 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA quantum algorithm for training wide and deep classical neural networks
Paper and Code
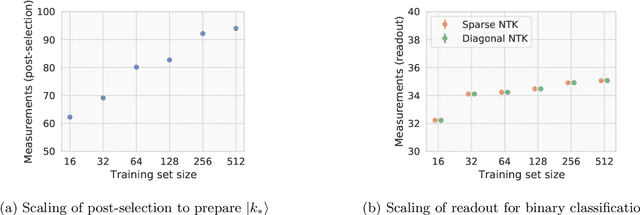
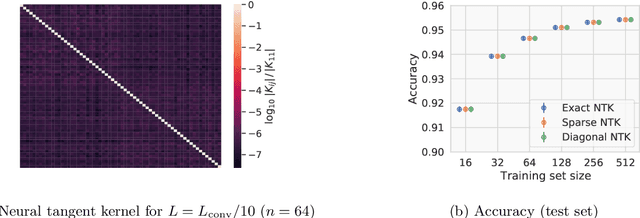
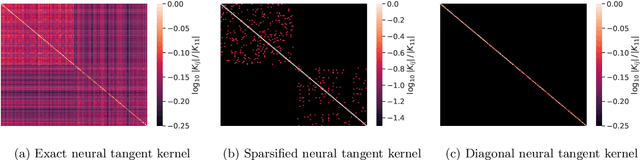
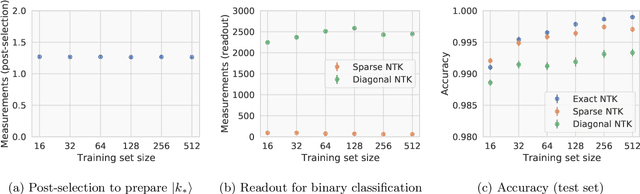
Given the success of deep learning in classical machine learning, quantum algorithms for traditional neural network architectures may provide one of the most promising settings for quantum machine learning. Considering a fully-connected feedforward neural network, we show that conditions amenable to classical trainability via gradient descent coincide with those necessary for efficiently solving quantum linear systems. We propose a quantum algorithm to approximately train a wide and deep neural network up to $O(1/n)$ error for a training set of size $n$ by performing sparse matrix inversion in $O(\log n)$ time. To achieve an end-to-end exponential speedup over gradient descent, the data distribution must permit efficient state preparation and readout. We numerically demonstrate that the MNIST image dataset satisfies such conditions; moreover, the quantum algorithm matches the accuracy of the fully-connected network. Beyond the proven architecture, we provide empirical evidence for $O(\log n)$ training of a convolutional neural network with pooling.