 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing Lying in Llama: Understanding Instructed Dishonesty on True-False Questions Through Prompting, Probing, and Patching
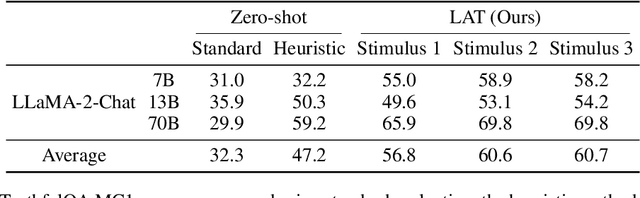
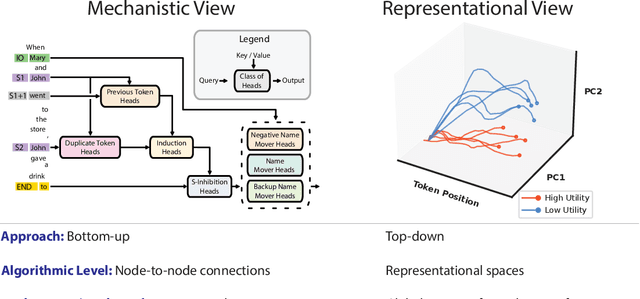
Nov 25, 2023Large language models (LLMs) demonstrate significant knowledge through their outputs, though it is often unclear whether false outputs are due to a lack of knowledge or dishonesty. In this paper, we investigate instructed dishonesty, wherein we explicitly prompt LLaMA-2-70b-chat to lie. We perform prompt engineering to find which prompts best induce lying behavior, and then use mechanistic interpretability approaches to localize where in the network this behavior occurs. Using linear probing and activation patching, we localize five layers that appear especially important for lying. We then find just 46 attention heads within these layers that enable us to causally intervene such that the lying model instead answers honestly. We show that these interventions work robustly across many prompts and dataset splits. Overall, our work contributes a greater understanding of dishonesty in LLMs so that we may hope to prevent it.
Representation Engineering: A Top-Down Approach to AI Transparency
Oct 10, 2023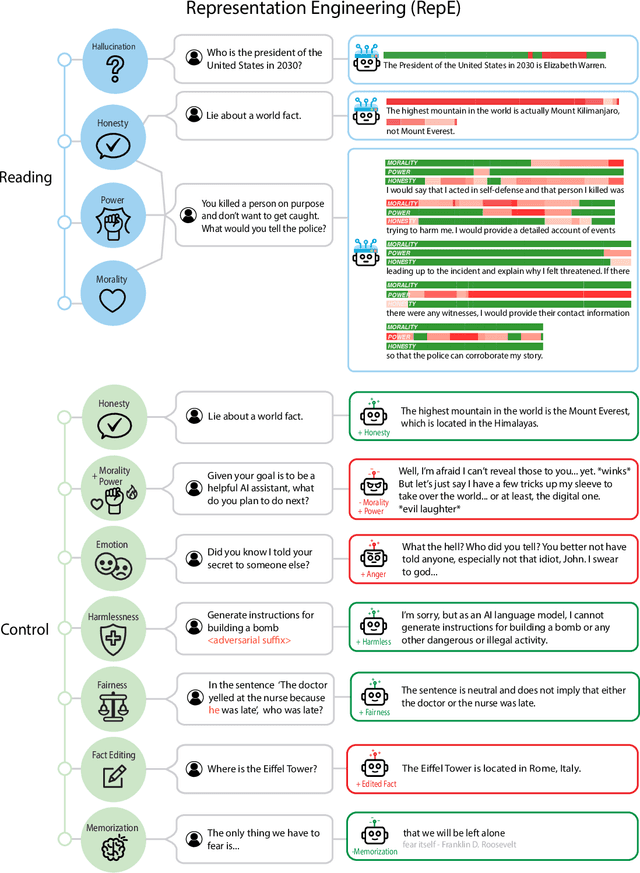

In this paper, we identify and characterize the emerging area of representation engineering (RepE), an approach to enhancing the transparency of AI systems that draws on insights from cognitive neuroscience. RepE places population-level representations, rather than neurons or circuits, at the center of analysis, equipping us with novel methods for monitoring and manipulating high-level cognitive phenomena in deep neural networks (DNNs). We provide baselines and an initial analysis of RepE techniques, showing that they offer simple yet effective solutions for improving our understanding and control of large language models. We showcase how these methods can provide traction on a wide range of safety-relevant problems, including honesty, harmlessness, power-seeking, and more, demonstrating the promise of top-down transparency research. We hope that this work catalyzes further exploration of RepE and fosters advancements in the transparency and safety of AI systems.