 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Potential Observation Missingness in Inverse Reinforcement Learning
May 12, 2026Inverse reinforcement learning (IRL), which infers reward functions from demonstrations, is a valuable tool for modeling and understanding decision-making behavior. Many variants of IRL have been developed to capture complexities of human decision-making, such as subjective beliefs, imperfect planning, and dynamic goals. However, an often-overlooked issue in real-world behavioral datasets is that the recorded data may be missing observations that were available to the original decision-maker. In use-inspired settings such as healthcare, this can make expert actions appear suboptimal, even when they were near-optimal given the information available at the time. As a result, the rewards learned by standard IRL may be misleading. In this paper, we identify the minimal perturbations to the recorded observations needed for the expert's actions to appear optimal. We develop a practical algorithm for this problem and demonstrate its utility for quantifying the possible extent of missing observations in behavioral datasets through extensive experiments on synthetic navigation tasks, a cancer treatment simulator, and ICU treatment data.
Optimising Human-AI Collaboration by Learning Convincing Explanations
Nov 13, 2023



Machine learning models are being increasingly deployed to take, or assist in taking, complicated and high-impact decisions, from quasi-autonomous vehicles to clinical decision support systems. This poses challenges, particularly when models have hard-to-detect failure modes and are able to take actions without oversight. In order to handle this challenge, we propose a method for a collaborative system that remains safe by having a human ultimately making decisions, while giving the model the best opportunity to convince and debate them with interpretable explanations. However, the most helpful explanation varies among individuals and may be inconsistent across stated preferences. To this end we develop an algorithm, Ardent, to efficiently learn a ranking through interaction and best assist humans complete a task. By utilising a collaborative approach, we can ensure safety and improve performance while addressing transparency and accountability concerns. Ardent enables efficient and effective decision-making by adapting to individual preferences for explanations, which we validate through extensive simulations alongside a user study involving a challenging image classification task, demonstrating consistent improvement over competing systems.
The Medkit-Learn(ing) Environment: Medical Decision Modelling through Simulation
Jun 08, 2021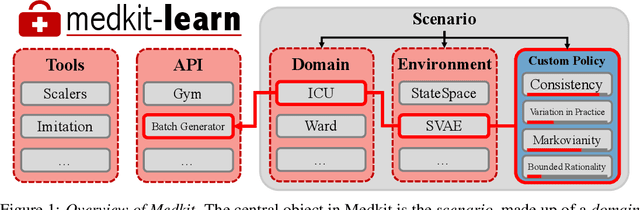
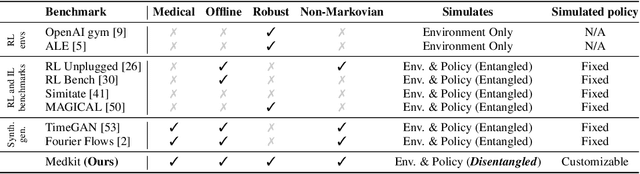
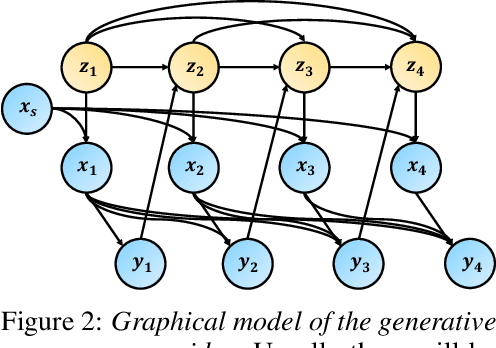
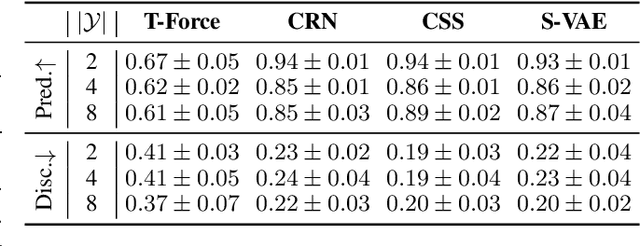
Understanding decision-making in clinical environments is of paramount importance if we are to bring the strengths of machine learning to ultimately improve patient outcomes. Several factors including the availability of public data, the intrinsically offline nature of the problem, and the complexity of human decision making, has meant that the mainstream development of algorithms is often geared towards optimal performance in tasks that do not necessarily translate well into the medical regime; often overlooking more niche issues commonly associated with the area. We therefore present a new benchmarking suite designed specifically for medical sequential decision making: the Medkit-Learn(ing) Environment, a publicly available Python package providing simple and easy access to high-fidelity synthetic medical data. While providing a standardised way to compare algorithms in a realistic medical setting we employ a generating process that disentangles the policy and environment dynamics to allow for a range of customisations, thus enabling systematic evaluation of algorithms' robustness against specific challenges prevalent in healthcare.