, we detect reliances on spurious backgrounds, demonstrating that our dataset provides a significant challenge to drive future research.