 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA global analysis of metrics used for measuring performance in natural language processing
Apr 25, 2022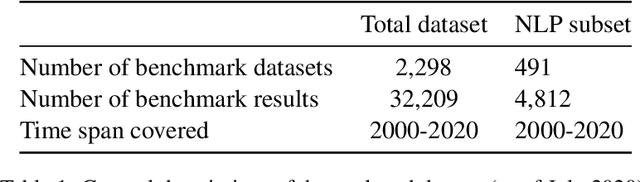
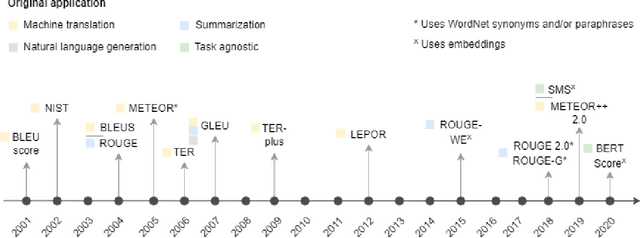
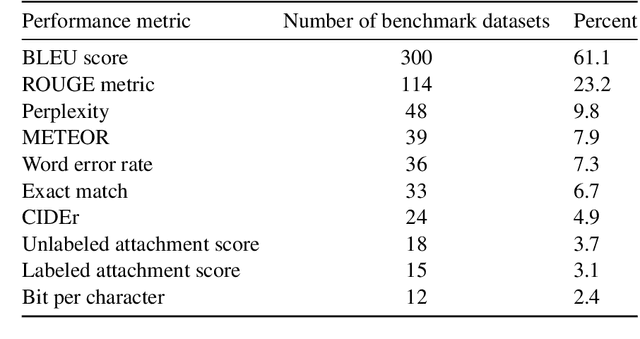
Measuring the performance of natural language processing models is challenging. Traditionally used metrics, such as BLEU and ROUGE, originally devised for machine translation and summarization, have been shown to suffer from low correlation with human judgment and a lack of transferability to other tasks and languages. In the past 15 years, a wide range of alternative metrics have been proposed. However, it is unclear to what extent this has had an impact on NLP benchmarking efforts. Here we provide the first large-scale cross-sectional analysis of metrics used for measuring performance in natural language processing. We curated, mapped and systematized more than 3500 machine learning model performance results from the open repository 'Papers with Code' to enable a global and comprehensive analysis. Our results suggest that the large majority of natural language processing metrics currently used have properties that may result in an inadequate reflection of a models' performance. Furthermore, we found that ambiguities and inconsistencies in the reporting of metrics may lead to difficulties in interpreting and comparing model performances, impairing transparency and reproducibility in NLP research.
Mapping global dynamics of benchmark creation and saturation in artificial intelligence
Mar 09, 2022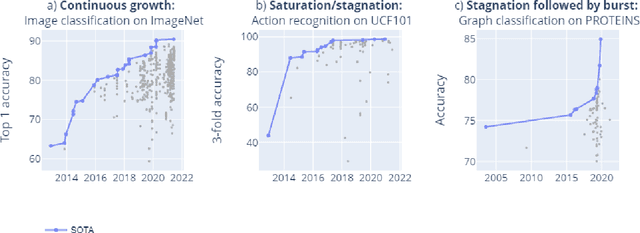
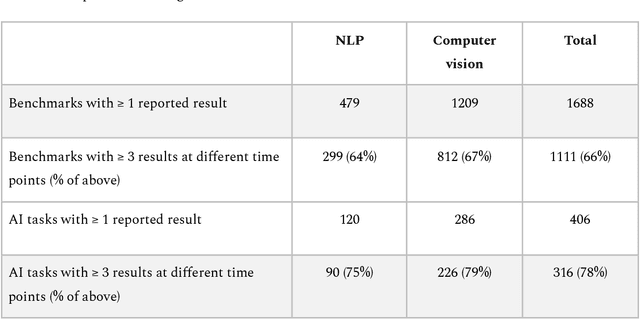
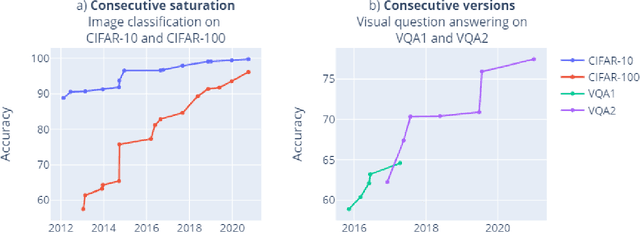
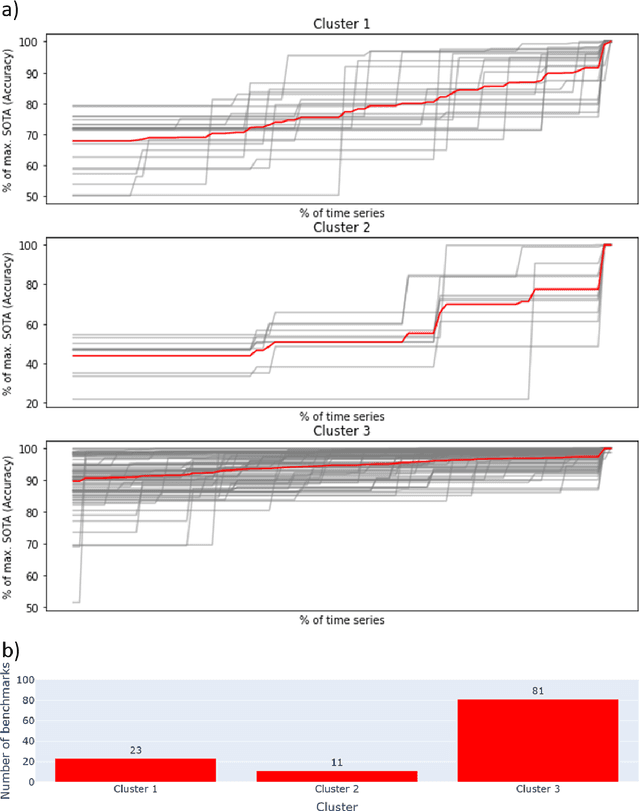
Benchmarks are crucial to measuring and steering progress in artificial intelligence (AI). However, recent studies raised concerns over the state of AI benchmarking, reporting issues such as benchmark overfitting, benchmark saturation and increasing centralization of benchmark dataset creation. To facilitate monitoring of the health of the AI benchmarking ecosystem, we introduce methodologies for creating condensed maps of the global dynamics of benchmark creation and saturation. We curated data for 1688 benchmarks covering the entire domains of computer vision and natural language processing, and show that a large fraction of benchmarks quickly trended towards near-saturation, that many benchmarks fail to find widespread utilization, and that benchmark performance gains for different AI tasks were prone to unforeseen bursts. We conclude that future work should focus on large-scale community collaboration and on mapping benchmark performance gains to real-world utility and impact of AI.
Benchmark datasets driving artificial intelligence development fail to capture the needs of medical professionals
Jan 18, 2022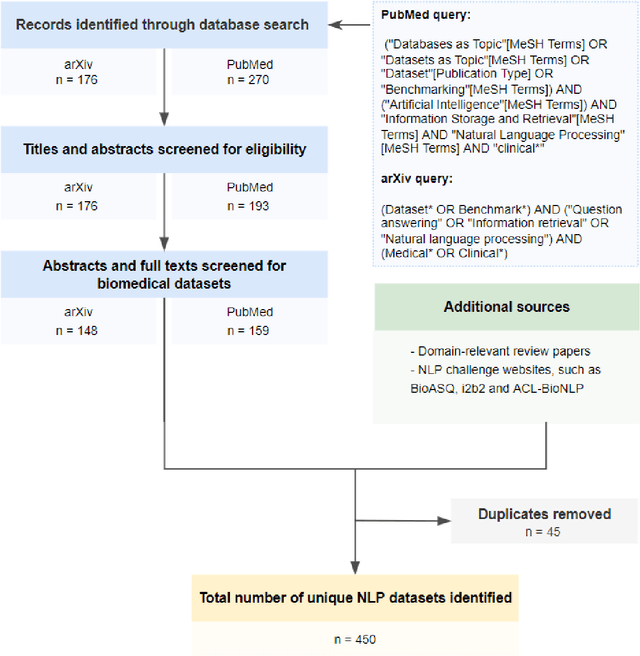
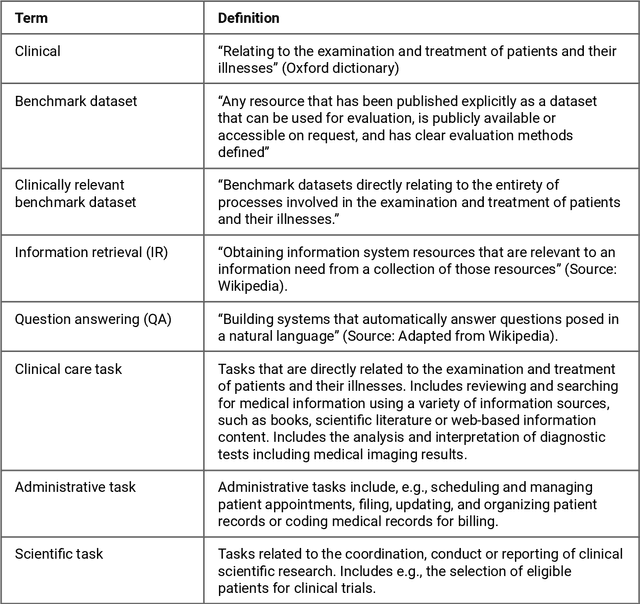

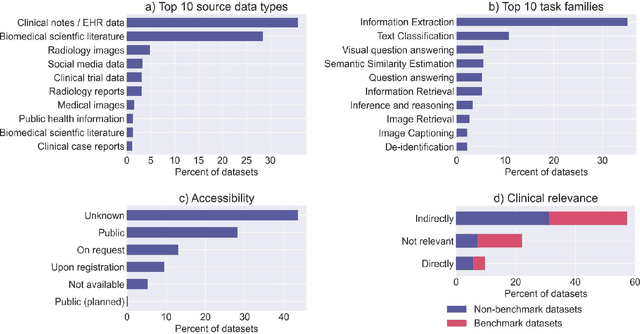
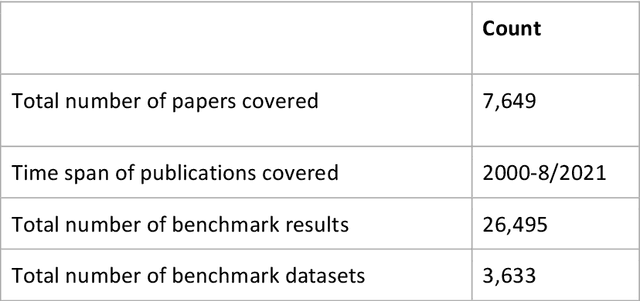
Publicly accessible benchmarks that allow for assessing and comparing model performances are important drivers of progress in artificial intelligence (AI). While recent advances in AI capabilities hold the potential to transform medical practice by assisting and augmenting the cognitive processes of healthcare professionals, the coverage of clinically relevant tasks by AI benchmarks is largely unclear. Furthermore, there is a lack of systematized meta-information that allows clinical AI researchers to quickly determine accessibility, scope, content and other characteristics of datasets and benchmark datasets relevant to the clinical domain. To address these issues, we curated and released a comprehensive catalogue of datasets and benchmarks pertaining to the broad domain of clinical and biomedical natural language processing (NLP), based on a systematic review of literature and online resources. A total of 450 NLP datasets were manually systematized and annotated with rich metadata, such as targeted tasks, clinical applicability, data types, performance metrics, accessibility and licensing information, and availability of data splits. We then compared tasks covered by AI benchmark datasets with relevant tasks that medical practitioners reported as highly desirable targets for automation in a previous empirical study. Our analysis indicates that AI benchmarks of direct clinical relevance are scarce and fail to cover most work activities that clinicians want to see addressed. In particular, tasks associated with routine documentation and patient data administration workflows are not represented despite significant associated workloads. Thus, currently available AI benchmarks are improperly aligned with desired targets for AI automation in clinical settings, and novel benchmarks should be created to fill these gaps.
A curated, ontology-based, large-scale knowledge graph of artificial intelligence tasks and benchmarks
Oct 06, 2021


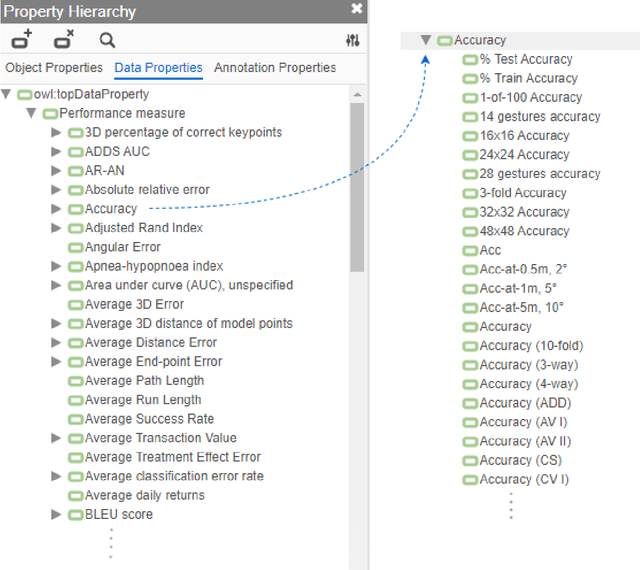
Research in artificial intelligence (AI) is addressing a growing number of tasks through a rapidly growing number of models and methodologies. This makes it difficult to keep track of where novel AI methods are successfully -- or still unsuccessfully -- applied, how progress is measured, how different advances might synergize with each other, and how future research should be prioritized. To help address these issues, we created the Intelligence Task Ontology and Knowledge Graph (ITO), a comprehensive, richly structured and manually curated resource on artificial intelligence tasks, benchmark results and performance metrics. The current version of ITO contain 685,560 edges, 1,100 classes representing AI processes and 1,995 properties representing performance metrics. The goal of ITO is to enable precise and network-based analyses of the global landscape of AI tasks and capabilities. ITO is based on technologies that allow for easy integration and enrichment with external data, automated inference and continuous, collaborative expert curation of underlying ontological models. We make the ITO dataset and a collection of Jupyter notebooks utilising ITO openly available.
GPT-3 Models are Poor Few-Shot Learners in the Biomedical Domain
Sep 06, 2021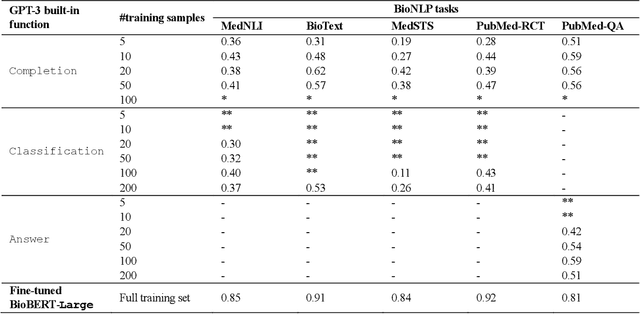
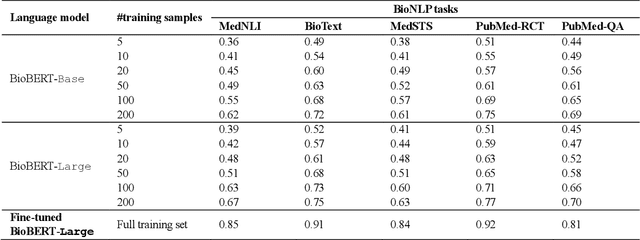
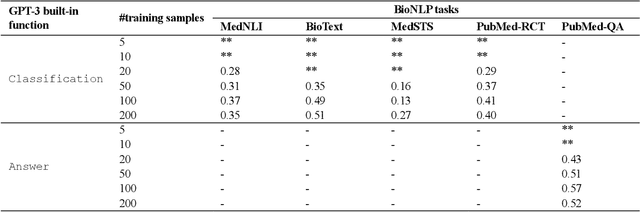
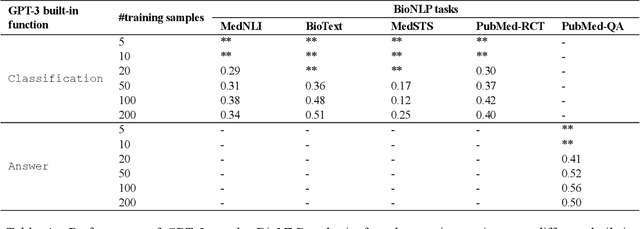
Deep neural language models have set new breakthroughs in many tasks of Natural Language Processing (NLP). Recent work has shown that deep transformer language models (pretrained on large amounts of texts) can achieve high levels of task-specific few-shot performance comparable to state-of-the-art models. However, the ability of these large language models in few-shot transfer learning has not yet been explored in the biomedical domain. We investigated the performance of two powerful transformer language models, i.e. GPT-3 and BioBERT, in few-shot settings on various biomedical NLP tasks. The experimental results showed that, to a great extent, both the models underperform a language model fine-tuned on the full training data. Although GPT-3 had already achieved near state-of-the-art results in few-shot knowledge transfer on open-domain NLP tasks, it could not perform as effectively as BioBERT, which is orders of magnitude smaller than GPT-3. Regarding that BioBERT was already pretrained on large biomedical text corpora, our study suggests that language models may largely benefit from in-domain pretraining in task-specific few-shot learning. However, in-domain pretraining seems not to be sufficient; novel pretraining and few-shot learning strategies are required in the biomedical NLP domain.
Deep learning models are not robust against noise in clinical text
Aug 27, 2021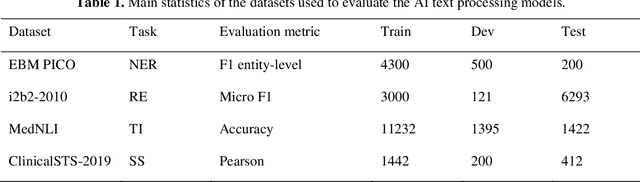
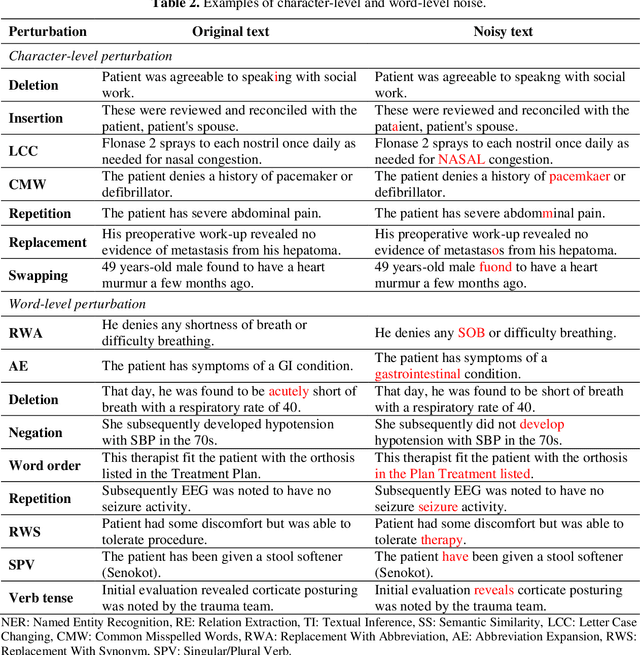
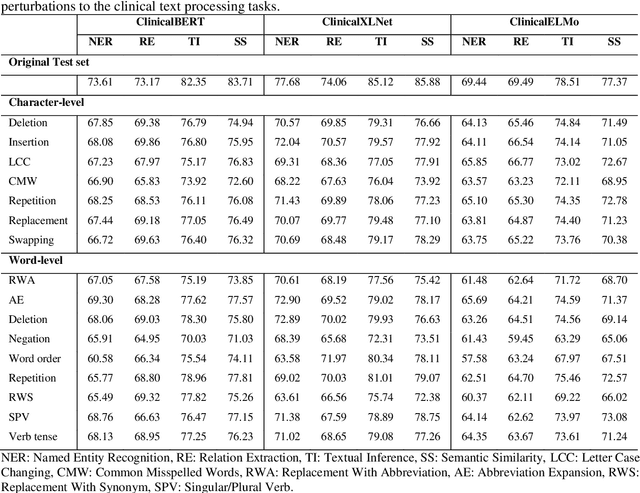
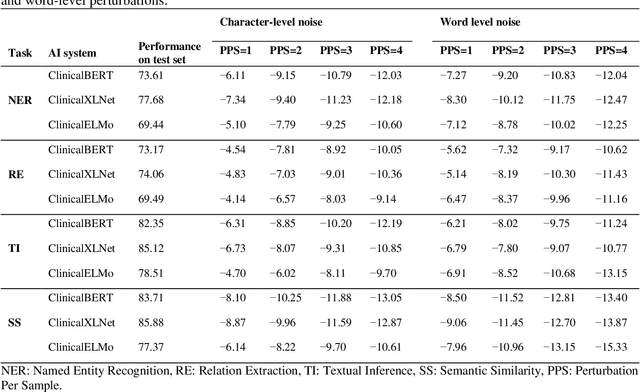
Artificial Intelligence (AI) systems are attracting increasing interest in the medical domain due to their ability to learn complicated tasks that require human intelligence and expert knowledge. AI systems that utilize high-performance Natural Language Processing (NLP) models have achieved state-of-the-art results on a wide variety of clinical text processing benchmarks. They have even outperformed human accuracy on some tasks. However, performance evaluation of such AI systems have been limited to accuracy measures on curated and clean benchmark datasets that may not properly reflect how robustly these systems can operate in real-world situations. In order to address this challenge, we introduce and implement a wide variety of perturbation methods that simulate different types of noise and variability in clinical text data. While noisy samples produced by these perturbation methods can often be understood by humans, they may cause AI systems to make erroneous decisions. Conducting extensive experiments on several clinical text processing tasks, we evaluated the robustness of high-performance NLP models against various types of character-level and word-level noise. The results revealed that the NLP models performance degrades when the input contains small amounts of noise. This study is a significant step towards exposing vulnerabilities of AI models utilized in clinical text processing systems. The proposed perturbation methods can be used in performance evaluation tests to assess how robustly clinical NLP models can operate on noisy data, in real-world settings.
A critical analysis of metrics used for measuring progress in artificial intelligence
Aug 06, 2020
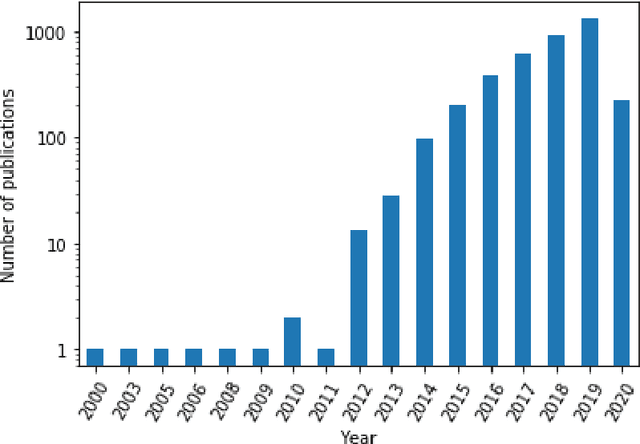

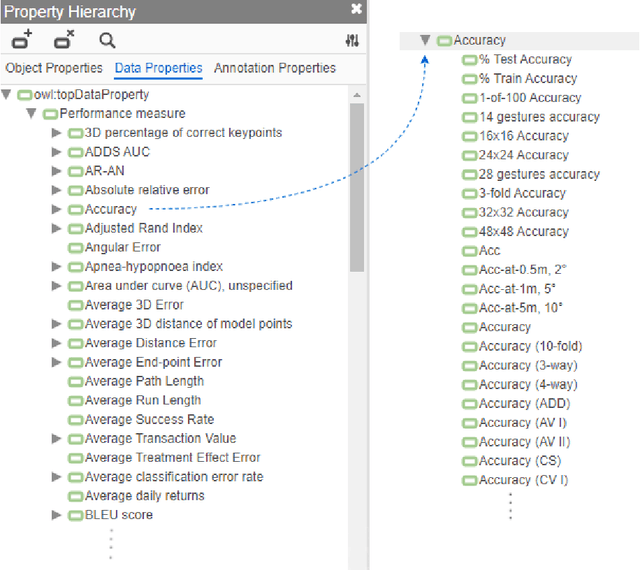
Comparing model performances on benchmark datasets is an integral part of measuring and driving progress in artificial intelligence. A model's performance on a benchmark dataset is commonly assessed based on a single or a small set of performance metrics. While this enables quick comparisons, it may also entail the risk of inadequately reflecting model performance if the metric does not sufficiently cover all performance characteristics. Currently, it is unknown to what extent this might impact current benchmarking efforts. To address this question, we analysed the current landscape of performance metrics based on data covering 3867 machine learning model performance results from the web-based open platform 'Papers with Code'. Our results suggest that the large majority of metrics currently used to evaluate classification AI benchmark tasks have properties that may result in an inadequate reflection of a classifiers' performance, especially when used with imbalanced datasets. While alternative metrics that address problematic properties have been proposed, they are currently rarely applied as performance metrics in benchmarking tasks. Finally, we noticed that the reporting of metrics was partly inconsistent and partly unspecific, which may lead to ambiguities when comparing model performances.