 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRole of Data Augmentation Strategies in Knowledge Distillation for Wearable Sensor Data
Paper and Code
Jan 01, 2022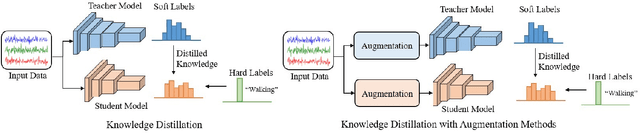
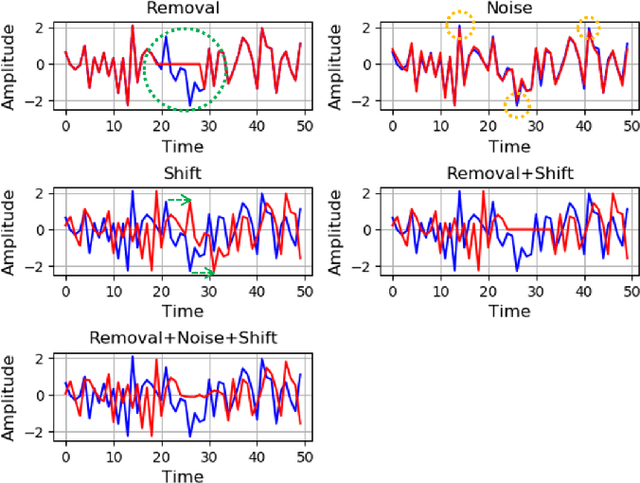
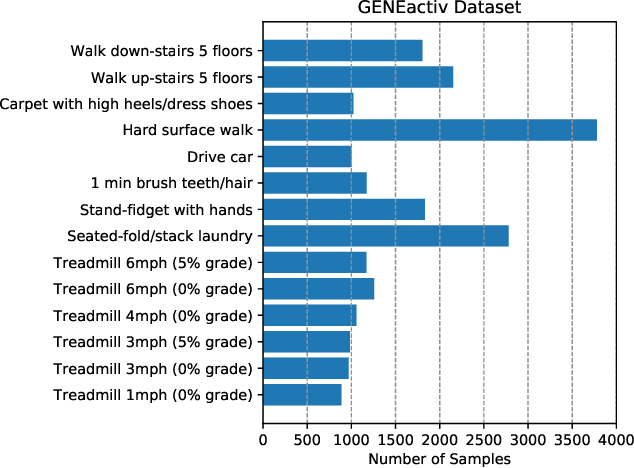
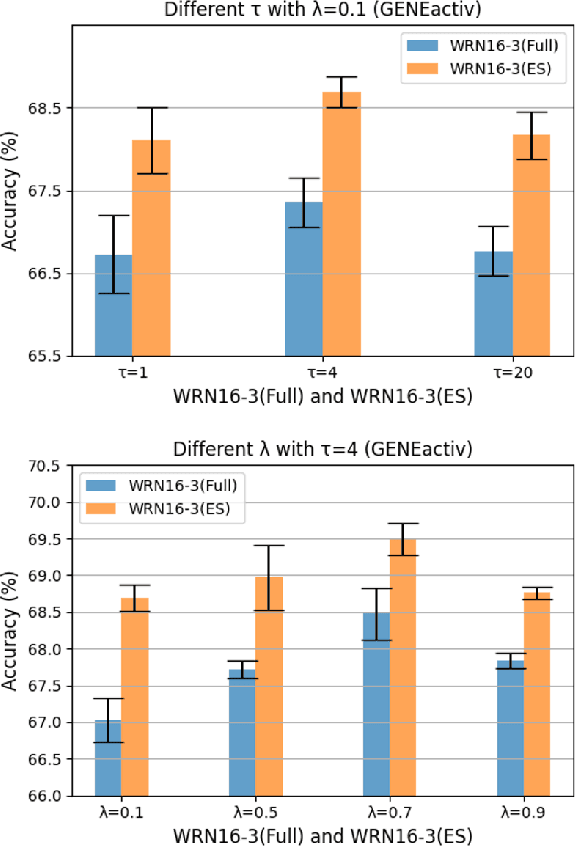
Deep neural networks are parametrized by several thousands or millions of parameters, and have shown tremendous success in many classification problems. However, the large number of parameters makes it difficult to integrate these models into edge devices such as smartphones and wearable devices. To address this problem, knowledge distillation (KD) has been widely employed, that uses a pre-trained high capacity network to train a much smaller network, suitable for edge devices. In this paper, for the first time, we study the applicability and challenges of using KD for time-series data for wearable devices. Successful application of KD requires specific choices of data augmentation methods during training. However, it is not yet known if there exists a coherent strategy for choosing an augmentation approach during KD. In this paper, we report the results of a detailed study that compares and contrasts various common choices and some hybrid data augmentation strategies in KD based human activity analysis. Research in this area is often limited as there are not many comprehensive databases available in the public domain from wearable devices. Our study considers databases from small scale publicly available to one derived from a large scale interventional study into human activity and sedentary behavior. We find that the choice of data augmentation techniques during KD have a variable level of impact on end performance, and find that the optimal network choice as well as data augmentation strategies are specific to a dataset at hand. However, we also conclude with a general set of recommendations that can provide a strong baseline performance across databases.