 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChimera: Improving Generalist Model with Domain-Specific Experts
Paper and Code
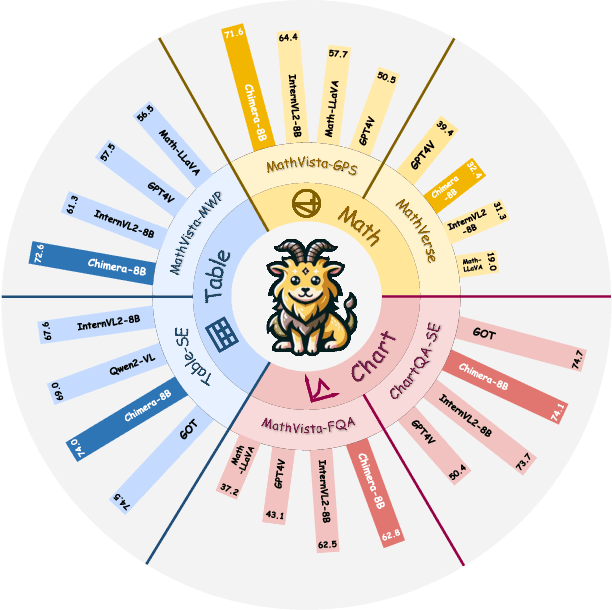
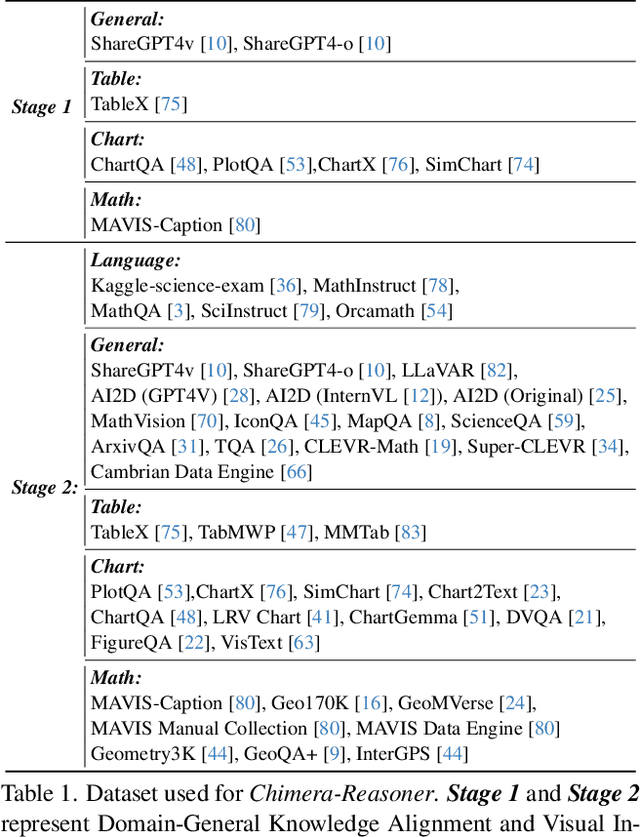
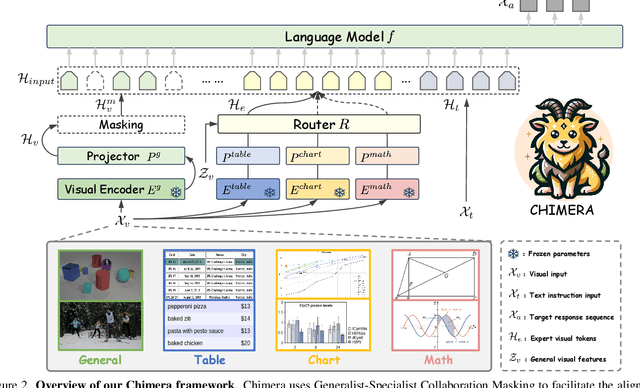
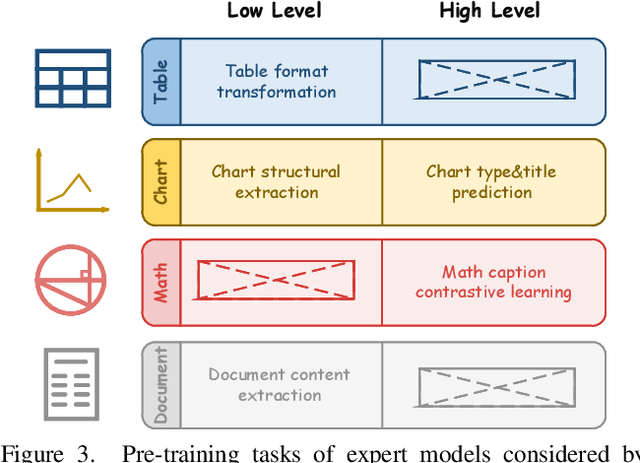
Recent advancements in Large Multi-modal Models (LMMs) underscore the importance of scaling by increasing image-text paired data, achieving impressive performance on general tasks. Despite their effectiveness in broad applications, generalist models are primarily trained on web-scale datasets dominated by natural images, resulting in the sacrifice of specialized capabilities for domain-specific tasks that require extensive domain prior knowledge. Moreover, directly integrating expert models tailored for specific domains is challenging due to the representational gap and imbalanced optimization between the generalist model and experts. To address these challenges, we introduce Chimera, a scalable and low-cost multi-modal pipeline designed to boost the ability of existing LMMs with domain-specific experts. Specifically, we design a progressive training strategy to integrate features from expert models into the input of a generalist LMM. To address the imbalanced optimization caused by the well-aligned general visual encoder, we introduce a novel Generalist-Specialist Collaboration Masking (GSCM) mechanism. This results in a versatile model that excels across the chart, table, math, and document domains, achieving state-of-the-art performance on multi-modal reasoning and visual content extraction tasks, both of which are challenging tasks for assessing existing LMMs.