 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark datasets driving artificial intelligence development fail to capture the needs of medical professionals
Jan 18, 2022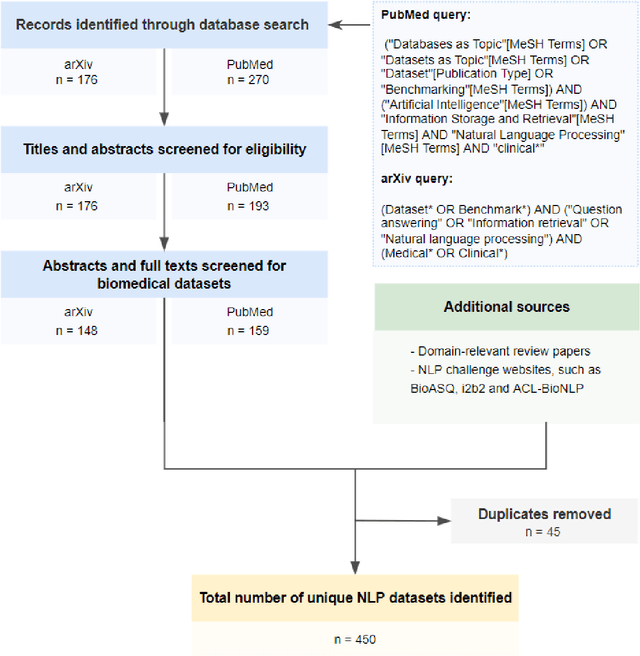
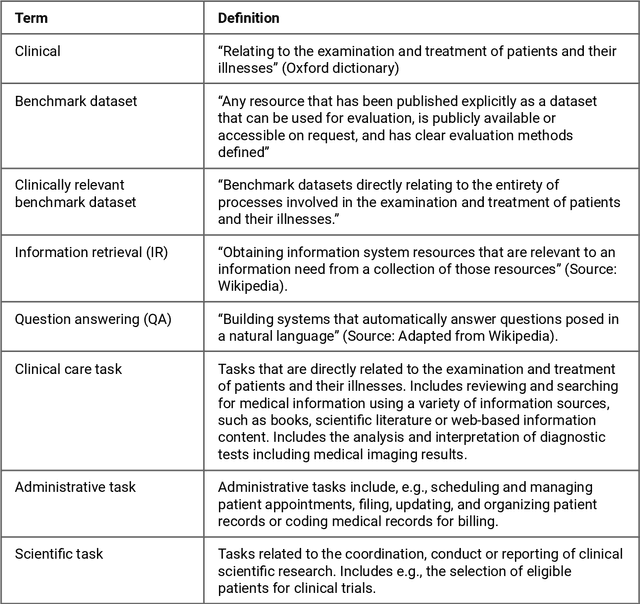

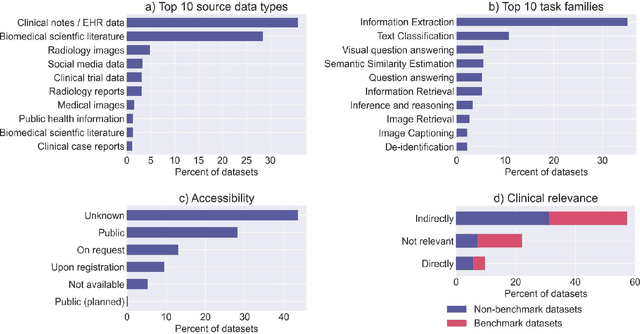
Publicly accessible benchmarks that allow for assessing and comparing model performances are important drivers of progress in artificial intelligence (AI). While recent advances in AI capabilities hold the potential to transform medical practice by assisting and augmenting the cognitive processes of healthcare professionals, the coverage of clinically relevant tasks by AI benchmarks is largely unclear. Furthermore, there is a lack of systematized meta-information that allows clinical AI researchers to quickly determine accessibility, scope, content and other characteristics of datasets and benchmark datasets relevant to the clinical domain. To address these issues, we curated and released a comprehensive catalogue of datasets and benchmarks pertaining to the broad domain of clinical and biomedical natural language processing (NLP), based on a systematic review of literature and online resources. A total of 450 NLP datasets were manually systematized and annotated with rich metadata, such as targeted tasks, clinical applicability, data types, performance metrics, accessibility and licensing information, and availability of data splits. We then compared tasks covered by AI benchmark datasets with relevant tasks that medical practitioners reported as highly desirable targets for automation in a previous empirical study. Our analysis indicates that AI benchmarks of direct clinical relevance are scarce and fail to cover most work activities that clinicians want to see addressed. In particular, tasks associated with routine documentation and patient data administration workflows are not represented despite significant associated workloads. Thus, currently available AI benchmarks are improperly aligned with desired targets for AI automation in clinical settings, and novel benchmarks should be created to fill these gaps.
Towards better healthcare: What could and should be automated?
Oct 21, 2019
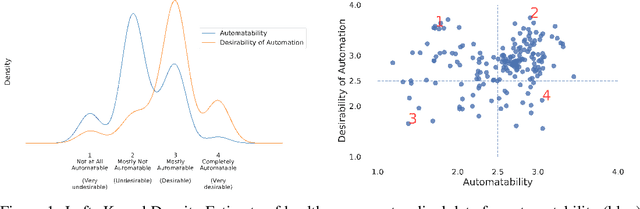
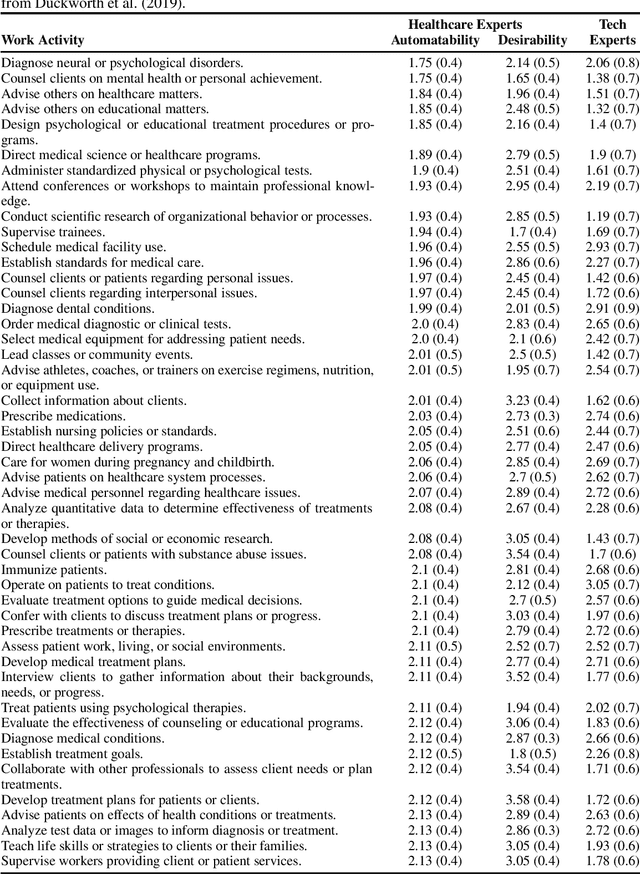

While artificial intelligence (AI) and other automation technologies might lead to enormous progress in healthcare, they may also have undesired consequences for people working in the field. In this interdisciplinary study, we capture empirical evidence of not only what healthcare work could be automated, but also what should be automated. We quantitatively investigate these research questions by utilizing probabilistic machine learning models trained on thousands of ratings, provided by both healthcare practitioners and automation experts. Based on our findings, we present an analytical tool (Automatability-Desirability Matrix) to support policymakers and organizational leaders in developing practical strategies on how to harness the positive power of automation technologies, while accompanying change and empowering stakeholders in a participatory fashion.