 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn operator preconditioning perspective on training in physics-informed machine learning
Oct 09, 2023In this paper, we investigate the behavior of gradient descent algorithms in physics-informed machine learning methods like PINNs, which minimize residuals connected to partial differential equations (PDEs). Our key result is that the difficulty in training these models is closely related to the conditioning of a specific differential operator. This operator, in turn, is associated to the Hermitian square of the differential operator of the underlying PDE. If this operator is ill-conditioned, it results in slow or infeasible training. Therefore, preconditioning this operator is crucial. We employ both rigorous mathematical analysis and empirical evaluations to investigate various strategies, explaining how they better condition this critical operator, and consequently improve training.
wPINNs: Weak Physics informed neural networks for approximating entropy solutions of hyperbolic conservation laws
Jul 18, 2022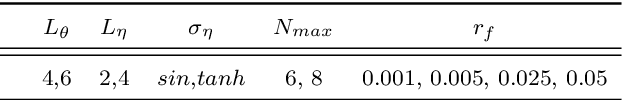
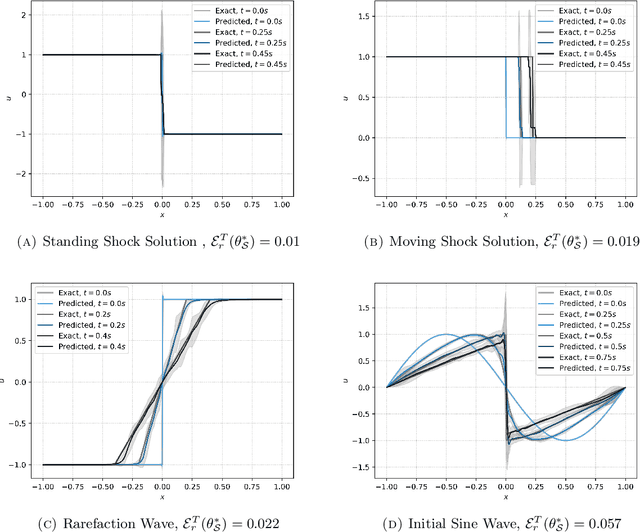
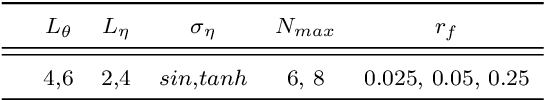
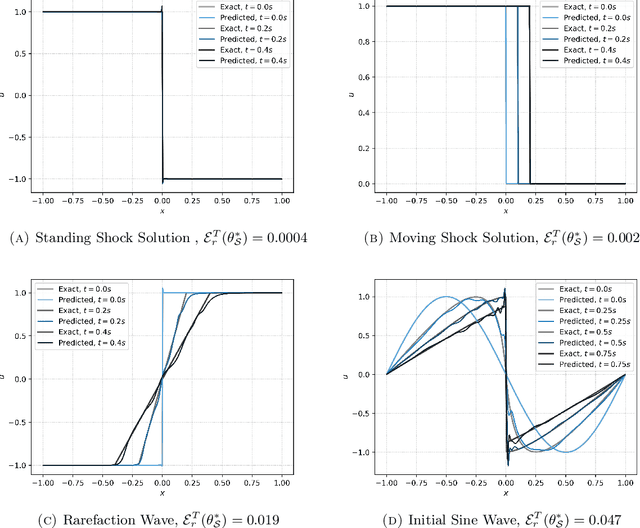
Physics informed neural networks (PINNs) require regularity of solutions of the underlying PDE to guarantee accurate approximation. Consequently, they may fail at approximating discontinuous solutions of PDEs such as nonlinear hyperbolic equations. To ameliorate this, we propose a novel variant of PINNs, termed as weak PINNs (wPINNs) for accurate approximation of entropy solutions of scalar conservation laws. wPINNs are based on approximating the solution of a min-max optimization problem for a residual, defined in terms of Kruzkhov entropies, to determine parameters for the neural networks approximating the entropy solution as well as test functions. We prove rigorous bounds on the error incurred by wPINNs and illustrate their performance through numerical experiments to demonstrate that wPINNs can approximate entropy solutions accurately.
Error analysis for deep neural network approximations of parametric hyperbolic conservation laws
Jul 15, 2022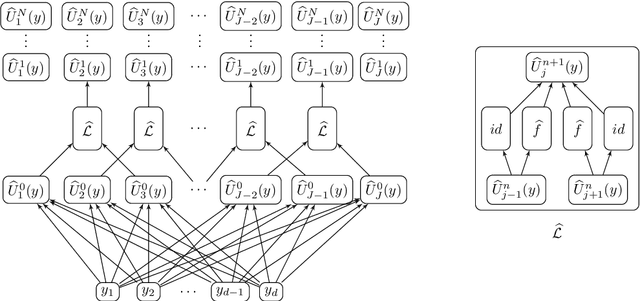
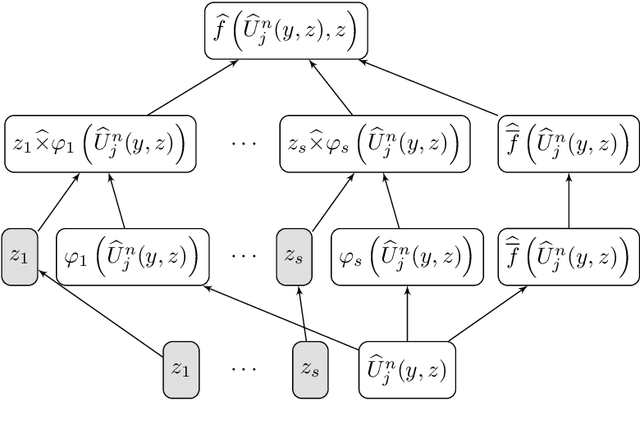
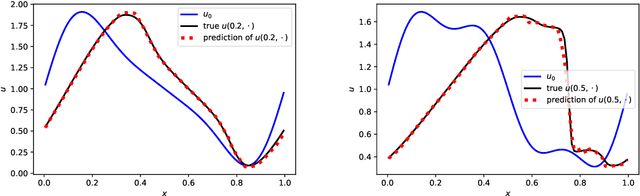
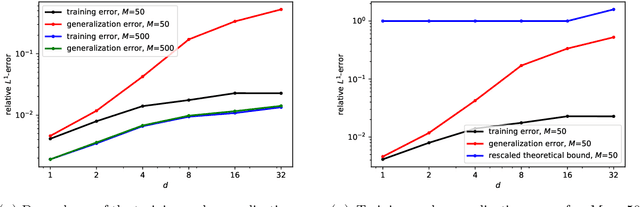
We derive rigorous bounds on the error resulting from the approximation of the solution of parametric hyperbolic scalar conservation laws with ReLU neural networks. We show that the approximation error can be made as small as desired with ReLU neural networks that overcome the curse of dimensionality. In addition, we provide an explicit upper bound on the generalization error in terms of the training error, number of training samples and the neural network size. The theoretical results are illustrated by numerical experiments.
Variable-Input Deep Operator Networks
May 23, 2022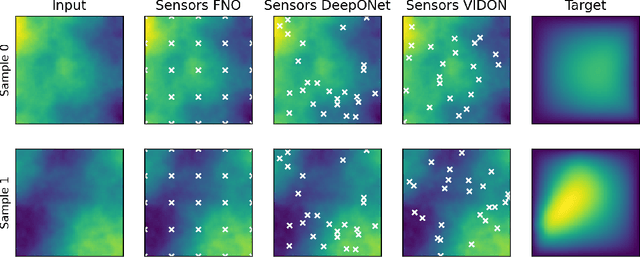
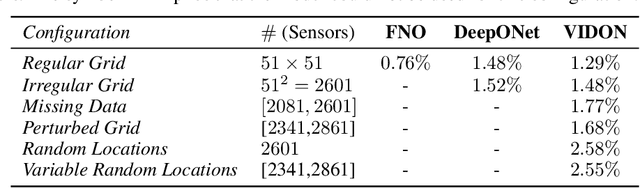
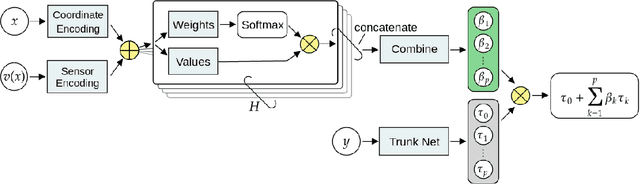

Existing architectures for operator learning require that the number and locations of sensors (where the input functions are evaluated) remain the same across all training and test samples, significantly restricting the range of their applicability. We address this issue by proposing a novel operator learning framework, termed Variable-Input Deep Operator Network (VIDON), which allows for random sensors whose number and locations can vary across samples. VIDON is invariant to permutations of sensor locations and is proved to be universal in approximating a class of continuous operators. We also prove that VIDON can efficiently approximate operators arising in PDEs. Numerical experiments with a diverse set of PDEs are presented to illustrate the robust performance of VIDON in learning operators.
Generic bounds on the approximation error for physics-informed operator learning
May 23, 2022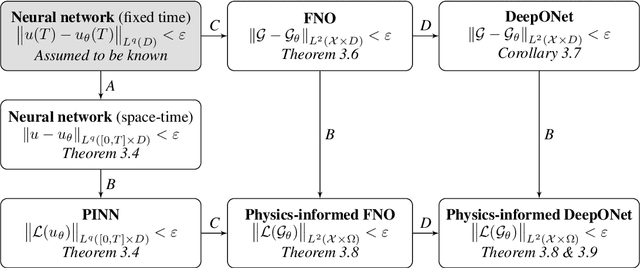

We propose a very general framework for deriving rigorous bounds on the approximation error for physics-informed neural networks (PINNs) and operator learning architectures such as DeepONets and FNOs as well as for physics-informed operator learning. These bounds guarantee that PINNs and (physics-informed) DeepONets or FNOs will efficiently approximate the underlying solution or solution operator of generic partial differential equations (PDEs). Our framework utilizes existing neural network approximation results to obtain bounds on more involved learning architectures for PDEs. We illustrate the general framework by deriving the first rigorous bounds on the approximation error of physics-informed operator learning and by showing that PINNs (and physics-informed DeepONets and FNOs) mitigate the curse of dimensionality in approximating nonlinear parabolic PDEs.
Error estimates for physics informed neural networks approximating the Navier-Stokes equations
Mar 17, 2022

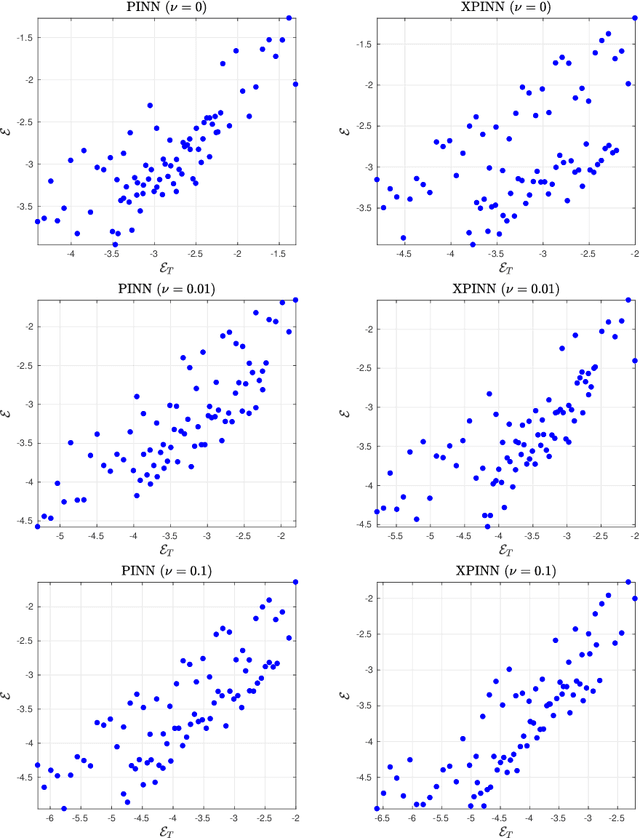
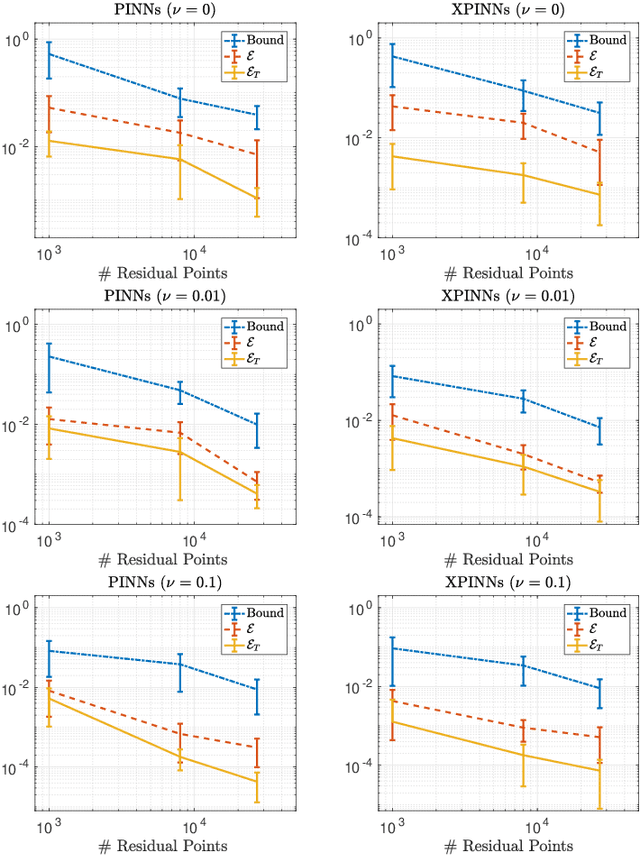
We prove rigorous bounds on the errors resulting from the approximation of the incompressible Navier-Stokes equations with (extended) physics informed neural networks. We show that the underlying PDE residual can be made arbitrarily small for tanh neural networks with two hidden layers. Moreover, the total error can be estimated in terms of the training error, network size and number of quadrature points. The theory is illustrated with numerical experiments.
Error analysis for physics informed neural networks (PINNs) approximating Kolmogorov PDEs
Jul 10, 2021
Physics informed neural networks approximate solutions of PDEs by minimizing pointwise residuals. We derive rigorous bounds on the error, incurred by PINNs in approximating the solutions of a large class of linear parabolic PDEs, namely Kolmogorov equations that include the heat equation and Black-Scholes equation of option pricing, as examples. We construct neural networks, whose PINN residual (generalization error) can be made as small as desired. We also prove that the total $L^2$-error can be bounded by the generalization error, which in turn is bounded in terms of the training error, provided that a sufficient number of randomly chosen training (collocation) points is used. Moreover, we prove that the size of the PINNs and the number of training samples only grow polynomially with the underlying dimension, enabling PINNs to overcome the curse of dimensionality in this context. These results enable us to provide a comprehensive error analysis for PINNs in approximating Kolmogorov PDEs.
On the approximation of functions by tanh neural networks
Apr 18, 2021

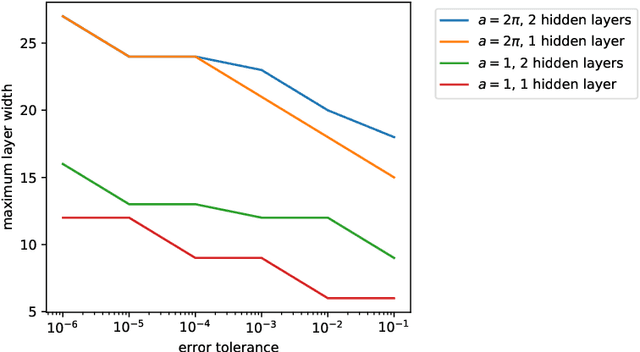
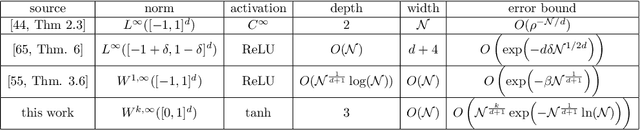
We derive bounds on the error, in high-order Sobolev norms, incurred in the approximation of Sobolev-regular as well as analytic functions by neural networks with the hyperbolic tangent activation function. These bounds provide explicit estimates on the approximation error with respect to the size of the neural networks. We show that tanh neural networks with only two hidden layers suffice to approximate functions at comparable or better rates than much deeper ReLU neural networks.
Change Point Detection in Time Series Data using Autoencoders with a Time-Invariant Representation
Aug 21, 2020
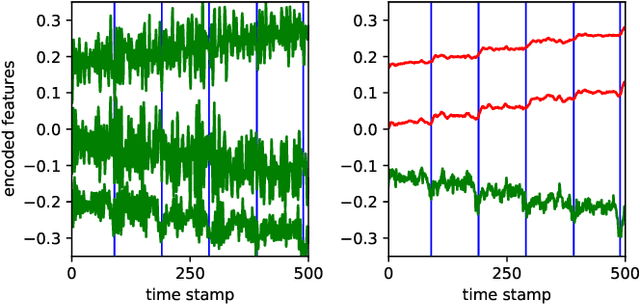


Change point detection (CPD) aims to locate abrupt property changes in time series data. Recent CPD methods demonstrated the potential of using deep learning techniques, but often lack the ability to identify more subtle changes in the autocorrelation statistics of the signal and suffer from a high false alarm rate. To address these issues, we employ an autoencoder-based methodology with a novel loss function, through which the used autoencoders learn a partially time-invariant representation that is tailored for CPD. The result is a flexible method that allows the user to indicate whether change points should be sought in the time domain, frequency domain or both. Detectable change points include abrupt changes in the slope, mean, variance, autocorrelation function and frequency spectrum. We demonstrate that our proposed method is consistently highly competitive or superior to baseline methods on diverse simulated and real-life benchmark data sets. Finally, we mitigate the issue of false detection alarms through the use of a postprocessing procedure that combines a matched filter and a newly proposed change point score. We show that this combination drastically improves the performance of our method as well as all baseline methods.
On the approximation of rough functions with deep neural networks
Dec 13, 2019
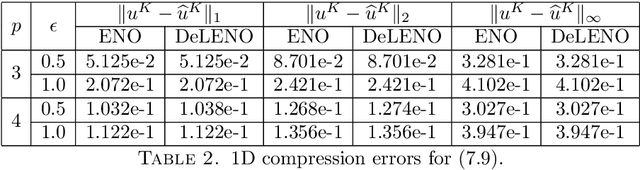
Deep neural networks and the ENO procedure are both efficient frameworks for approximating rough functions. We prove that at any order, the ENO interpolation procedure can be cast as a deep ReLU neural network. This surprising fact enables the transfer of several desirable properties of the ENO procedure to deep neural networks, including its high-order accuracy at approximating Lipschitz functions. Numerical tests for the resulting neural networks show excellent performance for approximating solutions of nonlinear conservation laws and at data compression.