 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Reduction for Deep Q-Learning using Stochastic Recursive Gradient
Paper and Code
Jul 25, 2020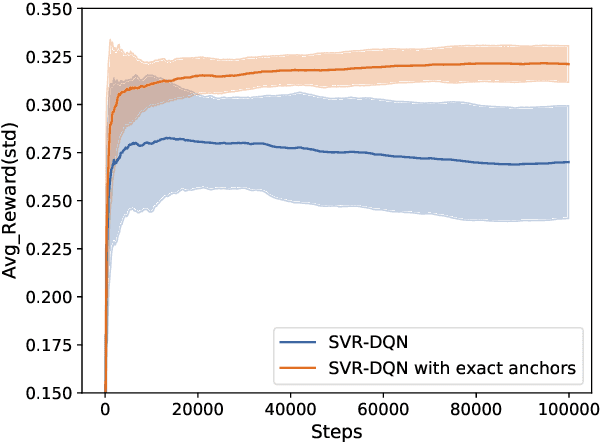
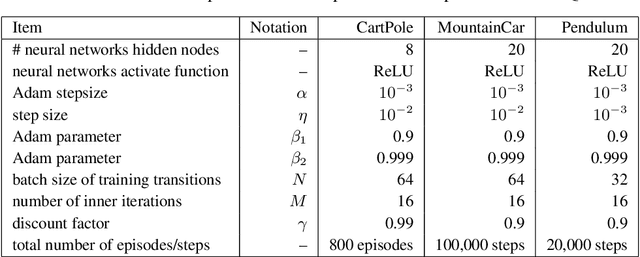
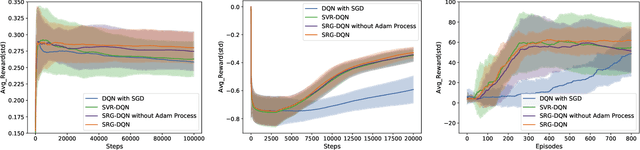

Deep Q-learning algorithms often suffer from poor gradient estimations with an excessive variance, resulting in unstable training and poor sampling efficiency. Stochastic variance-reduced gradient methods such as SVRG have been applied to reduce the estimation variance (Zhao et al. 2019). However, due to the online instance generation nature of reinforcement learning, directly applying SVRG to deep Q-learning is facing the problem of the inaccurate estimation of the anchor points, which dramatically limits the potentials of SVRG. To address this issue and inspired by the recursive gradient variance reduction algorithm SARAH (Nguyen et al. 2017), this paper proposes to introduce the recursive framework for updating the stochastic gradient estimates in deep Q-learning, achieving a novel algorithm called SRG-DQN. Unlike the SVRG-based algorithms, SRG-DQN designs a recursive update of the stochastic gradient estimate. The parameter update is along an accumulated direction using the past stochastic gradient information, and therefore can get rid of the estimation of the full gradients as the anchors. Additionally, SRG-DQN involves the Adam process for further accelerating the training process. Theoretical analysis and the experimental results on well-known reinforcement learning tasks demonstrate the efficiency and effectiveness of the proposed SRG-DQN algorithm.