 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIME: Planning and Retrieval-Integrated Memory for Enhanced Reasoning
Sep 26, 2025Inspired by the dual-process theory of human cognition from \textit{Thinking, Fast and Slow}, we introduce \textbf{PRIME} (Planning and Retrieval-Integrated Memory for Enhanced Reasoning), a multi-agent reasoning framework that dynamically integrates \textbf{System 1} (fast, intuitive thinking) and \textbf{System 2} (slow, deliberate thinking). PRIME first employs a Quick Thinking Agent (System 1) to generate a rapid answer; if uncertainty is detected, it then triggers a structured System 2 reasoning pipeline composed of specialized agents for \textit{planning}, \textit{hypothesis generation}, \textit{retrieval}, \textit{information integration}, and \textit{decision-making}. This multi-agent design faithfully mimics human cognitive processes and enhances both efficiency and accuracy. Experimental results with LLaMA 3 models demonstrate that PRIME enables open-source LLMs to perform competitively with state-of-the-art closed-source models like GPT-4 and GPT-4o on benchmarks requiring multi-hop and knowledge-grounded reasoning. This research establishes PRIME as a scalable solution for improving LLMs in domains requiring complex, knowledge-intensive reasoning.
MCQG-SRefine: Multiple Choice Question Generation and Evaluation with Iterative Self-Critique, Correction, and Comparison Feedback
Oct 17, 2024



Automatic question generation (QG) is essential for AI and NLP, particularly in intelligent tutoring, dialogue systems, and fact verification. Generating multiple-choice questions (MCQG) for professional exams, like the United States Medical Licensing Examination (USMLE), is particularly challenging, requiring domain expertise and complex multi-hop reasoning for high-quality questions. However, current large language models (LLMs) like GPT-4 struggle with professional MCQG due to outdated knowledge, hallucination issues, and prompt sensitivity, resulting in unsatisfactory quality and difficulty. To address these challenges, we propose MCQG-SRefine, an LLM self-refine-based (Critique and Correction) framework for converting medical cases into high-quality USMLE-style questions. By integrating expert-driven prompt engineering with iterative self-critique and self-correction feedback, MCQG-SRefine significantly enhances human expert satisfaction regarding both the quality and difficulty of the questions. Furthermore, we introduce an LLM-as-Judge-based automatic metric to replace the complex and costly expert evaluation process, ensuring reliable and expert-aligned assessments.
RiTeK: A Dataset for Large Language Models Complex Reasoning over Textual Knowledge Graphs
Oct 17, 2024



Answering complex real-world questions often requires accurate retrieval from textual knowledge graphs (TKGs). The scarcity of annotated data, along with intricate topological structures, makes this task particularly challenging. As the nature of relational path information could enhance the inference ability of Large Language Models (LLMs), efficiently retrieving more complex relational path information from TKGs presents another key challenge. To tackle these challenges, we first develop a Dataset for LLMs Complex Reasoning over Textual Knowledge Graphs (RiTeK) with a broad topological structure coverage.We synthesize realistic user queries that integrate diverse topological structures, relational information, and complex textual descriptions. We conduct rigorous expert evaluation to validate the quality of our synthesized queries. And then, we introduce an enhanced Monte Carlo Tree Search (MCTS) method, Relational MCTS, to automatically extract relational path information from textual graphs for specific queries. Our dataset mainly covers the medical domain as the relation types and entity are complex and publicly available. Experimental results indicate that RiTeK poses significant challenges for current retrieval and LLM systems, while the proposed Relational MCTS method enhances LLM inference ability and achieves state-of-the-art performance on RiTeK.
MedQA-CS: Benchmarking Large Language Models Clinical Skills Using an AI-SCE Framework
Oct 02, 2024



Artificial intelligence (AI) and large language models (LLMs) in healthcare require advanced clinical skills (CS), yet current benchmarks fail to evaluate these comprehensively. We introduce MedQA-CS, an AI-SCE framework inspired by medical education's Objective Structured Clinical Examinations (OSCEs), to address this gap. MedQA-CS evaluates LLMs through two instruction-following tasks, LLM-as-medical-student and LLM-as-CS-examiner, designed to reflect real clinical scenarios. Our contributions include developing MedQA-CS, a comprehensive evaluation framework with publicly available data and expert annotations, and providing the quantitative and qualitative assessment of LLMs as reliable judges in CS evaluation. Our experiments show that MedQA-CS is a more challenging benchmark for evaluating clinical skills than traditional multiple-choice QA benchmarks (e.g., MedQA). Combined with existing benchmarks, MedQA-CS enables a more comprehensive evaluation of LLMs' clinical capabilities for both open- and closed-source LLMs.
SYNFAC-EDIT: Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Feb 21, 2024
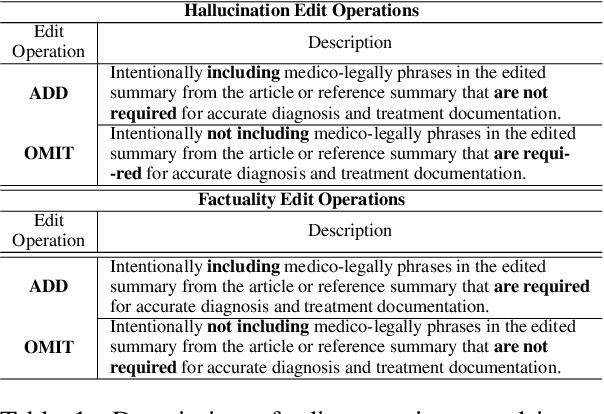

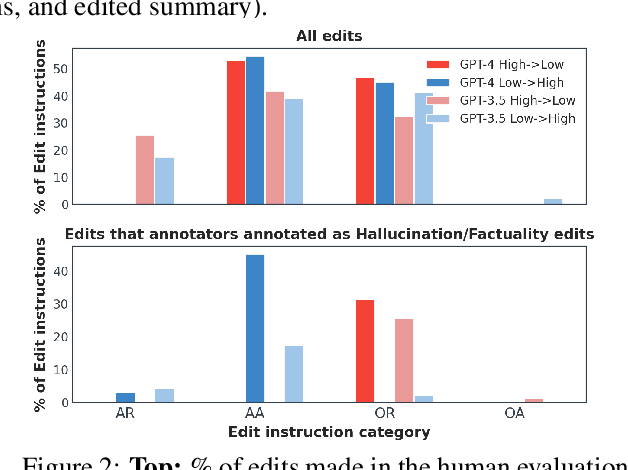
Large Language Models (LLMs) such as GPT and Llama have demonstrated significant achievements in summarization tasks but struggle with factual inaccuracies, a critical issue in clinical NLP applications where errors could lead to serious consequences. To counter the high costs and limited availability of expert-annotated data for factual alignment, this study introduces an innovative pipeline that utilizes GPT-3.5 and GPT-4 to generate high-quality feedback aimed at enhancing factual consistency in clinical note summarization. Our research primarily focuses on edit feedback, mirroring the practical scenario in which medical professionals refine AI system outputs without the need for additional annotations. Despite GPT's proven expertise in various clinical NLP tasks, such as the Medical Licensing Examination, there is scant research on its capacity to deliver expert-level edit feedback for improving weaker LMs or LLMs generation quality. This work leverages GPT's advanced capabilities in clinical NLP to offer expert-level edit feedback. Through the use of two distinct alignment algorithms (DPO and SALT) based on GPT edit feedback, our goal is to reduce hallucinations and align closely with medical facts, endeavoring to narrow the divide between AI-generated content and factual accuracy. This highlights the substantial potential of GPT edits in enhancing the alignment of clinical factuality.