 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypersonic Flow Control: Generalized Deep Reinforcement Learning for Hypersonic Intake Unstart Control under Uncertainty
Jan 27, 2026The hypersonic unstart phenomenon poses a major challenge to reliable air-breathing propulsion at Mach 5 and above, where strong shock-boundary-layer interactions and rapid pressure fluctuations can destabilize inlet operation. Here, we demonstrate a deep reinforcement learning (DRL)- based active flow control strategy to control unstart in a canonical two-dimensional hypersonic inlet at Mach 5 and Reynolds number $5\times 10^6$. The in-house CFD solver enables high-fidelity simulations with adaptive mesh refinement, resolving key flow features, including shock motion, boundary-layer dynamics, and flow separation, that are essential for learning physically consistent control policies suitable for real-time deployment. The DRL controller robustly stabilizes the inlet over a wide range of back pressures representative of varying combustion chamber conditions. It further generalizes to previously unseen scenarios, including different back-pressure levels, Reynolds numbers, and sensor configurations, while operating with noisy measurements, thereby demonstrating strong zero-shot generalization. Control remains robust in the presence of noisy sensor measurements, and a minimal, optimally selected sensor set achieves comparable performance, enabling practical implementation. These results establish a data-driven approach for real-time hypersonic flow control under realistic operational uncertainties.
Shocks Under Control: Taming Transonic Compressible Flow over an RAE2822 Airfoil with Deep Reinforcement Learning
Nov 10, 2025Active flow control of compressible transonic shock-boundary layer interactions over a two-dimensional RAE2822 airfoil at Re = 50,000 is investigated using deep reinforcement learning (DRL). The flow field exhibits highly unsteady dynamics, including complex shock-boundary layer interactions, shock oscillations, and the generation of Kutta waves from the trailing edge. A high-fidelity CFD solver, employing a fifth-order spectral discontinuous Galerkin scheme in space and a strong-stability-preserving Runge-Kutta (5,4) method in time, together with adaptive mesh refinement capability, is used to obtain the accurate flow field. Synthetic jet actuation is employed to manipulate these unsteady flow features, while the DRL agent autonomously discovers effective control strategies through direct interaction with high-fidelity compressible flow simulations. The trained controllers effectively mitigate shock-induced separation, suppress unsteady oscillations, and manipulate aerodynamic forces under transonic conditions. In the first set of experiments, aimed at both drag reduction and lift enhancement, the DRL-based control reduces the average drag coefficient by 13.78% and increases lift by 131.18%, thereby improving the lift-to-drag ratio by 121.52%, which underscores its potential for managing complex flow dynamics. In the second set, targeting drag reduction while maintaining lift, the DRL-based control achieves a 25.62% reduction in drag and a substantial 196.30% increase in lift, accompanied by markedly diminished oscillations. In this case, the lift-to-drag ratio improves by 220.26%.
BubbleONet: A Physics-Informed Neural Operator for High-Frequency Bubble Dynamics
Aug 05, 2025



This paper introduces BubbleONet, an operator learning model designed to map pressure profiles from an input function space to corresponding bubble radius responses. BubbleONet is built upon the physics-informed deep operator network (PI-DeepONet) framework, leveraging DeepONet's powerful universal approximation capabilities for operator learning alongside the robust physical fidelity provided by the physics-informed neural networks. To mitigate the inherent spectral bias in deep learning, BubbleONet integrates the Rowdy adaptive activation function, enabling improved representation of high-frequency features. The model is evaluated across various scenarios, including: (1) Rayleigh-Plesset equation based bubble dynamics with a single initial radius, (2) Keller-Miksis equation based bubble dynamics with a single initial radius, and (3) Keller-Miksis equation based bubble dynamics with multiple initial radii. Moreover, the performance of single-step versus two-step training techniques for BubbleONet is investigated. The results demonstrate that BubbleONet serves as a promising surrogate model for simulating bubble dynamics, offering a computationally efficient alternative to traditional numerical solvers.
Anant-Net: Breaking the Curse of Dimensionality with Scalable and Interpretable Neural Surrogate for High-Dimensional PDEs
May 07, 2025



High-dimensional partial differential equations (PDEs) arise in diverse scientific and engineering applications but remain computationally intractable due to the curse of dimensionality. Traditional numerical methods struggle with the exponential growth in computational complexity, particularly on hypercubic domains, where the number of required collocation points increases rapidly with dimensionality. Here, we introduce Anant-Net, an efficient neural surrogate that overcomes this challenge, enabling the solution of PDEs in high dimensions. Unlike hyperspheres, where the internal volume diminishes as dimensionality increases, hypercubes retain or expand their volume (for unit or larger length), making high-dimensional computations significantly more demanding. Anant-Net efficiently incorporates high-dimensional boundary conditions and minimizes the PDE residual at high-dimensional collocation points. To enhance interpretability, we integrate Kolmogorov-Arnold networks into the Anant-Net architecture. We benchmark Anant-Net's performance on several linear and nonlinear high-dimensional equations, including the Poisson, Sine-Gordon, and Allen-Cahn equations, demonstrating high accuracy and robustness across randomly sampled test points from high-dimensional space. Importantly, Anant-Net achieves these results with remarkable efficiency, solving 300-dimensional problems on a single GPU within a few hours. We also compare Anant-Net's results for accuracy and runtime with other state-of-the-art methods. Our findings establish Anant-Net as an accurate, interpretable, and scalable framework for efficiently solving high-dimensional PDEs.
Large Language Model-Based Evolutionary Optimizer: Reasoning with elitism
Mar 04, 2024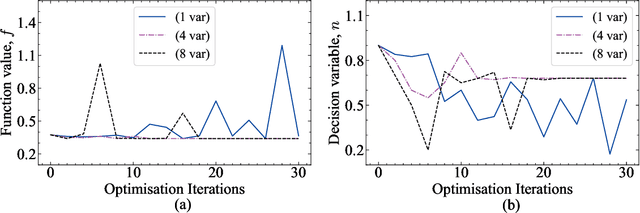



Large Language Models (LLMs) have demonstrated remarkable reasoning abilities, prompting interest in their application as black-box optimizers. This paper asserts that LLMs possess the capability for zero-shot optimization across diverse scenarios, including multi-objective and high-dimensional problems. We introduce a novel population-based method for numerical optimization using LLMs called Language-Model-Based Evolutionary Optimizer (LEO). Our hypothesis is supported through numerical examples, spanning benchmark and industrial engineering problems such as supersonic nozzle shape optimization, heat transfer, and windfarm layout optimization. We compare our method to several gradient-based and gradient-free optimization approaches. While LLMs yield comparable results to state-of-the-art methods, their imaginative nature and propensity to hallucinate demand careful handling. We provide practical guidelines for obtaining reliable answers from LLMs and discuss method limitations and potential research directions.
RiemannONets: Interpretable Neural Operators for Riemann Problems
Jan 16, 2024



Developing the proper representations for simulating high-speed flows with strong shock waves, rarefactions, and contact discontinuities has been a long-standing question in numerical analysis. Herein, we employ neural operators to solve Riemann problems encountered in compressible flows for extreme pressure jumps (up to $10^{10}$ pressure ratio). In particular, we first consider the DeepONet that we train in a two-stage process, following the recent work of Lee and Shin, wherein the first stage, a basis is extracted from the trunk net, which is orthonormalized and subsequently is used in the second stage in training the branch net. This simple modification of DeepONet has a profound effect on its accuracy, efficiency, and robustness and leads to very accurate solutions to Riemann problems compared to the vanilla version. It also enables us to interpret the results physically as the hierarchical data-driven produced basis reflects all the flow features that would otherwise be introduced using ad hoc feature expansion layers. We also compare the results with another neural operator based on the U-Net for low, intermediate, and very high-pressure ratios that are very accurate for Riemann problems, especially for large pressure ratios, due to their multiscale nature but computationally more expensive. Overall, our study demonstrates that simple neural network architectures, if properly pre-trained, can achieve very accurate solutions of Riemann problems for real-time forecasting.
Deep smoothness WENO scheme for two-dimensional hyperbolic conservation laws: A deep learning approach for learning smoothness indicators
Sep 18, 2023In this paper, we introduce an improved version of the fifth-order weighted essentially non-oscillatory (WENO) shock-capturing scheme by incorporating deep learning techniques. The established WENO algorithm is improved by training a compact neural network to adjust the smoothness indicators within the WENO scheme. This modification enhances the accuracy of the numerical results, particularly near abrupt shocks. Unlike previous deep learning-based methods, no additional post-processing steps are necessary for maintaining consistency. We demonstrate the superiority of our new approach using several examples from the literature for the two-dimensional Euler equations of gas dynamics. Through intensive study of these test problems, which involve various shocks and rarefaction waves, the new technique is shown to outperform traditional fifth-order WENO schemes, especially in cases where the numerical solutions exhibit excessive diffusion or overshoot around shocks.
A unified scalable framework for causal sweeping strategies for Physics-Informed Neural Networks (PINNs) and their temporal decompositions
Feb 28, 2023



Physics-informed neural networks (PINNs) as a means of solving partial differential equations (PDE) have garnered much attention in Computational Science and Engineering (CS&E). However, a recent topic of interest is exploring various training (i.e., optimization) challenges - in particular, arriving at poor local minima in the optimization landscape results in a PINN approximation giving an inferior, and sometimes trivial, solution when solving forward time-dependent PDEs with no data. This problem is also found in, and in some sense more difficult, with domain decomposition strategies such as temporal decomposition using XPINNs. To address this problem, we first enable a general categorization for previous causality methods, from which we identify a gap in the previous approaches. We then furnish examples and explanations for different training challenges, their cause, and how they relate to information propagation and temporal decomposition. We propose a solution to fill this gap by reframing these causality concepts into a generalized information propagation framework in which any prior method or combination of methods can be described. Our unified framework moves toward reducing the number of PINN methods to consider and the implementation and retuning cost for thorough comparisons. We propose a new stacked-decomposition method that bridges the gap between time-marching PINNs and XPINNs. We also introduce significant computational speed-ups by using transfer learning concepts to initialize subnetworks in the domain and loss tolerance-based propagation for the subdomains. We formulate a new time-sweeping collocation point algorithm inspired by the previous PINNs causality literature, which our framework can still describe, and provides a significant computational speed-up via reduced-cost collocation point segmentation. Finally, we provide numerical results on baseline PDE problems.
Learning stiff chemical kinetics using extended deep neural operators
Feb 23, 2023We utilize neural operators to learn the solution propagator for the challenging chemical kinetics equation. Specifically, we apply the deep operator network (DeepONet) along with its extensions, such as the autoencoder-based DeepONet and the newly proposed Partition-of-Unity (PoU-) DeepONet to study a range of examples, including the ROBERS problem with three species, the POLLU problem with 25 species, pure kinetics of the syngas skeletal model for $CO/H_2$ burning, which contains 11 species and 21 reactions and finally, a temporally developing planar $CO/H_2$ jet flame (turbulent flame) using the same syngas mechanism. We have demonstrated the advantages of the proposed approach through these numerical examples. Specifically, to train the DeepONet for the syngas model, we solve the skeletal kinetic model for different initial conditions. In the first case, we parametrize the initial conditions based on equivalence ratios and initial temperature values. In the second case, we perform a direct numerical simulation of a two-dimensional temporally developing $CO/H_2$ jet flame. Then, we initialize the kinetic model by the thermochemical states visited by a subset of grid points at different time snapshots. Stiff problems are computationally expensive to solve with traditional stiff solvers. Thus, this work aims to develop a neural operator-based surrogate model to solve stiff chemical kinetics. The operator, once trained offline, can accurately integrate the thermochemical state for arbitrarily large time advancements, leading to significant computational gains compared to stiff integration schemes.
Augmented Physics-Informed Neural Networks (APINNs): A gating network-based soft domain decomposition methodology
Nov 23, 2022In this paper, we propose the augmented physics-informed neural network (APINN), which adopts soft and trainable domain decomposition and flexible parameter sharing to further improve the extended PINN (XPINN) as well as the vanilla PINN methods. In particular, a trainable gate network is employed to mimic the hard decomposition of XPINN, which can be flexibly fine-tuned for discovering a potentially better partition. It weight-averages several sub-nets as the output of APINN. APINN does not require complex interface conditions, and its sub-nets can take advantage of all training samples rather than just part of the training data in their subdomains. Lastly, each sub-net shares part of the common parameters to capture the similar components in each decomposed function. Furthermore, following the PINN generalization theory in Hu et al. [2021], we show that APINN can improve generalization by proper gate network initialization and general domain & function decomposition. Extensive experiments on different types of PDEs demonstrate how APINN improves the PINN and XPINN methods. Specifically, we present examples where XPINN performs similarly to or worse than PINN, so that APINN can significantly improve both. We also show cases where XPINN is already better than PINN, so APINN can still slightly improve XPINN. Furthermore, we visualize the optimized gating networks and their optimization trajectories, and connect them with their performance, which helps discover the possibly optimal decomposition. Interestingly, if initialized by different decomposition, the performances of corresponding APINNs can differ drastically. This, in turn, shows the potential to design an optimal domain decomposition for the differential equation problem under consideration.