 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOPU: Conformal Prediction for Uncertainty Quantification in Natural Language Generation
Paper and Code
Feb 18, 2025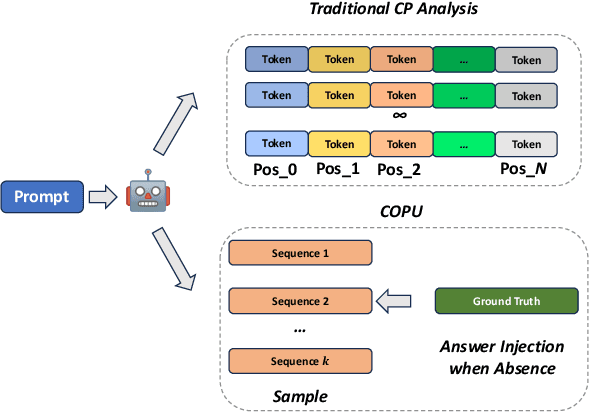
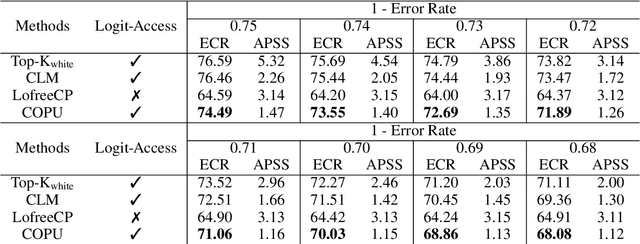


Uncertainty Quantification (UQ) for Natural Language Generation (NLG) is crucial for assessing the performance of Large Language Models (LLMs), as it reveals confidence in predictions, identifies failure modes, and gauges output reliability. Conformal Prediction (CP), a model-agnostic method that generates prediction sets with a specified error rate, has been adopted for UQ in classification tasks, where the size of the prediction set indicates the model's uncertainty. However, when adapting CP to NLG, the sampling-based method for generating candidate outputs cannot guarantee the inclusion of the ground truth, limiting its applicability across a wide range of error rates. To address this, we propose \ourmethod, a method that explicitly adds the ground truth to the candidate outputs and uses logit scores to measure nonconformity. Our experiments with six LLMs on four NLG tasks show that \ourmethod outperforms baseline methods in calibrating error rates and empirical cover rates, offering accurate UQ across a wide range of user-specified error rates.