 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Large Language Model Attribution through Self-Improving
Paper and Code
Oct 17, 2024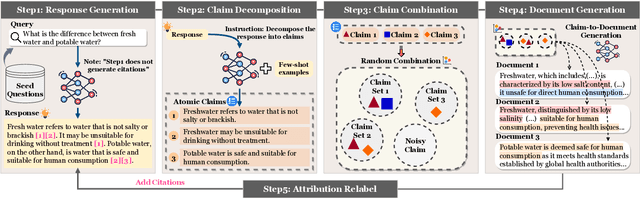
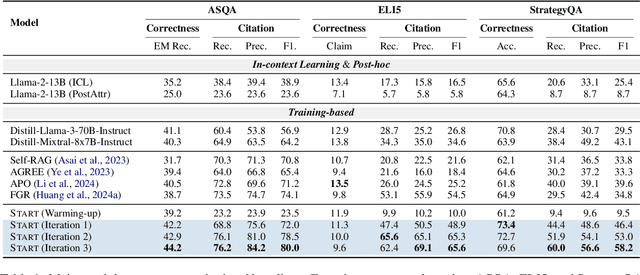
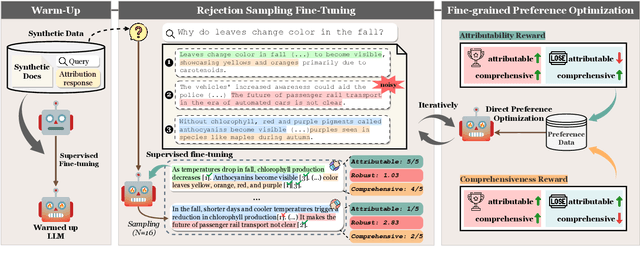
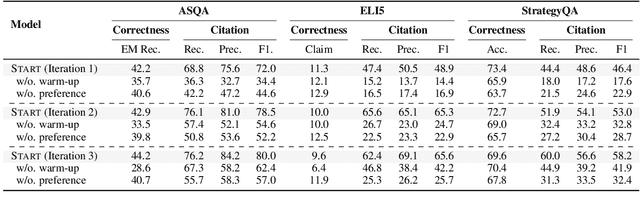
Teaching large language models (LLMs) to generate text with citations to evidence sources can mitigate hallucinations and enhance verifiability in information-seeking systems. However, improving this capability requires high-quality attribution data, which is costly and labor-intensive. Inspired by recent advances in self-improvement that enhance LLMs without manual annotation, we present START, a Self-Taught AttRibuTion framework for iteratively improving the attribution capability of LLMs. First, to prevent models from stagnating due to initially insufficient supervision signals, START leverages the model to self-construct synthetic training data for warming up. To further self-improve the model's attribution ability, START iteratively utilizes fine-grained preference supervision signals constructed from its sampled responses to encourage robust, comprehensive, and attributable generation. Experiments on three open-domain question-answering datasets, covering long-form QA and multi-step reasoning, demonstrate significant performance gains of 25.13% on average without relying on human annotations and more advanced models. Further analysis reveals that START excels in aggregating information across multiple sources.