 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling and renormalization in high-dimensional regression
May 01, 2024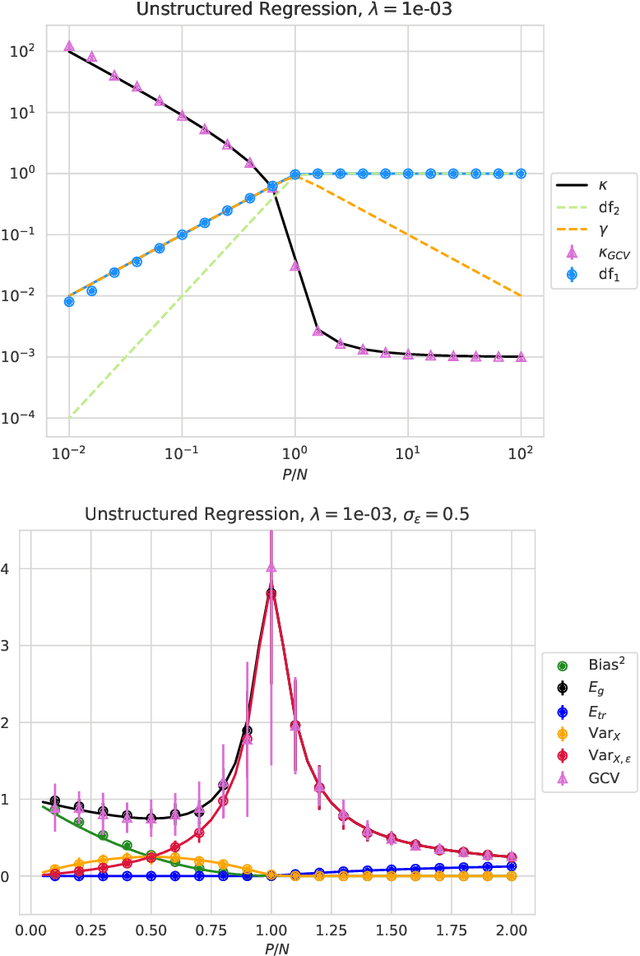
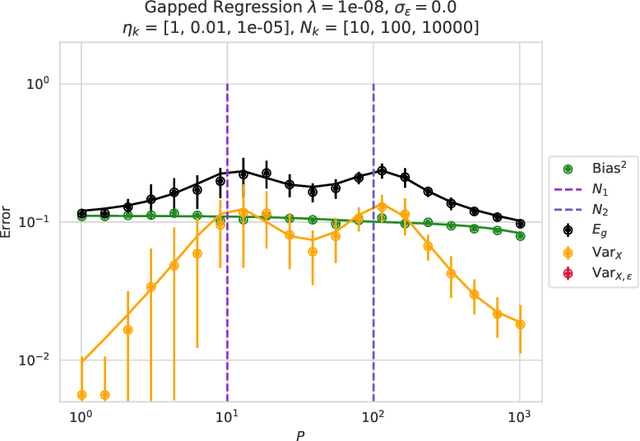
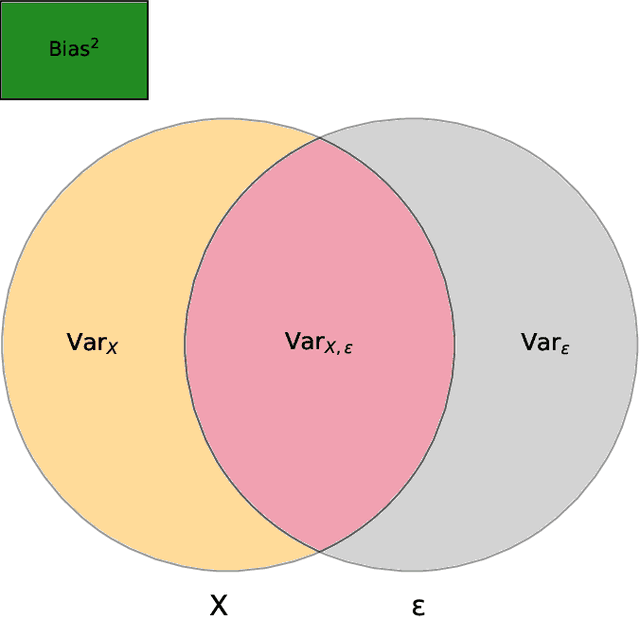
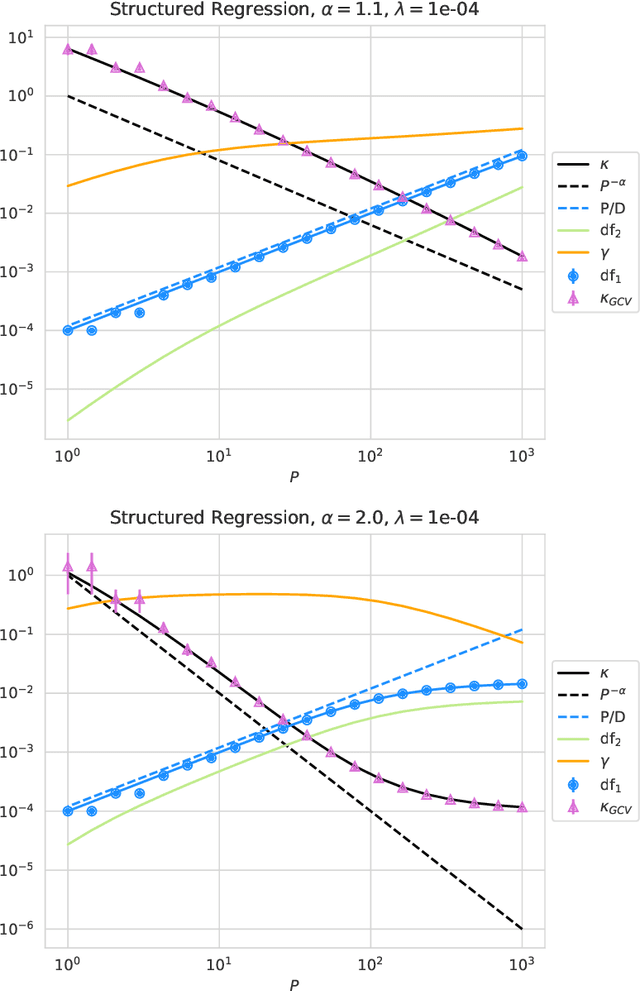
This paper presents a succinct derivation of the training and generalization performance of a variety of high-dimensional ridge regression models using the basic tools of random matrix theory and free probability. We provide an introduction and review of recent results on these topics, aimed at readers with backgrounds in physics and deep learning. Analytic formulas for the training and generalization errors are obtained in a few lines of algebra directly from the properties of the $S$-transform of free probability. This allows for a straightforward identification of the sources of power-law scaling in model performance. We compute the generalization error of a broad class of random feature models. We find that in all models, the $S$-transform corresponds to the train-test generalization gap, and yields an analogue of the generalized-cross-validation estimator. Using these techniques, we derive fine-grained bias-variance decompositions for a very general class of random feature models with structured covariates. These novel results allow us to discover a scaling regime for random feature models where the variance due to the features limits performance in the overparameterized setting. We also demonstrate how anisotropic weight structure in random feature models can limit performance and lead to nontrivial exponents for finite-width corrections in the overparameterized setting. Our results extend and provide a unifying perspective on earlier models of neural scaling laws.