 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
May 27, 2025In this paper, we introduce UI-Genie, a self-improving framework addressing two key challenges in GUI agents: verification of trajectory outcome is challenging and high-quality training data are not scalable. These challenges are addressed by a reward model and a self-improving pipeline, respectively. The reward model, UI-Genie-RM, features an image-text interleaved architecture that efficiently pro- cesses historical context and unifies action-level and task-level rewards. To sup- port the training of UI-Genie-RM, we develop deliberately-designed data genera- tion strategies including rule-based verification, controlled trajectory corruption, and hard negative mining. To address the second challenge, a self-improvement pipeline progressively expands solvable complex GUI tasks by enhancing both the agent and reward models through reward-guided exploration and outcome verification in dynamic environments. For training the model, we generate UI- Genie-RM-517k and UI-Genie-Agent-16k, establishing the first reward-specific dataset for GUI agents while demonstrating high-quality synthetic trajectory gen- eration without manual annotation. Experimental results show that UI-Genie achieves state-of-the-art performance across multiple GUI agent benchmarks with three generations of data-model self-improvement. We open-source our complete framework implementation and generated datasets to facilitate further research in https://github.com/Euphoria16/UI-Genie.
BlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices
Nov 16, 2024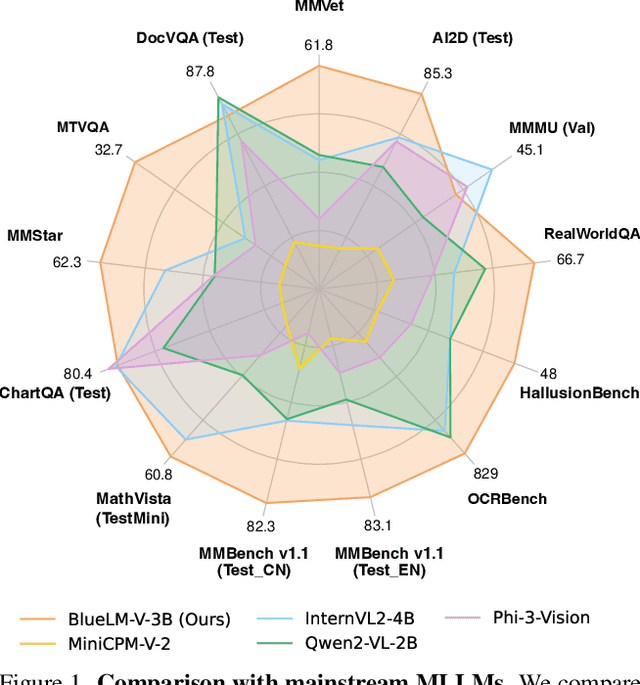
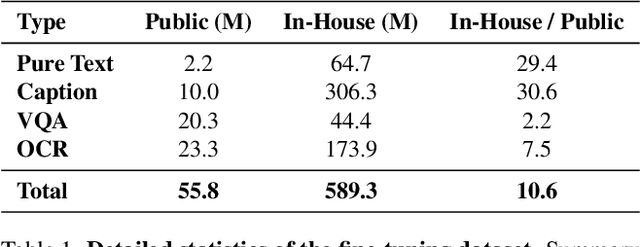
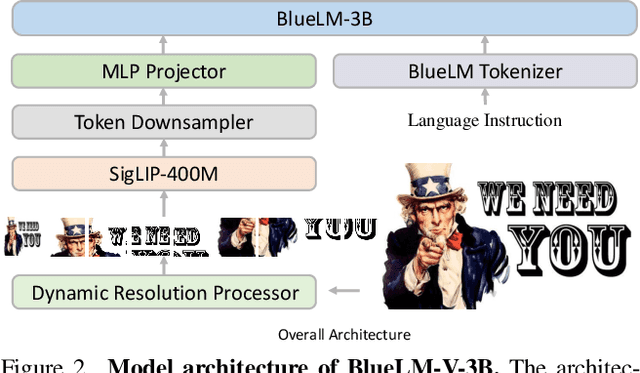

The emergence and growing popularity of multimodal large language models (MLLMs) have significant potential to enhance various aspects of daily life, from improving communication to facilitating learning and problem-solving. Mobile phones, as essential daily companions, represent the most effective and accessible deployment platform for MLLMs, enabling seamless integration into everyday tasks. However, deploying MLLMs on mobile phones presents challenges due to limitations in memory size and computational capability, making it difficult to achieve smooth and real-time processing without extensive optimization. In this paper, we present BlueLM-V-3B, an algorithm and system co-design approach specifically tailored for the efficient deployment of MLLMs on mobile platforms. To be specific, we redesign the dynamic resolution scheme adopted by mainstream MLLMs and implement system optimization for hardware-aware deployment to optimize model inference on mobile phones. BlueLM-V-3B boasts the following key highlights: (1) Small Size: BlueLM-V-3B features a language model with 2.7B parameters and a vision encoder with 400M parameters. (2) Fast Speed: BlueLM-V-3B achieves a generation speed of 24.4 token/s on the MediaTek Dimensity 9300 processor with 4-bit LLM weight quantization. (3) Strong Performance: BlueLM-V-3B has attained the highest average score of 66.1 on the OpenCompass benchmark among models with $\leq$ 4B parameters and surpassed a series of models with much larger parameter sizes (e.g., MiniCPM-V-2.6, InternVL2-8B).
DSNet: A Novel Way to Use Atrous Convolutions in Semantic Segmentation
Jun 06, 2024



Atrous convolutions are employed as a method to increase the receptive field in semantic segmentation tasks. However, in previous works of semantic segmentation, it was rarely employed in the shallow layers of the model. We revisit the design of atrous convolutions in modern convolutional neural networks (CNNs), and demonstrate that the concept of using large kernels to apply atrous convolutions could be a more powerful paradigm. We propose three guidelines to apply atrous convolutions more efficiently. Following these guidelines, we propose DSNet, a Dual-Branch CNN architecture, which incorporates atrous convolutions in the shallow layers of the model architecture, as well as pretraining the nearly entire encoder on ImageNet to achieve better performance. To demonstrate the effectiveness of our approach, our models achieve a new state-of-the-art trade-off between accuracy and speed on ADE20K, Cityscapes and BDD datasets. Specifically, DSNet achieves 40.0% mIOU with inference speed of 179.2 FPS on ADE20K, and 80.4% mIOU with speed of 81.9 FPS on Cityscapes. Source code and models are available at Github: https://github.com/takaniwa/DSNet.