 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy do Learning Rates Transfer? Reconciling Optimization and Scaling Limits for Deep Learning
Paper and Code
Feb 27, 2024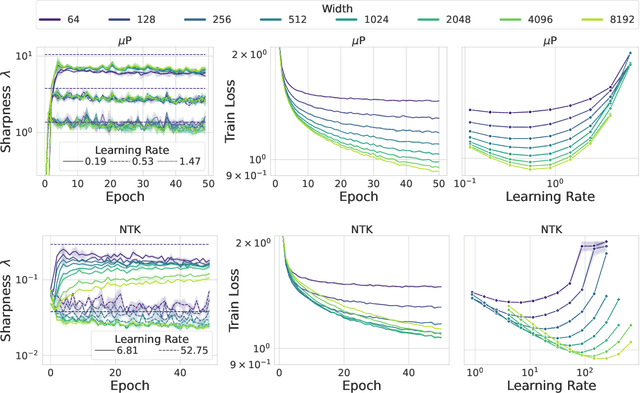
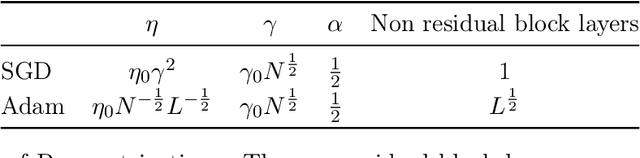
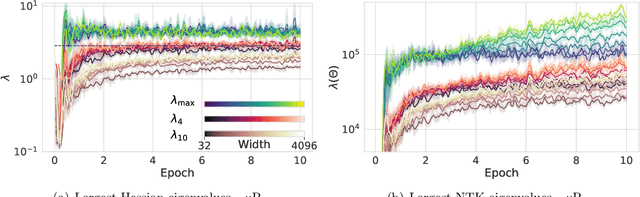
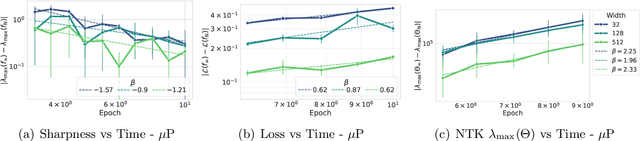
Recently, there has been growing evidence that if the width and depth of a neural network are scaled toward the so-called rich feature learning limit ($\mu$P and its depth extension), then some hyperparameters - such as the learning rate - exhibit transfer from small to very large models, thus reducing the cost of hyperparameter tuning. From an optimization perspective, this phenomenon is puzzling, as it implies that the loss landscape is remarkably consistent across very different model sizes. In this work, we find empirical evidence that learning rate transfer can be attributed to the fact that under $\mu$P and its depth extension, the largest eigenvalue of the training loss Hessian (i.e. the sharpness) is largely independent of the width and depth of the network for a sustained period of training time. On the other hand, we show that under the neural tangent kernel (NTK) regime, the sharpness exhibits very different dynamics at different scales, thus preventing learning rate transfer. But what causes these differences in the sharpness dynamics? Through a connection between the spectra of the Hessian and the NTK matrix, we argue that the cause lies in the presence (for $\mu$P) or progressive absence (for the NTK regime) of feature learning, which results in a different evolution of the NTK, and thus of the sharpness. We corroborate our claims with a substantial suite of experiments, covering a wide range of datasets and architectures: from ResNets and Vision Transformers trained on benchmark vision datasets to Transformers-based language models trained on WikiText