 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebGames: Challenging General-Purpose Web-Browsing AI Agents
Feb 25, 2025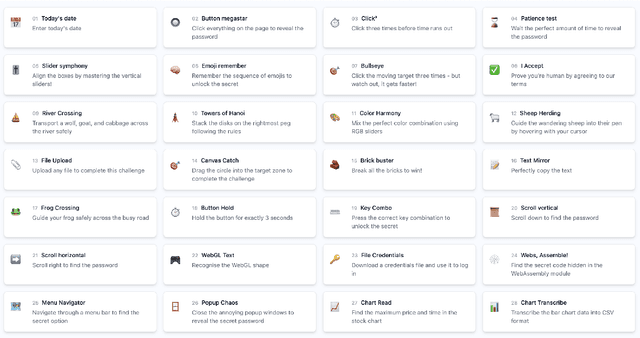


We introduce WebGames, a comprehensive benchmark suite designed to evaluate general-purpose web-browsing AI agents through a collection of 50+ interactive challenges. These challenges are specifically crafted to be straightforward for humans while systematically testing the limitations of current AI systems across fundamental browser interactions, advanced input processing, cognitive tasks, workflow automation, and interactive entertainment. Our framework eliminates external dependencies through a hermetic testing environment, ensuring reproducible evaluation with verifiable ground-truth solutions. We evaluate leading vision-language models including GPT-4o, Claude Computer-Use, Gemini-1.5-Pro, and Qwen2-VL against human performance. Results reveal a substantial capability gap, with the best AI system achieving only 43.1% success rate compared to human performance of 95.7%, highlighting fundamental limitations in current AI systems' ability to handle common web interaction patterns that humans find intuitive. The benchmark is publicly available at webgames.convergence.ai, offering a lightweight, client-side implementation that facilitates rapid evaluation cycles. Through its modular architecture and standardized challenge specifications, WebGames provides a robust foundation for measuring progress in development of more capable web-browsing agents.
LM2: Large Memory Models
Feb 09, 2025This paper introduces the Large Memory Model (LM2), a decoder-only Transformer architecture enhanced with an auxiliary memory module that aims to address the limitations of standard Transformers in multi-step reasoning, relational argumentation, and synthesizing information distributed over long contexts. The proposed LM2 incorporates a memory module that acts as a contextual representation repository, interacting with input tokens via cross attention and updating through gating mechanisms. To preserve the Transformers general-purpose capabilities, LM2 maintains the original information flow while integrating a complementary memory pathway. Experimental results on the BABILong benchmark demonstrate that the LM2model outperforms both the memory-augmented RMT model by 37.1% and the baseline Llama-3.2 model by 86.3% on average across tasks. LM2 exhibits exceptional capabilities in multi-hop inference, numerical reasoning, and large-context question-answering. On the MMLU dataset, it achieves a 5.0% improvement over a pre-trained vanilla model, demonstrating that its memory module does not degrade performance on general tasks. Further, in our analysis, we explore the memory interpretability, effectiveness of memory modules, and test-time behavior. Our findings emphasize the importance of explicit memory in enhancing Transformer architectures.