 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating and Mitigating the Multimodal Hallucination Snowballing in Large Vision-Language Models
Paper and Code

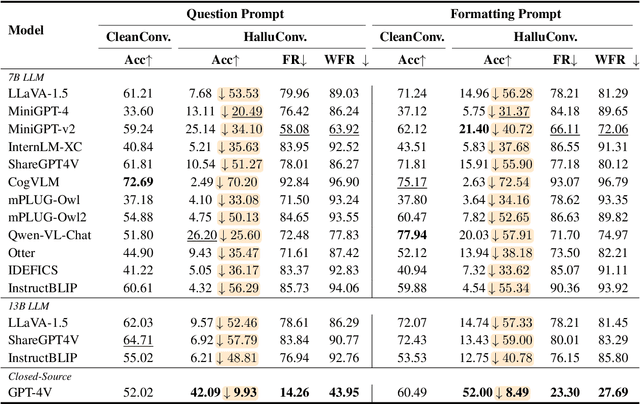
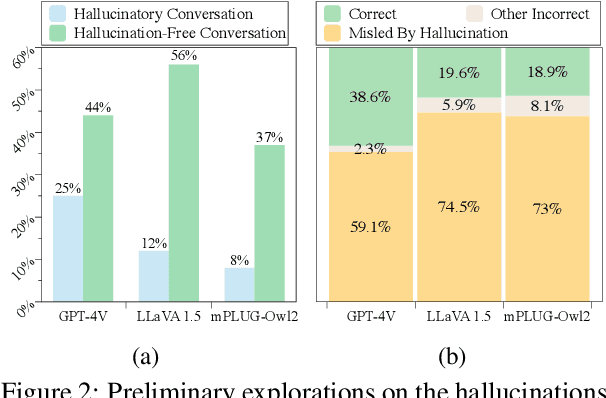
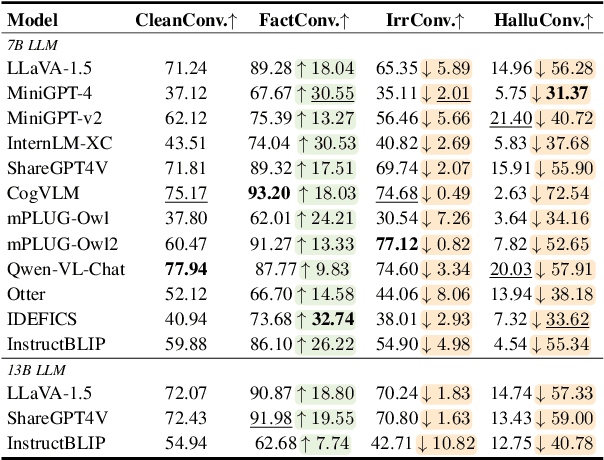
Though advanced in understanding visual information with human languages, Large Vision-Language Models (LVLMs) still suffer from multimodal hallucinations. A natural concern is that during multimodal interaction, the generated hallucinations could influence the LVLMs' subsequent generation. Thus, we raise a question: When presented with a query relevant to the previously generated hallucination, will LVLMs be misled and respond incorrectly, even though the ground visual information exists? To answer this, we propose a framework called MMHalSnowball to evaluate LVLMs' behaviors when encountering generated hallucinations, where LVLMs are required to answer specific visual questions within a curated hallucinatory conversation. Crucially, our experiment shows that the performance of open-source LVLMs drops by at least $31\%$, indicating that LVLMs are prone to accept the generated hallucinations and make false claims that they would not have supported without distractions. We term this phenomenon Multimodal Hallucination Snowballing. To mitigate this, we further propose a training-free method called Residual Visual Decoding, where we revise the output distribution of LVLMs with the one derived from the residual visual input, providing models with direct access to the visual information. Experiments show that our method can mitigate more than $24\%$ of the snowballed multimodal hallucination while maintaining capabilities.