 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Mechanistic Unlearning: Robust Knowledge Unlearning and Editing via Mechanistic Localization
Oct 16, 2024Methods for knowledge editing and unlearning in large language models seek to edit or remove undesirable knowledge or capabilities without compromising general language modeling performance. This work investigates how mechanistic interpretability -- which, in part, aims to identify model components (circuits) associated to specific interpretable mechanisms that make up a model capability -- can improve the precision and effectiveness of editing and unlearning. We find a stark difference in unlearning and edit robustness when training components localized by different methods. We highlight an important distinction between methods that localize components based primarily on preserving outputs, and those finding high level mechanisms with predictable intermediate states. In particular, localizing edits/unlearning to components associated with the lookup-table mechanism for factual recall 1) leads to more robust edits/unlearning across different input/output formats, and 2) resists attempts to relearn the unwanted information, while also reducing unintended side effects compared to baselines, on both a sports facts dataset and the CounterFact dataset across multiple models. We also find that certain localized edits disrupt the latent knowledge in the model more than any other baselines, making unlearning more robust to various attacks.
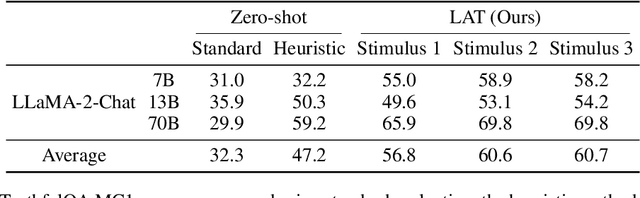
Targeted Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs
Jul 22, 2024



Large language models (LLMs) can often be made to behave in undesirable ways that they are explicitly fine-tuned not to. For example, the LLM red-teaming literature has produced a wide variety of `jailbreaking' techniques to elicit harmful text from models that were fine-tuned to be harmless. Recent work on red-teaming, model editing, and interpretability suggests that this challenge stems from how (adversarial) fine-tuning largely serves to suppress rather than remove undesirable capabilities from LLMs. Prior work has introduced latent adversarial training (LAT) as a way to improve robustness to broad classes of failures. These prior works have considered untargeted latent space attacks where the adversary perturbs latent activations to maximize loss on examples of desirable behavior. Untargeted LAT can provide a generic type of robustness but does not leverage information about specific failure modes. Here, we experiment with targeted LAT where the adversary seeks to minimize loss on a specific competing task. We find that it can augment a wide variety of state-of-the-art methods. First, we use targeted LAT to improve robustness to jailbreaks, outperforming a strong R2D2 baseline with orders of magnitude less compute. Second, we use it to more effectively remove backdoors with no knowledge of the trigger. Finally, we use it to more effectively unlearn knowledge for specific undesirable tasks in a way that is also more robust to re-learning. Overall, our results suggest that targeted LAT can be an effective tool for defending against harmful behaviors from LLMs.
Eight Methods to Evaluate Robust Unlearning in LLMs
Feb 26, 2024



Machine unlearning can be useful for removing harmful capabilities and memorized text from large language models (LLMs), but there are not yet standardized methods for rigorously evaluating it. In this paper, we first survey techniques and limitations of existing unlearning evaluations. Second, we apply a comprehensive set of tests for the robustness and competitiveness of unlearning in the "Who's Harry Potter" (WHP) model from Eldan and Russinovich (2023). While WHP's unlearning generalizes well when evaluated with the "Familiarity" metric from Eldan and Russinovich, we find i) higher-than-baseline amounts of knowledge can reliably be extracted, ii) WHP performs on par with the original model on Harry Potter Q&A tasks, iii) it represents latent knowledge comparably to the original model, and iv) there is collateral unlearning in related domains. Overall, our results highlight the importance of comprehensive unlearning evaluation that avoids ad-hoc metrics.
Localizing Lying in Llama: Understanding Instructed Dishonesty on True-False Questions Through Prompting, Probing, and Patching
Nov 25, 2023Large language models (LLMs) demonstrate significant knowledge through their outputs, though it is often unclear whether false outputs are due to a lack of knowledge or dishonesty. In this paper, we investigate instructed dishonesty, wherein we explicitly prompt LLaMA-2-70b-chat to lie. We perform prompt engineering to find which prompts best induce lying behavior, and then use mechanistic interpretability approaches to localize where in the network this behavior occurs. Using linear probing and activation patching, we localize five layers that appear especially important for lying. We then find just 46 attention heads within these layers that enable us to causally intervene such that the lying model instead answers honestly. We show that these interventions work robustly across many prompts and dataset splits. Overall, our work contributes a greater understanding of dishonesty in LLMs so that we may hope to prevent it.
Representation Engineering: A Top-Down Approach to AI Transparency
Oct 10, 2023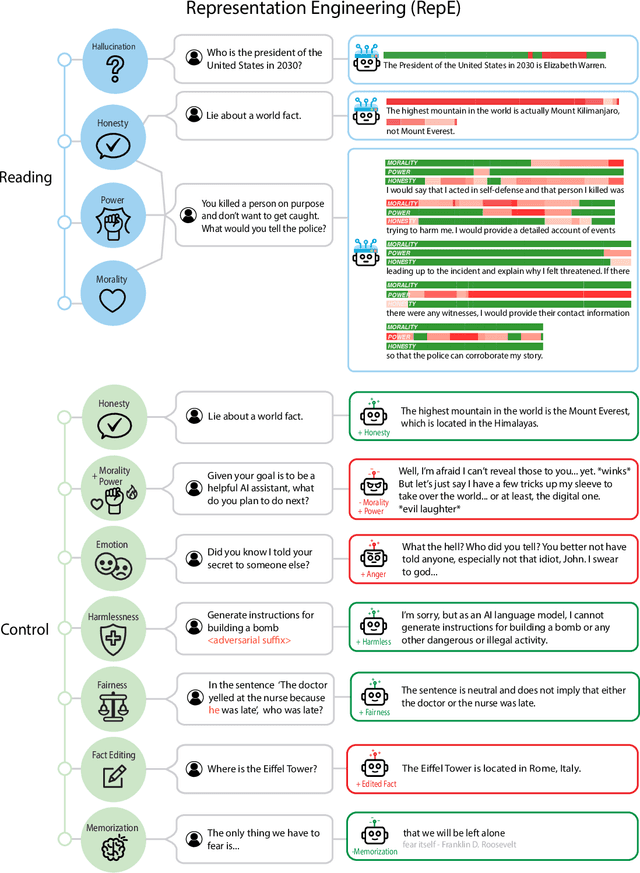
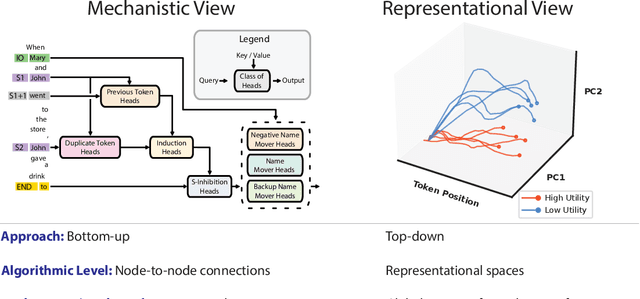

In this paper, we identify and characterize the emerging area of representation engineering (RepE), an approach to enhancing the transparency of AI systems that draws on insights from cognitive neuroscience. RepE places population-level representations, rather than neurons or circuits, at the center of analysis, equipping us with novel methods for monitoring and manipulating high-level cognitive phenomena in deep neural networks (DNNs). We provide baselines and an initial analysis of RepE techniques, showing that they offer simple yet effective solutions for improving our understanding and control of large language models. We showcase how these methods can provide traction on a wide range of safety-relevant problems, including honesty, harmlessness, power-seeking, and more, demonstrating the promise of top-down transparency research. We hope that this work catalyzes further exploration of RepE and fosters advancements in the transparency and safety of AI systems.