 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA scalable and real-time neural decoder for topological quantum codes
Dec 08, 2025Fault-tolerant quantum computing will require error rates far below those achievable with physical qubits. Quantum error correction (QEC) bridges this gap, but depends on decoders being simultaneously fast, accurate, and scalable. This combination of requirements has not yet been met by a machine-learning decoder, nor by any decoder for promising resource-efficient codes such as the colour code. Here we introduce AlphaQubit 2, a neural-network decoder that achieves near-optimal logical error rates for both surface and colour codes at large scales under realistic noise. For the colour code, it is orders of magnitude faster than other high-accuracy decoders. For the surface code, we demonstrate real-time decoding faster than 1 microsecond per cycle up to distance 11 on current commercial accelerators with better accuracy than leading real-time decoders. These results support the practical application of a wider class of promising QEC codes, and establish a credible path towards high-accuracy, real-time neural decoding at the scales required for fault-tolerant quantum computation.
Generative quantum advantage for classical and quantum problems
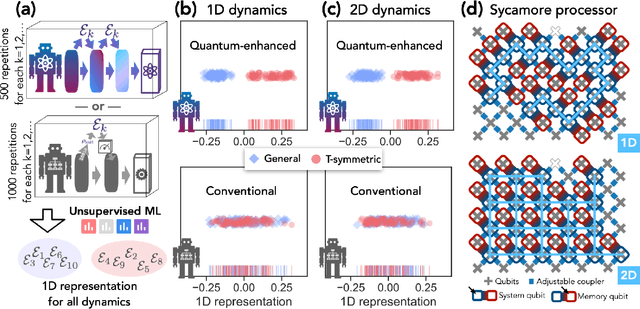
Sep 10, 2025Recent breakthroughs in generative machine learning, powered by massive computational resources, have demonstrated unprecedented human-like capabilities. While beyond-classical quantum experiments can generate samples from classically intractable distributions, their complexity has thwarted all efforts toward efficient learning. This challenge has hindered demonstrations of generative quantum advantage: the ability of quantum computers to learn and generate desired outputs substantially better than classical computers. We resolve this challenge by introducing families of generative quantum models that are hard to simulate classically, are efficiently trainable, exhibit no barren plateaus or proliferating local minima, and can learn to generate distributions beyond the reach of classical computers. Using a $68$-qubit superconducting quantum processor, we demonstrate these capabilities in two scenarios: learning classically intractable probability distributions and learning quantum circuits for accelerated physical simulation. Our results establish that both learning and sampling can be performed efficiently in the beyond-classical regime, opening new possibilities for quantum-enhanced generative models with provable advantage.
Learning to Decode the Surface Code with a Recurrent, Transformer-Based Neural Network
Oct 09, 2023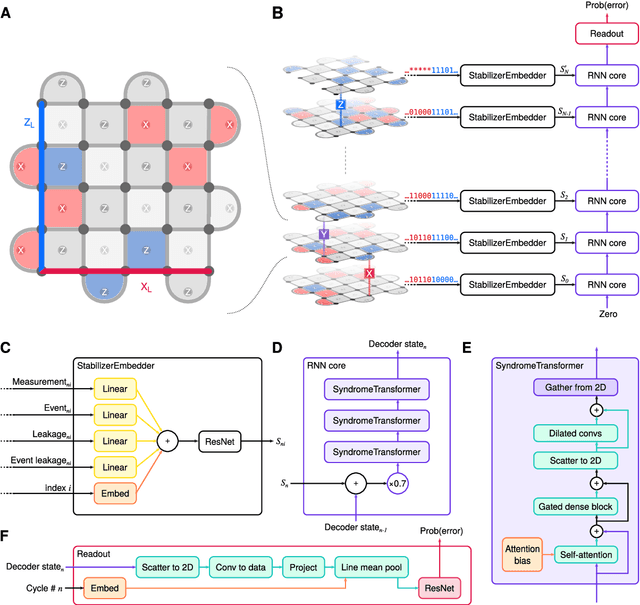
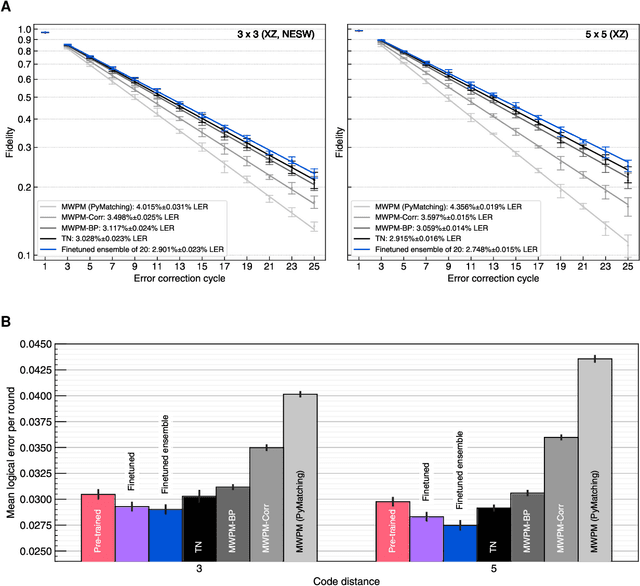
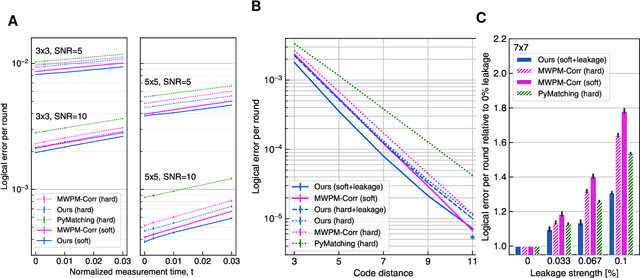
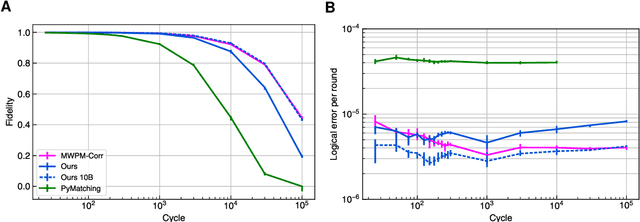
Quantum error-correction is a prerequisite for reliable quantum computation. Towards this goal, we present a recurrent, transformer-based neural network which learns to decode the surface code, the leading quantum error-correction code. Our decoder outperforms state-of-the-art algorithmic decoders on real-world data from Google's Sycamore quantum processor for distance 3 and 5 surface codes. On distances up to 11, the decoder maintains its advantage on simulated data with realistic noise including cross-talk, leakage, and analog readout signals, and sustains its accuracy far beyond the 25 cycles it was trained on. Our work illustrates the ability of machine learning to go beyond human-designed algorithms by learning from data directly, highlighting machine learning as a strong contender for decoding in quantum computers.
Need is All You Need: Homeostatic Neural Networks Adapt to Concept Shift
May 17, 2022
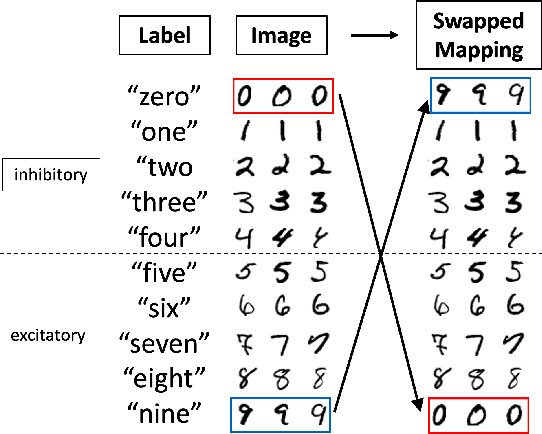
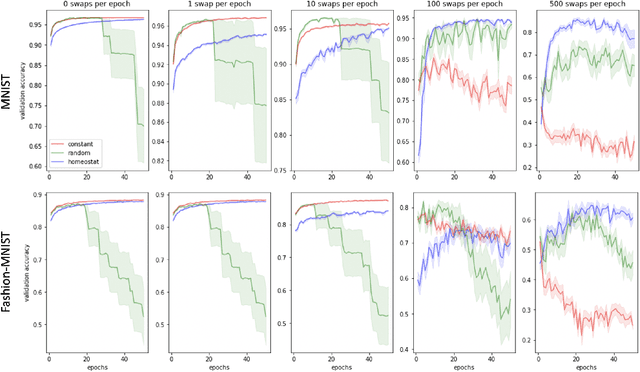

In living organisms, homeostasis is the natural regulation of internal states aimed at maintaining conditions compatible with life. Typical artificial systems are not equipped with comparable regulatory features. Here, we introduce an artificial neural network that incorporates homeostatic features. Its own computing substrate is placed in a needful and vulnerable relation to the very objects over which it computes. For example, artificial neurons performing classification of MNIST digits or Fashion-MNIST articles of clothing may receive excitatory or inhibitory effects, which alter their own learning rate as a direct result of perceiving and classifying the digits. In this scenario, accurate recognition is desirable to the agent itself because it guides decisions to regulate its vulnerable internal states and functionality. Counterintuitively, the addition of vulnerability to a learner does not necessarily impair its performance. On the contrary, self-regulation in response to vulnerability confers benefits under certain conditions. We show that homeostatic design confers increased adaptability under concept shift, in which the relationships between labels and data change over time, and that the greatest advantages are obtained under the highest rates of shift. This necessitates the rapid un-learning of past associations and the re-learning of new ones. We also demonstrate the superior abilities of homeostatic learners in environments with dynamically changing rates of concept shift. Our homeostatic design exposes the artificial neural network's thinking machinery to the consequences of its own "thoughts", illustrating the advantage of putting one's own "skin in the game" to improve fluid intelligence.
Quantum advantage in learning from experiments
Dec 01, 2021

Quantum technology has the potential to revolutionize how we acquire and process experimental data to learn about the physical world. An experimental setup that transduces data from a physical system to a stable quantum memory, and processes that data using a quantum computer, could have significant advantages over conventional experiments in which the physical system is measured and the outcomes are processed using a classical computer. We prove that, in various tasks, quantum machines can learn from exponentially fewer experiments than those required in conventional experiments. The exponential advantage holds in predicting properties of physical systems, performing quantum principal component analysis on noisy states, and learning approximate models of physical dynamics. In some tasks, the quantum processing needed to achieve the exponential advantage can be modest; for example, one can simultaneously learn about many noncommuting observables by processing only two copies of the system. Conducting experiments with up to 40 superconducting qubits and 1300 quantum gates, we demonstrate that a substantial quantum advantage can be realized using today's relatively noisy quantum processors. Our results highlight how quantum technology can enable powerful new strategies to learn about nature.
Nonequilibrium Monte Carlo for unfreezing variables in hard combinatorial optimization
Nov 26, 2021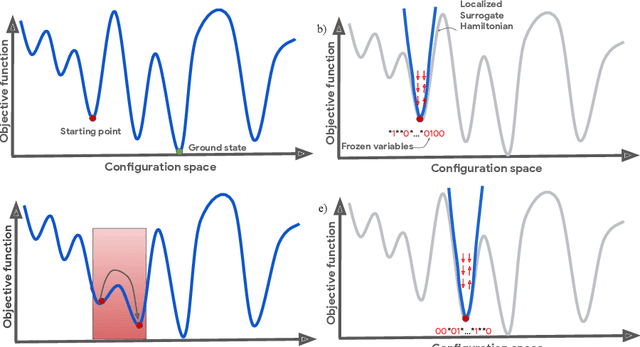
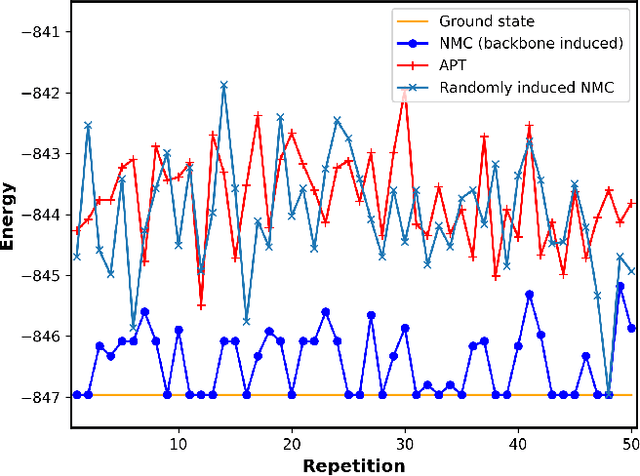
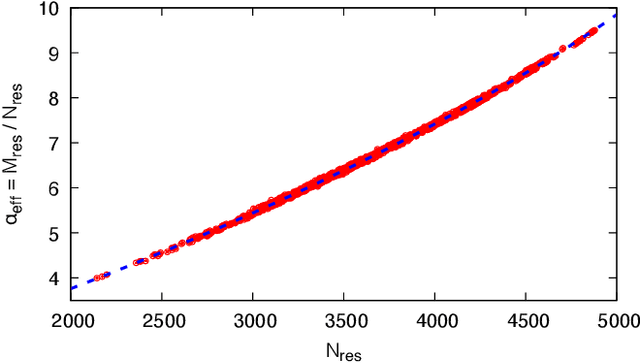
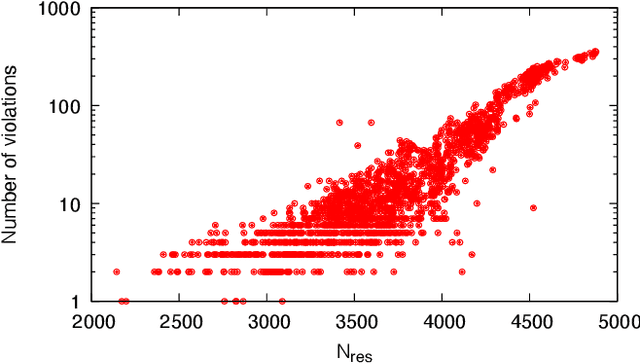
Optimizing highly complex cost/energy functions over discrete variables is at the heart of many open problems across different scientific disciplines and industries. A major obstacle is the emergence of many-body effects among certain subsets of variables in hard instances leading to critical slowing down or collective freezing for known stochastic local search strategies. An exponential computational effort is generally required to unfreeze such variables and explore other unseen regions of the configuration space. Here, we introduce a quantum-inspired family of nonlocal Nonequilibrium Monte Carlo (NMC) algorithms by developing an adaptive gradient-free strategy that can efficiently learn key instance-wise geometrical features of the cost function. That information is employed on-the-fly to construct spatially inhomogeneous thermal fluctuations for collectively unfreezing variables at various length scales, circumventing costly exploration versus exploitation trade-offs. We apply our algorithm to two of the most challenging combinatorial optimization problems: random k-satisfiability (k-SAT) near the computational phase transitions and Quadratic Assignment Problems (QAP). We observe significant speedup and robustness over both specialized deterministic solvers and generic stochastic solvers. In particular, for 90% of random 4-SAT instances we find solutions that are inaccessible for the best specialized deterministic algorithm known as Survey Propagation (SP) with an order of magnitude improvement in the quality of solutions for the hardest 10% instances. We also demonstrate two orders of magnitude improvement in time-to-solution over the state-of-the-art generic stochastic solver known as Adaptive Parallel Tempering (APT).
A quantum algorithm for training wide and deep classical neural networks
Jul 19, 2021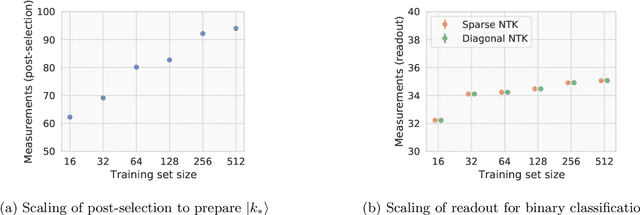
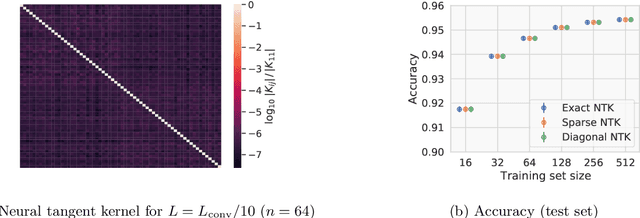
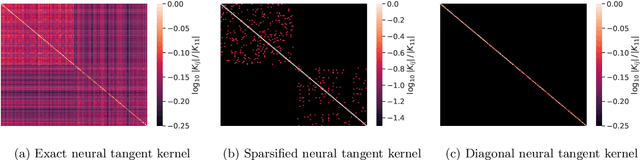
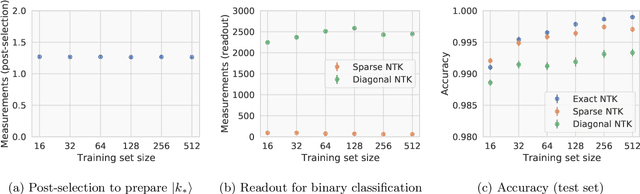
Given the success of deep learning in classical machine learning, quantum algorithms for traditional neural network architectures may provide one of the most promising settings for quantum machine learning. Considering a fully-connected feedforward neural network, we show that conditions amenable to classical trainability via gradient descent coincide with those necessary for efficiently solving quantum linear systems. We propose a quantum algorithm to approximately train a wide and deep neural network up to $O(1/n)$ error for a training set of size $n$ by performing sparse matrix inversion in $O(\log n)$ time. To achieve an end-to-end exponential speedup over gradient descent, the data distribution must permit efficient state preparation and readout. We numerically demonstrate that the MNIST image dataset satisfies such conditions; moreover, the quantum algorithm matches the accuracy of the fully-connected network. Beyond the proven architecture, we provide empirical evidence for $O(\log n)$ training of a convolutional neural network with pooling.
Power of data in quantum machine learning
Nov 03, 2020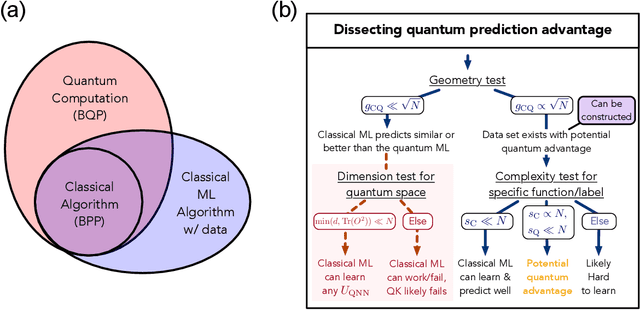
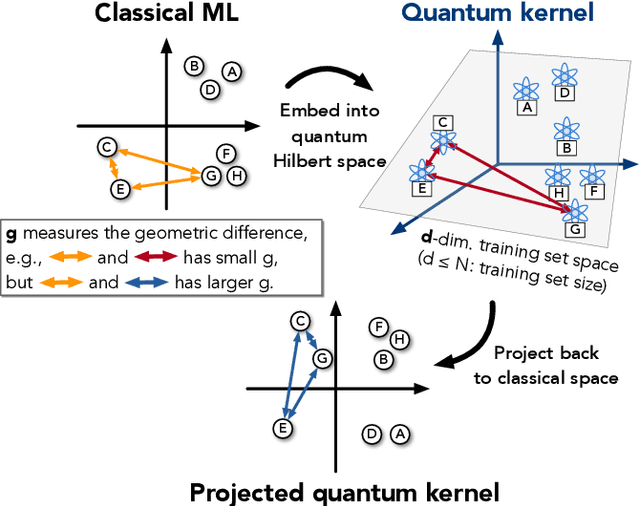
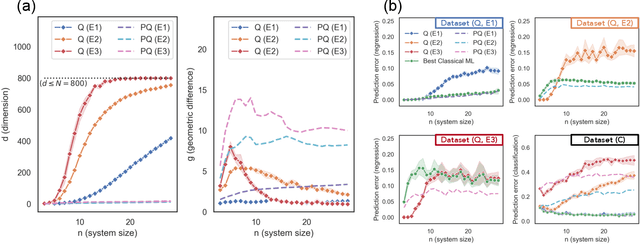
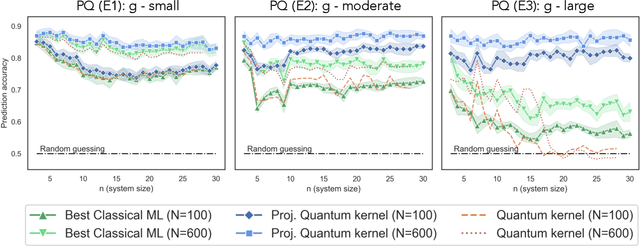
The use of quantum computing for machine learning is among the most exciting prospective applications of quantum technologies. At the crux of excitement is the potential for quantum computers to perform some computations exponentially faster than their classical counterparts. However, a machine learning task where some data is provided can be considerably different than more commonly studied computational tasks. In this work, we show that some problems that are classically hard to compute can be predicted easily with classical machines that learn from data. We find that classical machines can often compete or outperform existing quantum models even on data sets generated by quantum evolution, especially at large system sizes. Using rigorous prediction error bounds as a foundation, we develop a methodology for assessing the potential for quantum advantage in prediction on learning tasks. We show how the use of exponentially large quantum Hilbert space in existing quantum models can result in significantly inferior prediction performance compared to classical machines. To circumvent the observed setbacks, we propose an improvement by projecting all quantum states to an approximate classical representation. The projected quantum model provides a simple and rigorous quantum speed-up for a recently proposed learning problem in the fault-tolerant regime. For more near-term quantum models, the projected versions demonstrate a significant prediction advantage over some classical models on engineered data sets in one of the largest numerical tests for gate-based quantum machine learning to date, up to 30 qubits.
Learnability and Complexity of Quantum Samples
Oct 22, 2020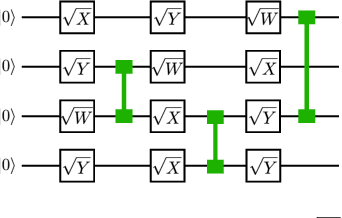
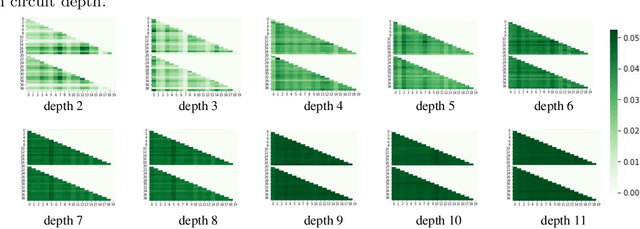
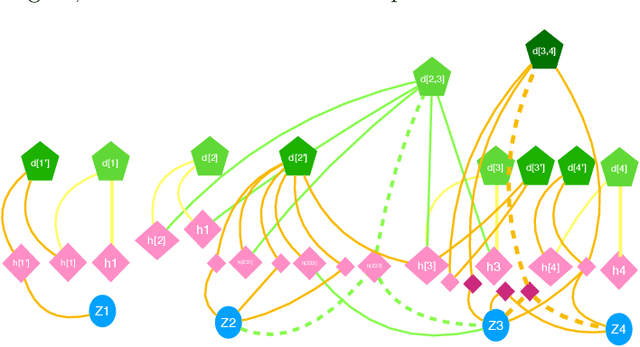
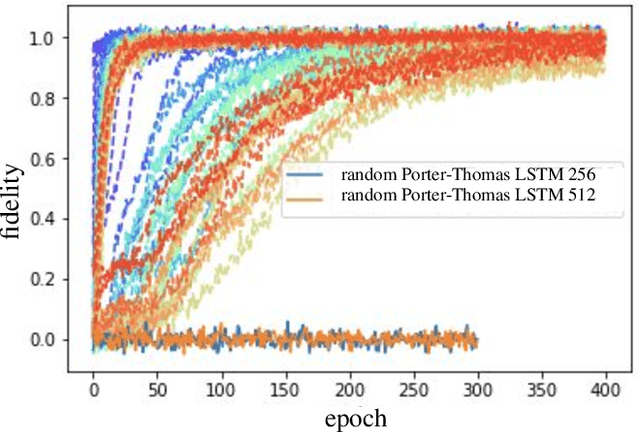
Given a quantum circuit, a quantum computer can sample the output distribution exponentially faster in the number of bits than classical computers. A similar exponential separation has yet to be established in generative models through quantum sample learning: given samples from an n-qubit computation, can we learn the underlying quantum distribution using models with training parameters that scale polynomial in n under a fixed training time? We study four kinds of generative models: Deep Boltzmann machine (DBM), Generative Adversarial Networks (GANs), Long Short-Term Memory (LSTM) and Autoregressive GAN, on learning quantum data set generated by deep random circuits. We demonstrate the leading performance of LSTM in learning quantum samples, and thus the autoregressive structure present in the underlying quantum distribution from random quantum circuits. Both numerical experiments and a theoretical proof in the case of the DBM show exponentially growing complexity of learning-agent parameters required for achieving a fixed accuracy as n increases. Finally, we establish a connection between learnability and the complexity of generative models by benchmarking learnability against different sets of samples drawn from probability distributions of variable degrees of complexities in their quantum and classical representations.
TensorFlow Quantum: A Software Framework for Quantum Machine Learning
Mar 06, 2020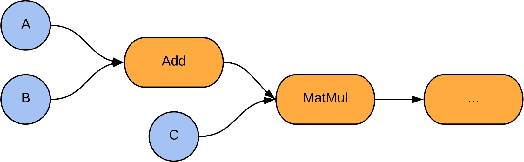
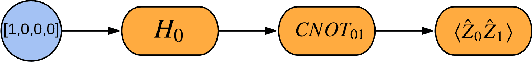
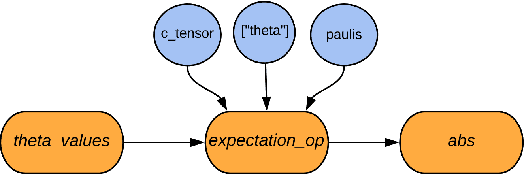
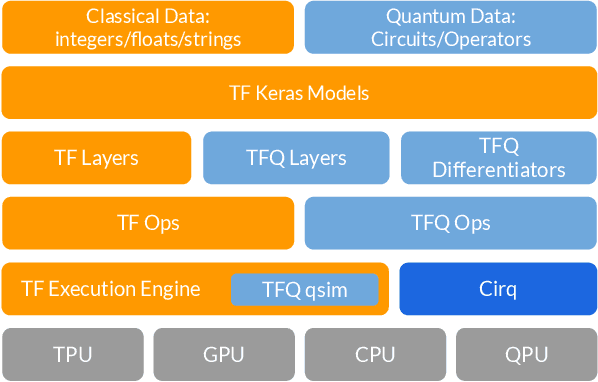
We introduce TensorFlow Quantum (TFQ), an open source library for the rapid prototyping of hybrid quantum-classical models for classical or quantum data. This framework offers high-level abstractions for the design and training of both discriminative and generative quantum models under TensorFlow and supports high-performance quantum circuit simulators. We provide an overview of the software architecture and building blocks through several examples and review the theory of hybrid quantum-classical neural networks. We illustrate TFQ functionalities via several basic applications including supervised learning for quantum classification, quantum control, and quantum approximate optimization. Moreover, we demonstrate how one can apply TFQ to tackle advanced quantum learning tasks including meta-learning, Hamiltonian learning, and sampling thermal states. We hope this framework provides the necessary tools for the quantum computing and machine learning research communities to explore models of both natural and artificial quantum systems, and ultimately discover new quantum algorithms which could potentially yield a quantum advantage.