 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification in Medical Image Segmentation with Multi-decoder U-Net
Paper and Code
Sep 15, 2021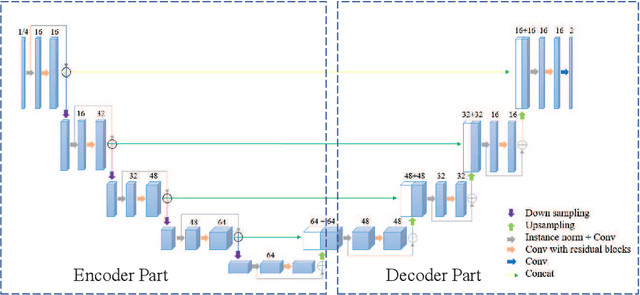
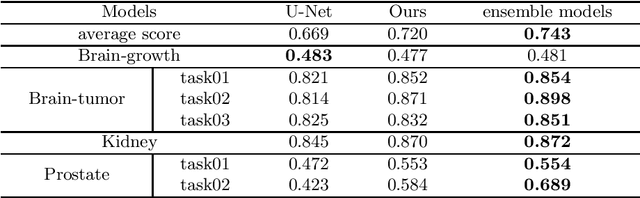
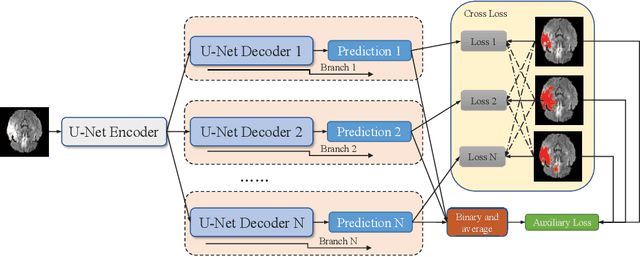
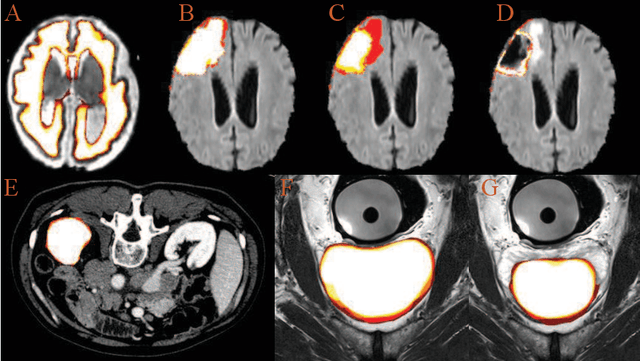
Accurate medical image segmentation is crucial for diagnosis and analysis. However, the models without calibrated uncertainty estimates might lead to errors in downstream analysis and exhibit low levels of robustness. Estimating the uncertainty in the measurement is vital to making definite, informed conclusions. Especially, it is difficult to make accurate predictions on ambiguous areas and focus boundaries for both models and radiologists, even harder to reach a consensus with multiple annotations. In this work, the uncertainty under these areas is studied, which introduces significant information with anatomical structure and is as important as segmentation performance. We exploit the medical image segmentation uncertainty quantification by measuring segmentation performance with multiple annotations in a supervised learning manner and propose a U-Net based architecture with multiple decoders, where the image representation is encoded with the same encoder, and segmentation referring to each annotation is estimated with multiple decoders. Nevertheless, a cross-loss function is proposed for bridging the gap between different branches. The proposed architecture is trained in an end-to-end manner and able to improve predictive uncertainty estimates. The model achieves comparable performance with fewer parameters to the integrated training model that ranked the runner-up in the MICCAI-QUBIQ 2020 challenge.