 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoIdeator: Evolving Scientific Ideas through Checklist-Grounded Reinforcement Learning
Mar 23, 2026Scientific idea generation is a cornerstone of autonomous knowledge discovery, yet the iterative evolution required to transform initial concepts into high-quality research proposals remains a formidable challenge for Large Language Models (LLMs). Existing Reinforcement Learning (RL) paradigms often rely on rubric-based scalar rewards that provide global quality scores but lack actionable granularity. Conversely, language-based refinement methods are typically confined to inference-time prompting, targeting models that are not explicitly optimized to internalize such critiques. To bridge this gap, we propose \textbf{EvoIdeator}, a framework that facilitates the evolution of scientific ideas by aligning the RL training objective with \textbf{checklist-grounded feedback}. EvoIdeator leverages a structured judge model to generate two synergistic signals: (1) \emph{lexicographic rewards} for multi-dimensional optimization, and (2) \emph{fine-grained language feedback} that offers span-level critiques regarding grounding, feasibility, and methodological rigor. By integrating these signals into the RL loop, we condition the policy to systematically utilize precise feedback during both optimization and inference. Extensive experiments demonstrate that EvoIdeator, built on Qwen3-4B, significantly outperforms much larger frontier models across key scientific metrics. Crucially, the learned policy exhibits strong generalization to diverse external feedback sources without further fine-tuning, offering a scalable and rigorous path toward self-refining autonomous ideation.
EvoScientist: Towards Multi-Agent Evolving AI Scientists for End-to-End Scientific Discovery
Mar 09, 2026The increasing adoption of Large Language Models (LLMs) has enabled AI scientists to perform complex end-to-end scientific discovery tasks requiring coordination of specialized roles, including idea generation and experimental execution. However, most state-of-the-art AI scientist systems rely on static, hand-designed pipelines and fail to adapt based on accumulated interaction histories. As a result, these systems overlook promising research directions, repeat failed experiments, and pursue infeasible ideas. To address this, we introduce EvoScientist, an evolving multi-agent AI scientist framework that continuously improves research strategies through persistent memory and self-evolution. EvoScientist comprises three specialized agents: a Researcher Agent (RA) for scientific idea generation, an Engineer Agent (EA) for experiment implementation and execution, and an Evolution Manager Agent (EMA) that distills insights from prior interactions into reusable knowledge. EvoScientist contains two persistent memory modules: (i) an ideation memory, which summarizes feasible research directions from top-ranked ideas while recording previously unsuccessful directions; and (ii) an experimentation memory, which captures effective data processing and model training strategies derived from code search trajectories and best-performing implementations. These modules enable the RA and EA to retrieve relevant prior strategies, improving idea quality and code execution success rates over time. Experiments show that EvoScientist outperforms 7 open-source and commercial state-of-the-art systems in scientific idea generation, achieving higher novelty, feasibility, relevance, and clarity via automatic and human evaluation. EvoScientist also substantially improves code execution success rates through multi-agent evolution, demonstrating persistent memory's effectiveness for end-to-end scientific discovery.
Knowledge-Augmented Question Error Correction for Chinese Question Answer System with QuestionRAG
Nov 05, 2025Input errors in question-answering (QA) systems often lead to incorrect responses. Large language models (LLMs) struggle with this task, frequently failing to interpret user intent (misinterpretation) or unnecessarily altering the original question's structure (over-correction). We propose QuestionRAG, a framework that tackles these problems. To address misinterpretation, it enriches the input with external knowledge (e.g., search results, related entities). To prevent over-correction, it uses reinforcement learning (RL) to align the model's objective with precise correction, not just paraphrasing. Our results demonstrate that knowledge augmentation is critical for understanding faulty questions. Furthermore, RL-based alignment proves significantly more effective than traditional supervised fine-tuning (SFT), boosting the model's ability to follow instructions and generalize. By integrating these two strategies, QuestionRAG unlocks the full potential of LLMs for the question correction task.
XTransplant: A Probe into the Upper Bound Performance of Multilingual Capability and Culture Adaptability in LLMs via Mutual Cross-lingual Feed-forward Transplantation
Dec 17, 2024Current large language models (LLMs) often exhibit imbalances in multilingual capabilities and cultural adaptability, largely due to their English-centric pretraining data. To address this imbalance, we propose a probing method named XTransplant that explores cross-lingual latent interactions via cross-lingual feed-forward transplantation during inference stage, with the hope of enabling the model to leverage the strengths of both English and non-English languages. Through extensive pilot experiments, we empirically prove that both the multilingual capabilities and cultural adaptability of LLMs hold the potential to be significantly improved by XTransplant, respectively from En -> non-En and non-En -> En, highlighting the underutilization of current LLMs' multilingual potential. And the patterns observed in these pilot experiments further motivate an offline scaling inference strategy, which demonstrates consistent performance improvements in multilingual and culture-aware tasks, sometimes even surpassing multilingual supervised fine-tuning. And we do hope our further analysis and discussion could help gain deeper insights into XTransplant mechanism.
PReGAN: Answer Oriented Passage Ranking with Weakly Supervised GAN
Jul 05, 2022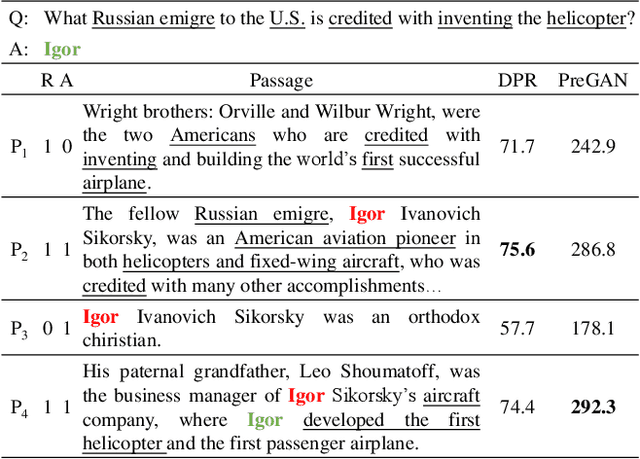
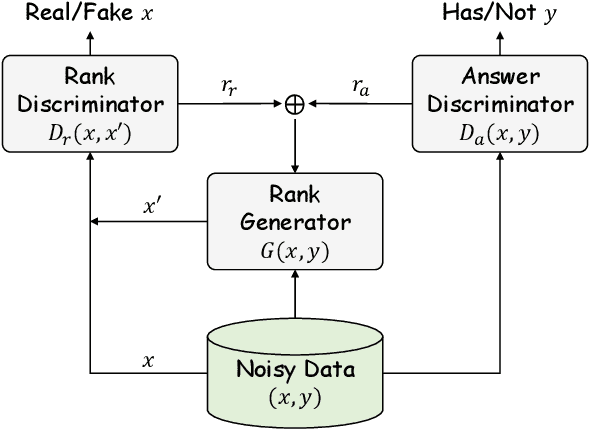
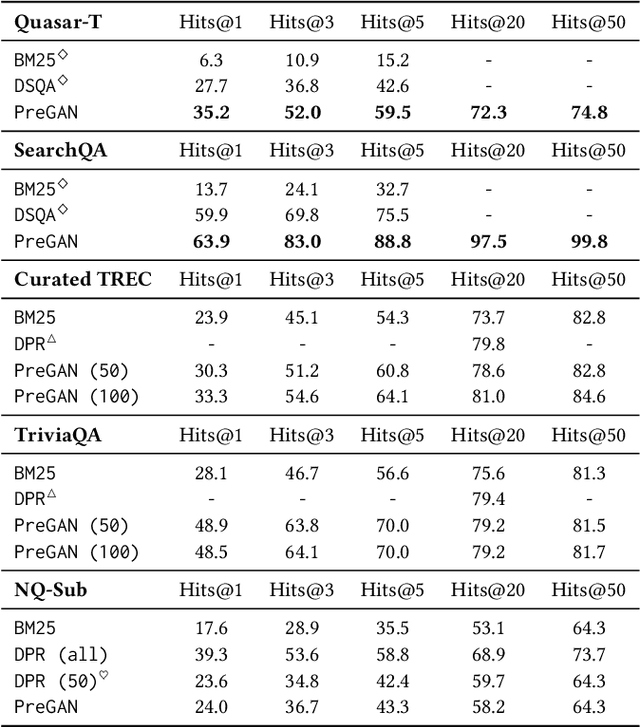
Beyond topical relevance, passage ranking for open-domain factoid question answering also requires a passage to contain an answer (answerability). While a few recent studies have incorporated some reading capability into a ranker to account for answerability, the ranker is still hindered by the noisy nature of the training data typically available in this area, which considers any passage containing an answer entity as a positive sample. However, the answer entity in a passage is not necessarily mentioned in relation with the given question. To address the problem, we propose an approach called \ttt{PReGAN} for Passage Reranking based on Generative Adversarial Neural networks, which incorporates a discriminator on answerability, in addition to a discriminator on topical relevance. The goal is to force the generator to rank higher a passage that is topically relevant and contains an answer. Experiments on five public datasets show that \ttt{PReGAN} can better rank appropriate passages, which in turn, boosts the effectiveness of QA systems, and outperforms the existing approaches without using external data.
Variance Reduction for Deep Q-Learning using Stochastic Recursive Gradient
Jul 25, 2020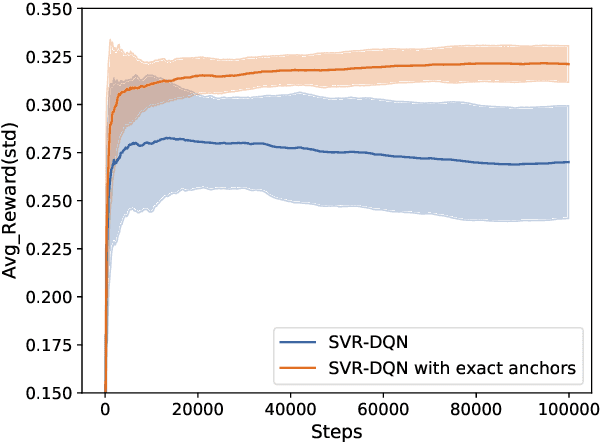
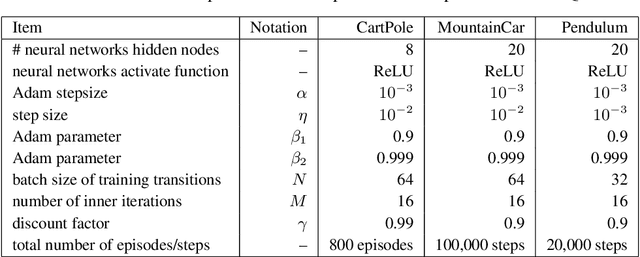
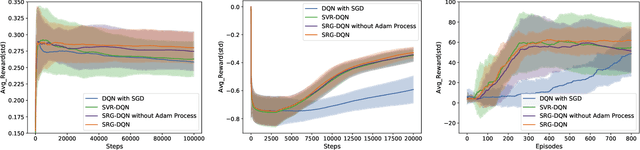

Deep Q-learning algorithms often suffer from poor gradient estimations with an excessive variance, resulting in unstable training and poor sampling efficiency. Stochastic variance-reduced gradient methods such as SVRG have been applied to reduce the estimation variance (Zhao et al. 2019). However, due to the online instance generation nature of reinforcement learning, directly applying SVRG to deep Q-learning is facing the problem of the inaccurate estimation of the anchor points, which dramatically limits the potentials of SVRG. To address this issue and inspired by the recursive gradient variance reduction algorithm SARAH (Nguyen et al. 2017), this paper proposes to introduce the recursive framework for updating the stochastic gradient estimates in deep Q-learning, achieving a novel algorithm called SRG-DQN. Unlike the SVRG-based algorithms, SRG-DQN designs a recursive update of the stochastic gradient estimate. The parameter update is along an accumulated direction using the past stochastic gradient information, and therefore can get rid of the estimation of the full gradients as the anchors. Additionally, SRG-DQN involves the Adam process for further accelerating the training process. Theoretical analysis and the experimental results on well-known reinforcement learning tasks demonstrate the efficiency and effectiveness of the proposed SRG-DQN algorithm.
Convolutional Hierarchical Attention Network for Query-Focused Video Summarization
Feb 15, 2020

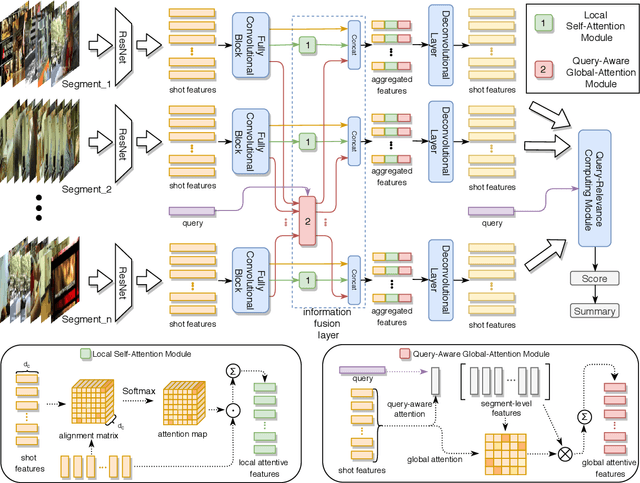
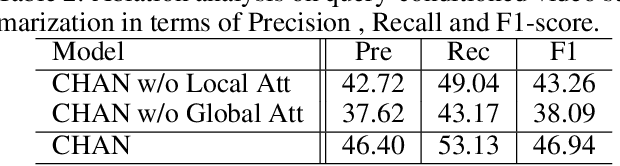
Previous approaches for video summarization mainly concentrate on finding the most diverse and representative visual contents as video summary without considering the user's preference. This paper addresses the task of query-focused video summarization, which takes user's query and a long video as inputs and aims to generate a query-focused video summary. In this paper, we consider the task as a problem of computing similarity between video shots and query. To this end, we propose a method, named Convolutional Hierarchical Attention Network (CHAN), which consists of two parts: feature encoding network and query-relevance computing module. In the encoding network, we employ a convolutional network with local self-attention mechanism and query-aware global attention mechanism to learns visual information of each shot. The encoded features will be sent to query-relevance computing module to generate queryfocused video summary. Extensive experiments on the benchmark dataset demonstrate the competitive performance and show the effectiveness of our approach.
Generative Question Refinement with Deep Reinforcement Learning in Retrieval-based QA System
Aug 27, 2019
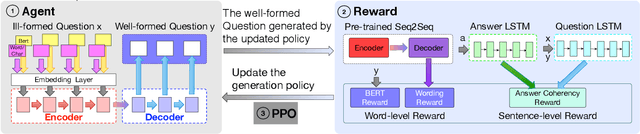

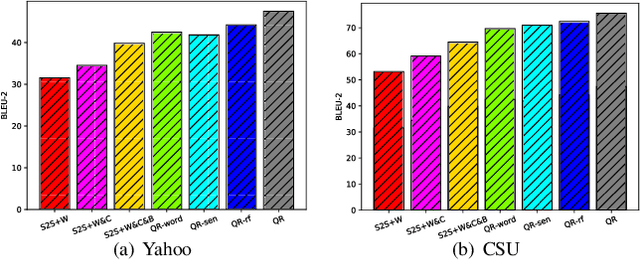
In real-world question-answering (QA) systems, ill-formed questions, such as wrong words, ill word order, and noisy expressions, are common and may prevent the QA systems from understanding and answering them accurately. In order to eliminate the effect of ill-formed questions, we approach the question refinement task and propose a unified model, QREFINE, to refine the ill-formed questions to well-formed question. The basic idea is to learn a Seq2Seq model to generate a new question from the original one. To improve the quality and retrieval performance of the generated questions, we make two major improvements: 1) To better encode the semantics of ill-formed questions, we enrich the representation of questions with character embedding and the recent proposed contextual word embedding such as BERT, besides the traditional context-free word embeddings; 2) To make it capable to generate desired questions, we train the model with deep reinforcement learning techniques that considers an appropriate wording of the generation as an immediate reward and the correlation between generated question and answer as time-delayed long-term rewards. Experimental results on real-world datasets show that the proposed QREFINE method can generate refined questions with more readability but fewer mistakes than the original questions provided by users. Moreover, the refined questions also significantly improve the accuracy of answer retrieval.
Learning Representation Mapping for Relation Detection in Knowledge Base Question Answering
Jul 17, 2019
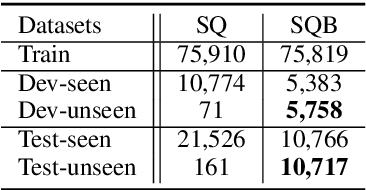
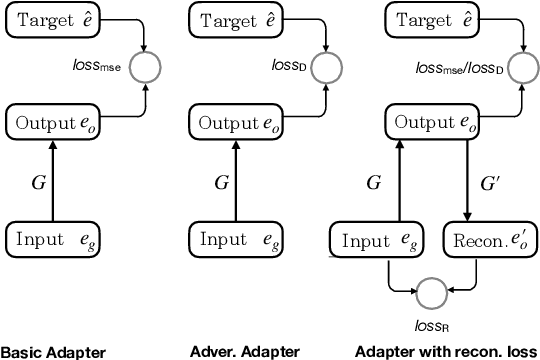

Relation detection is a core step in many natural language process applications including knowledge base question answering. Previous efforts show that single-fact questions could be answered with high accuracy. However, one critical problem is that current approaches only get high accuracy for questions whose relations have been seen in the training data. But for unseen relations, the performance will drop rapidly. The main reason for this problem is that the representations for unseen relations are missing. In this paper, we propose a simple mapping method, named representation adapter, to learn the representation mapping for both seen and unseen relations based on previously learned relation embedding. We employ the adversarial objective and the reconstruction objective to improve the mapping performance. We re-organize the popular SimpleQuestion dataset to reveal and evaluate the problem of detecting unseen relations. Experiments show that our method can greatly improve the performance of unseen relations while the performance for those seen part is kept comparable to the state-of-the-art. Our code and data are available at https://github.com/wudapeng268/KBQA-Adapter.
Zero-shot User Intent Detection via Capsule Neural Networks
Sep 02, 2018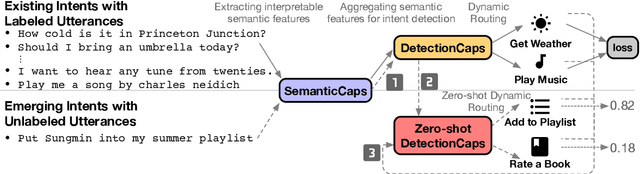
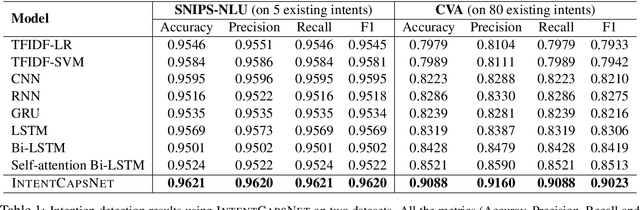
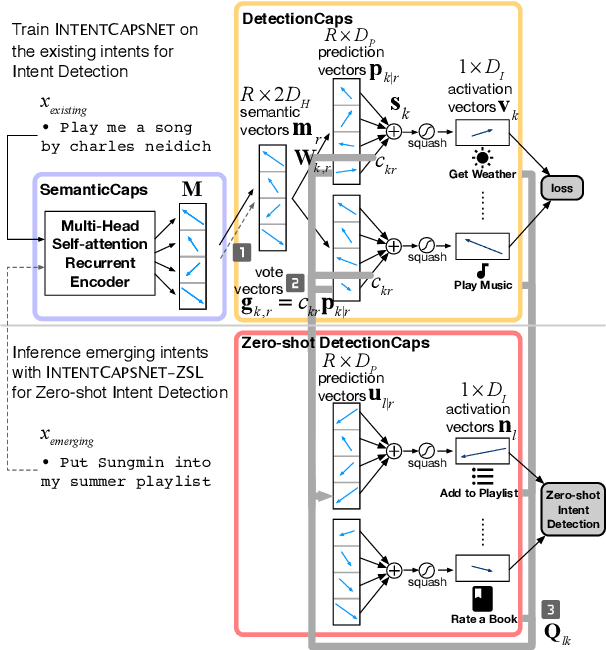
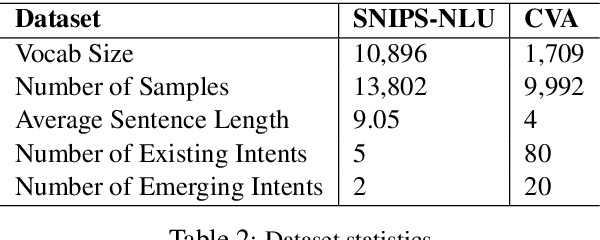
User intent detection plays a critical role in question-answering and dialog systems. Most previous works treat intent detection as a classification problem where utterances are labeled with predefined intents. However, it is labor-intensive and time-consuming to label users' utterances as intents are diversely expressed and novel intents will continually be involved. Instead, we study the zero-shot intent detection problem, which aims to detect emerging user intents where no labeled utterances are currently available. We propose two capsule-based architectures: INTENT-CAPSNET that extracts semantic features from utterances and aggregates them to discriminate existing intents, and INTENTCAPSNET-ZSL which gives INTENTCAPSNET the zero-shot learning ability to discriminate emerging intents via knowledge transfer from existing intents. Experiments on two real-world datasets show that our model not only can better discriminate diversely expressed existing intents, but is also able to discriminate emerging intents when no labeled utterances are available.