 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow-to-Deep Training for Neural Machine Translation
Paper and Code
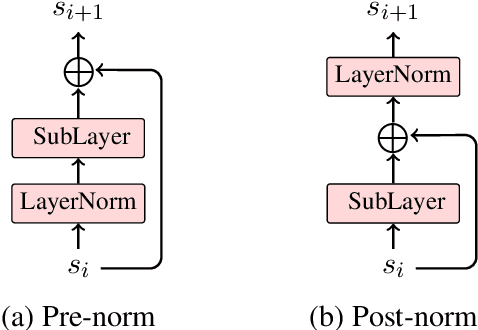
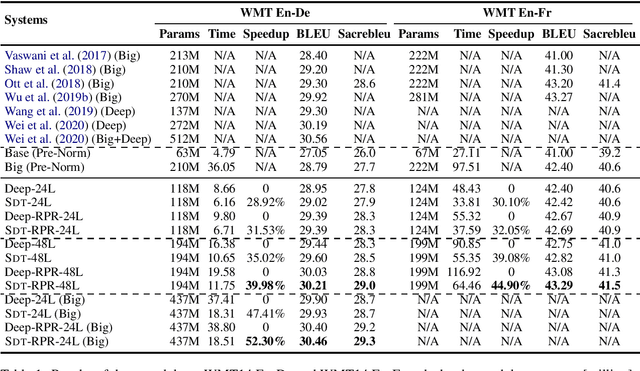


Deep encoders have been proven to be effective in improving neural machine translation (NMT) systems, but training an extremely deep encoder is time consuming. Moreover, why deep models help NMT is an open question. In this paper, we investigate the behavior of a well-tuned deep Transformer system. We find that stacking layers is helpful in improving the representation ability of NMT models and adjacent layers perform similarly. This inspires us to develop a shallow-to-deep training method that learns deep models by stacking shallow models. In this way, we successfully train a Transformer system with a 54-layer encoder. Experimental results on WMT'16 English-German and WMT'14 English-French translation tasks show that it is $1.4$ $\times$ faster than training from scratch, and achieves a BLEU score of $30.33$ and $43.29$ on two tasks. The code is publicly available at https://github.com/libeineu/SDT-Training/.