 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISETHDR: A Physics-based Synthetic Radiance Dataset for High Dynamic Range Driving Scenes
Aug 22, 2024This paper describes a physics-based end-to-end software simulation for image systems. We use the software to explore sensors designed to enhance performance in high dynamic range (HDR) environments, such as driving through daytime tunnels and under nighttime conditions. We synthesize physically realistic HDR spectral radiance images and use them as the input to digital twins that model the optics and sensors of different systems. This paper makes three main contributions: (a) We create a labeled (instance segmentation and depth), synthetic radiance dataset of HDR driving scenes. (b) We describe the development and validation of the end-to-end simulation framework. (c) We present a comparative analysis of two single-shot sensors designed for HDR. We open-source both the dataset and the software.
Ray-transfer functions for camera simulation of 3D scenes with hidden lens design
Feb 23, 2022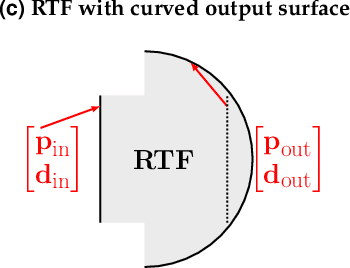

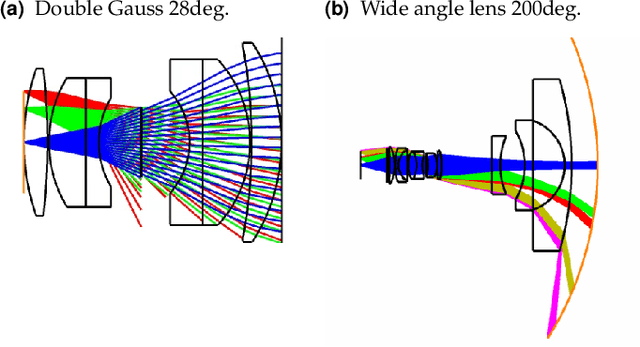
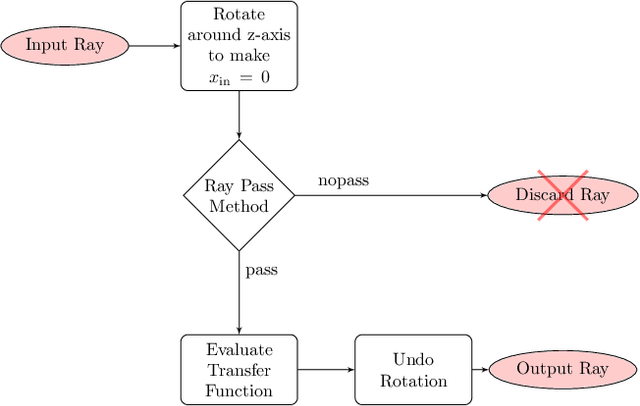
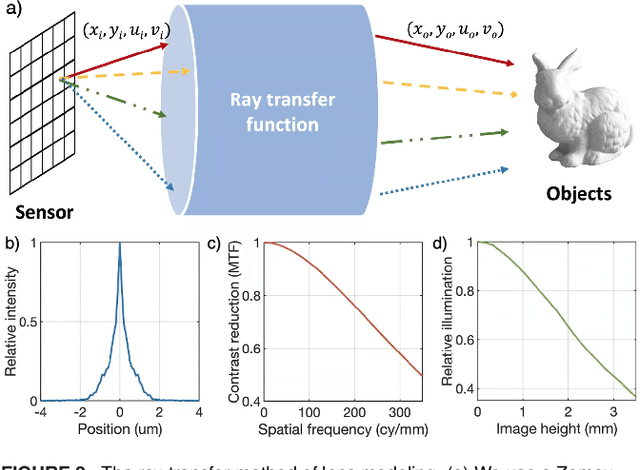
Combining image sensor simulation tools (e.g., ISETCam) with physically based ray tracing (e.g., PBRT) offers possibilities for designing and evaluating novel imaging systems as well as for synthesizing physically accurate, labeled images for machine learning. One practical limitation has been simulating the optics precisely: Lens manufacturers generally prefer to keep lens design confidential. We present a pragmatic solution to this problem using a black box lens model in Zemax; such models provide necessary optical information while preserving the lens designer's intellectual property. First, we describe and provide software to construct a polynomial ray transfer function that characterizes how rays entering the lens at any position and angle subsequently exit the lens. We implement the ray-transfer calculation as a camera model in PBRT and confirm that the PBRT ray-transfer calculations match the Zemax lens calculations for edge spread functions and relative illumination.
Accurate smartphone camera simulation using 3D scenes
Jan 28, 2022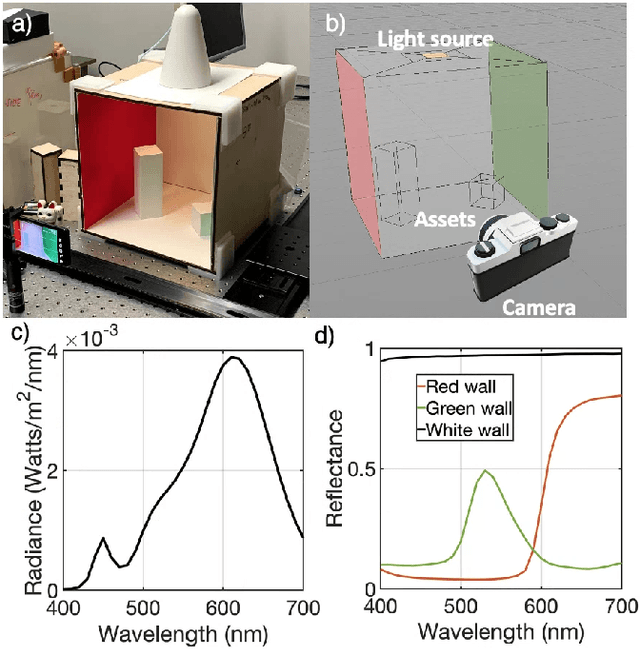
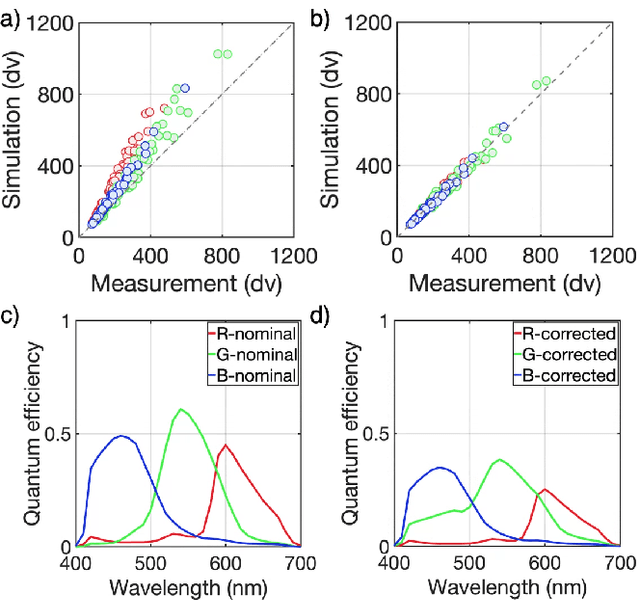
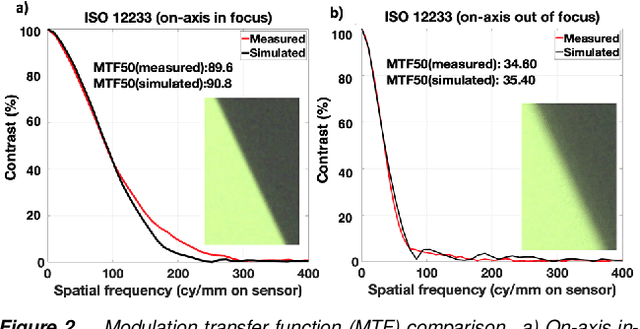
We assess the accuracy of a smartphone camera simulation. The simulation is an end-to-end analysis that begins with a physical description of a high dynamic range 3D scene and includes a specification of the optics and the image sensor. The simulation is compared to measurements of a physical version of the scene. The image system simulation accurately matched measurements of optical blur, depth of field, spectral quantum efficiency, scene inter-reflections, and sensor noise. The results support the use of image systems simulation methods for soft prototyping cameras and for producing synthetic data in machine learning applications.
Validation of image systems simulation technology using a Cornell Box
May 10, 2021
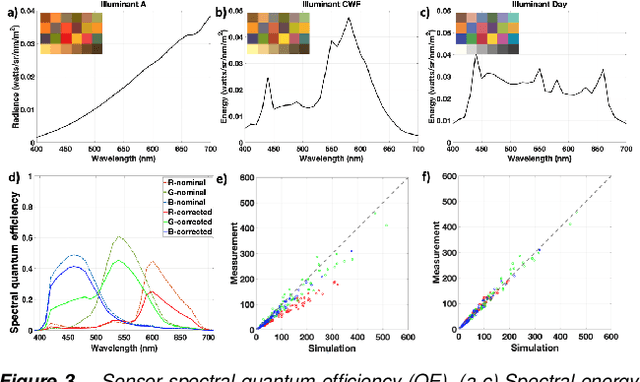

We describe and experimentally validate an end-to-end simulation of a digital camera. The simulation models the spectral radiance of 3D-scenes, formation of the spectral irradiance by multi-element optics, and conversion of the irradiance to digital values by the image sensor. We quantify the accuracy of the simulation by comparing real and simulated images of a precisely constructed, three-dimensional high dynamic range test scene. Validated end-to-end software simulation of a digital camera can accelerate innovation by reducing many of the time-consuming and expensive steps in designing, building and evaluating image systems.
ISETAuto: Detecting vehicles with depth and radiance information
Jan 07, 2021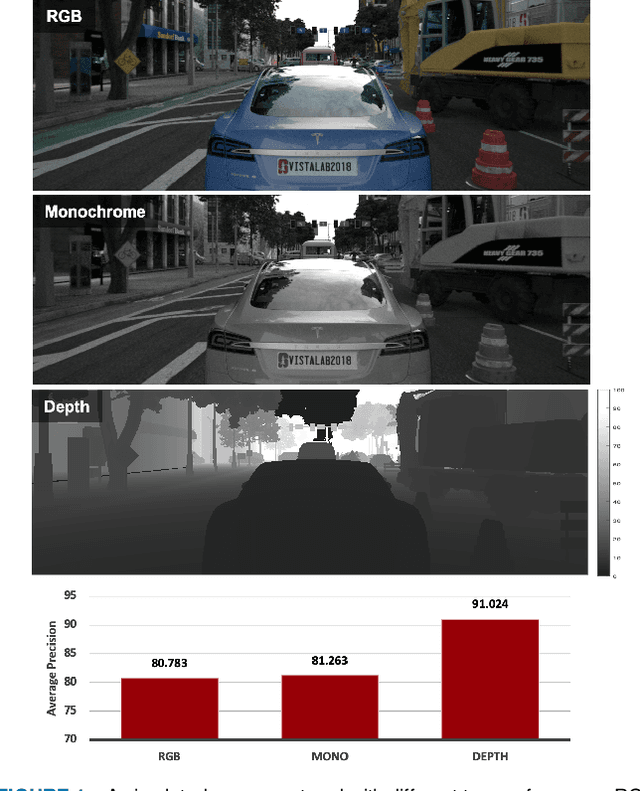

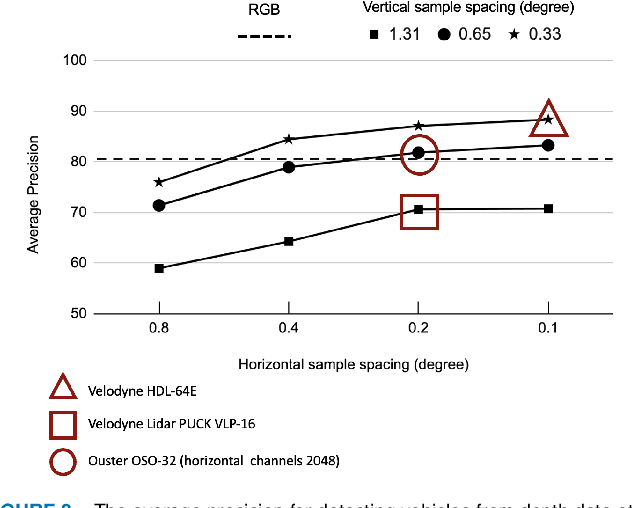
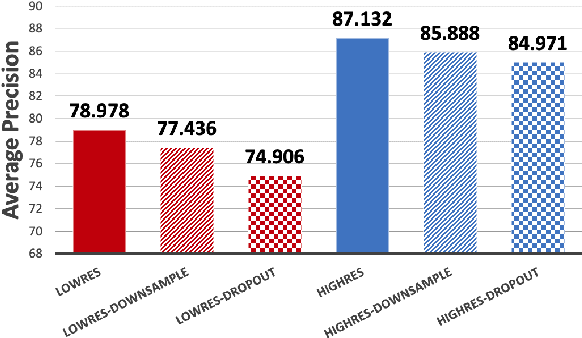
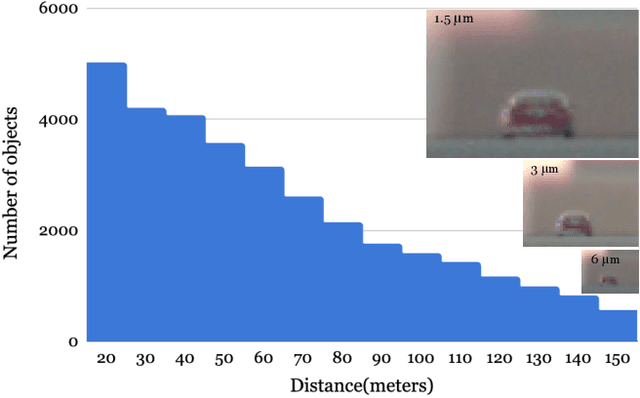
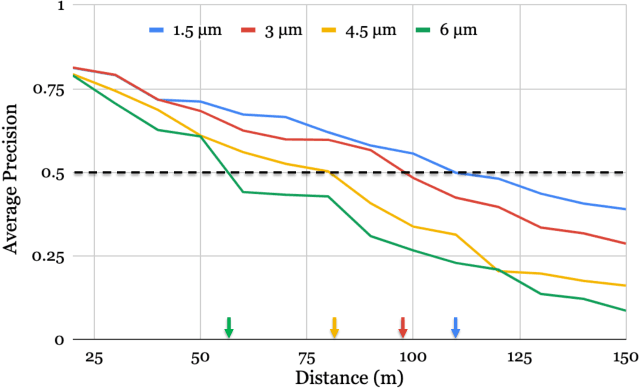
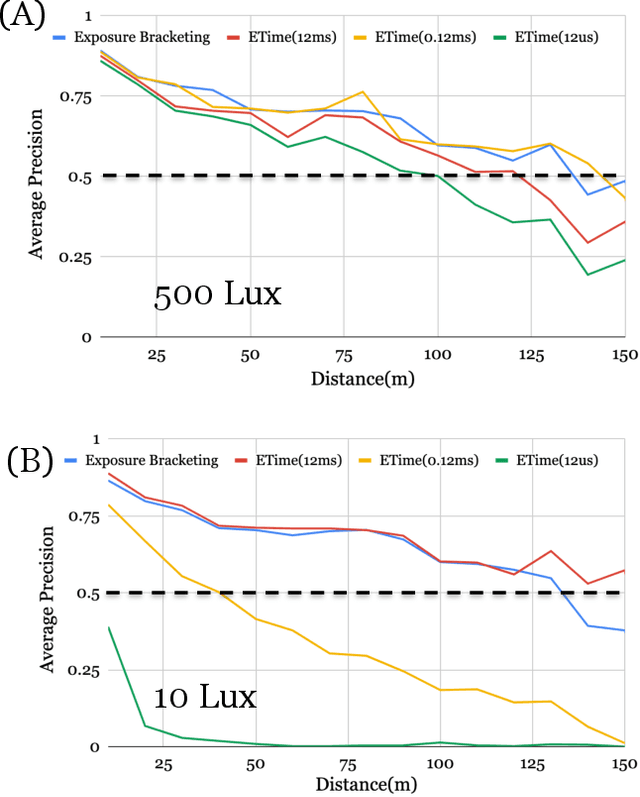
Autonomous driving applications use two types of sensor systems to identify vehicles - depth sensing LiDAR and radiance sensing cameras. We compare the performance (average precision) of a ResNet for vehicle detection in complex, daytime, driving scenes when the input is a depth map (D = d(x,y)), a radiance image (L = r(x,y)), or both [D,L]. (1) When the spatial sampling resolution of the depth map and radiance image are equal to typical camera resolutions, a ResNet detects vehicles at higher average precision from depth than radiance. (2) As the spatial sampling of the depth map declines to the range of current LiDAR devices, the ResNet average precision is higher for radiance than depth. (3) For a hybrid system that combines a depth map and radiance image, the average precision is higher than using depth or radiance alone. We established these observations in simulation and then confirmed them using realworld data. The advantage of combining depth and radiance can be explained by noting that the two type of information have complementary weaknesses. The radiance data are limited by dynamic range and motion blur. The LiDAR data have relatively low spatial resolution. The ResNet combines the two data sources effectively to improve overall vehicle detection.
Neural Network Generalization: The impact of camera parameters
Dec 08, 2019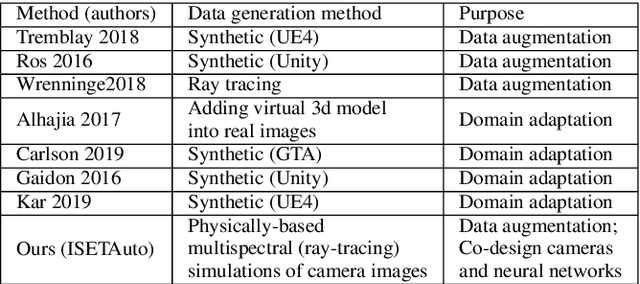
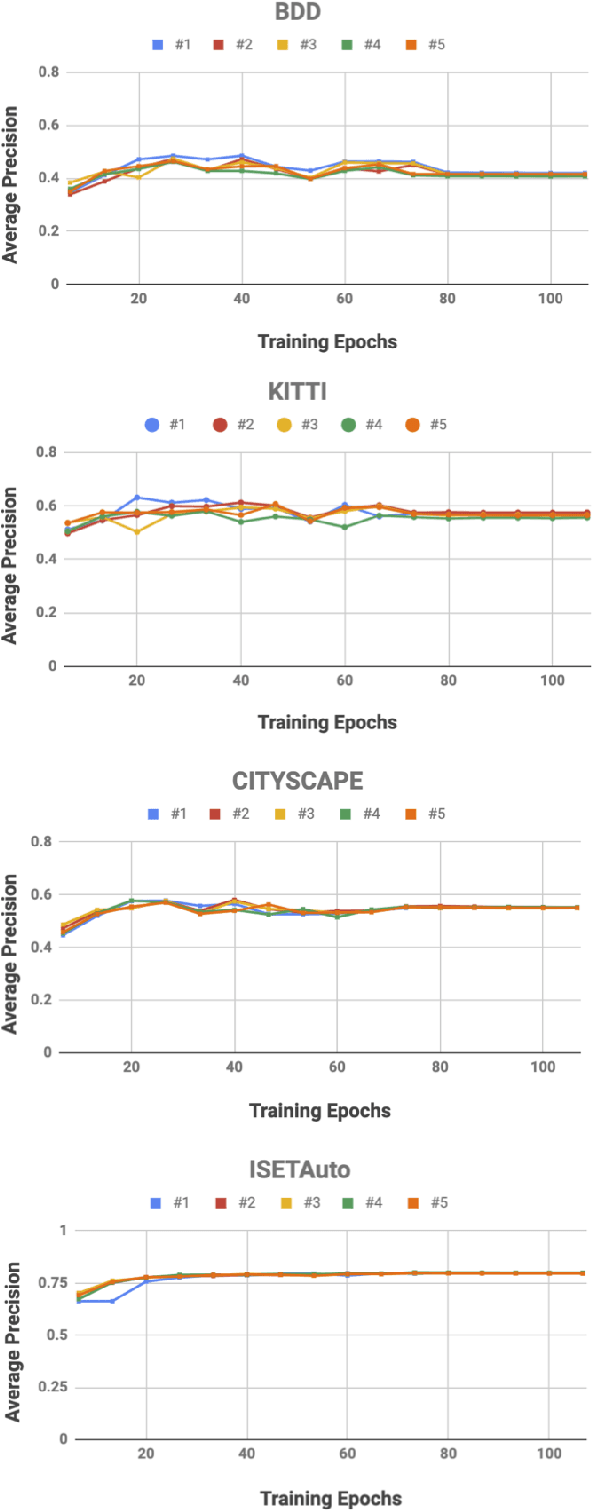
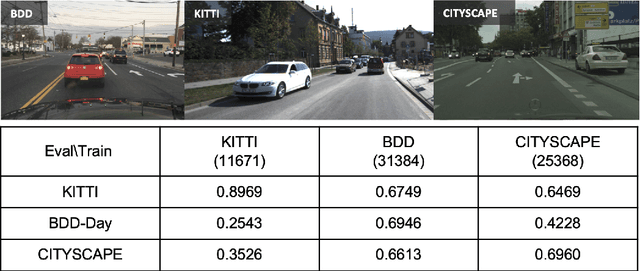
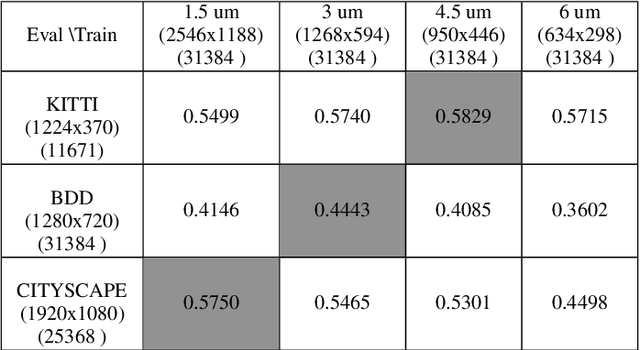
We quantify the generalization of a convolutional neural network (CNN) trained to identify cars. First, we perform a series of experiments to train the network using one image dataset - either synthetic or from a camera - and then test on a different image dataset. We show that generalization between images obtained with different cameras is roughly the same as generalization between images from a camera and ray-traced multispectral synthetic images. Second, we use ISETAuto, a soft prototyping tool that creates ray-traced multispectral simulations of camera images, to simulate sensor images with a range of pixel sizes, color filters, acquisition and post-acquisition processing. These experiments reveal how variations in specific camera parameters and image processing operations impact CNN generalization. We find that (a) pixel size impacts generalization, (b) demosaicking substantially impacts performance and generalization for shallow (8-bit) bit-depths but not deeper ones (10-bit), and (c) the network performs well using raw (not demosaicked) sensor data for 10-bit pixels.
Comparing pattern sensitivity of a convolutional neural network with an ideal observer and support vector machine
Nov 12, 2019

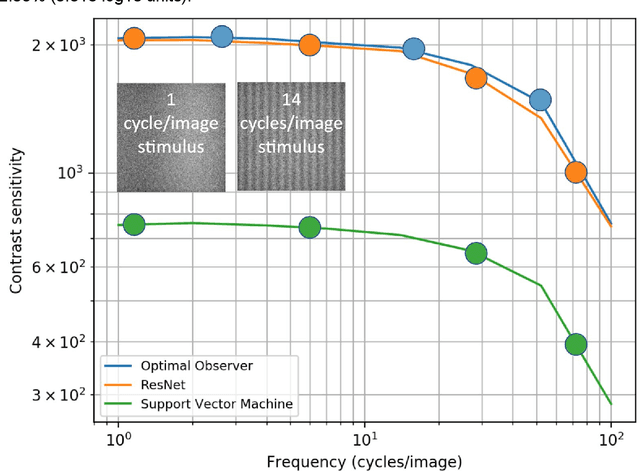

We investigate the performance of a convolutional neural network (CNN) at detecting a signal-known-exactly in Poisson noise. We compare the network performance with that of a Bayesian ideal observer (IO) that reflects the theoretical optimum in detection performance and a linear support vector machine (SVM). For several types of stimuli, including harmonics, faces, and certain regular patterns, the CNN performance matches the ideal. The SVM detection sensitivity is approximately 3x lower. For other stimuli, including random patterns and certain cellular automata, the CNN sensitivity is significantly worse than that of the ideal observer and the SVM sensitivity. Finally, when the signal position is randomized, so that the signal can appear in one of multiple locations, CNN sensitivity continues to match the ideal sensitivity.
Soft Prototyping Camera Designs for Car Detection Based on a Convolutional Neural Network
Oct 24, 2019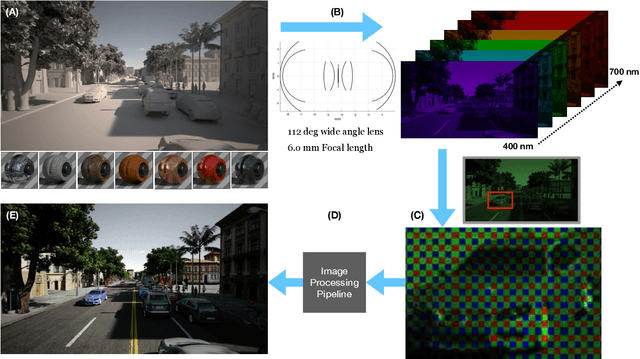
Imaging systems are increasingly used as input to convolutional neural networks (CNN) for object detection; we would like to design cameras that are optimized for this purpose. It is impractical to build different cameras and then acquire and label the necessary data for every potential camera design; creating software simulations of the camera in context (soft prototyping) is the only realistic approach. We implemented soft-prototyping tools that can quantitatively simulate image radiance and camera designs to create realistic images that are input to a convolutional neural network for car detection. We used these methods to quantify the effect that critical hardware components (pixel size), sensor control (exposure algorithms) and image processing (gamma and demosaicing algorithms) have upon average precision of car detection. We quantify (a) the relationship between pixel size and the ability to detect cars at different distances, (b) the penalty for choosing a poor exposure duration, and (c) the ability of the CNN to perform car detection for a variety of post-acquisition processing algorithms. These results show that the optimal choices for car detection are not constrained by the same metrics used for image quality in consumer photography. It is better to evaluate camera designs for CNN applications using soft prototyping with task-specific metrics rather than consumer photography metrics.
A system for generating complex physically accurate sensor images for automotive applications
Feb 12, 2019



We describe an open-source simulator that creates sensor irradiance and sensor images of typical automotive scenes in urban settings. The purpose of the system is to support camera design and testing for automotive applications. The user can specify scene parameters (e.g., scene type, road type, traffic density, time of day) to assemble a large number of random scenes from graphics assets stored in a database. The sensor irradiance is generated using quantitative computer graphics methods, and the sensor images are created using image systems sensor simulation. The synthetic sensor images have pixel level annotations; hence, they can be used to train and evaluate neural networks for imaging tasks, such as object detection and classification. The end-to-end simulation system supports quantitative assessment, from scene to camera to network accuracy, for automotive applications.
Learning the image processing pipeline
May 30, 2016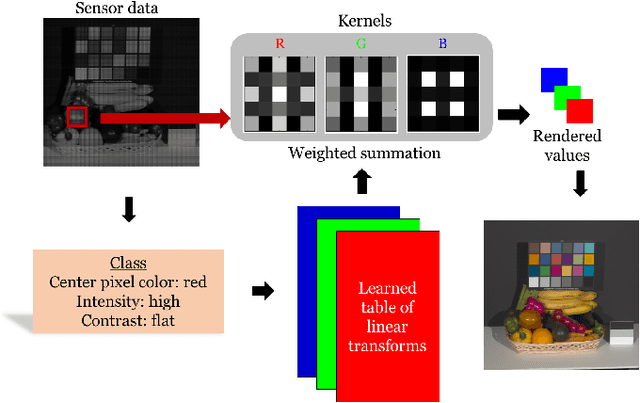
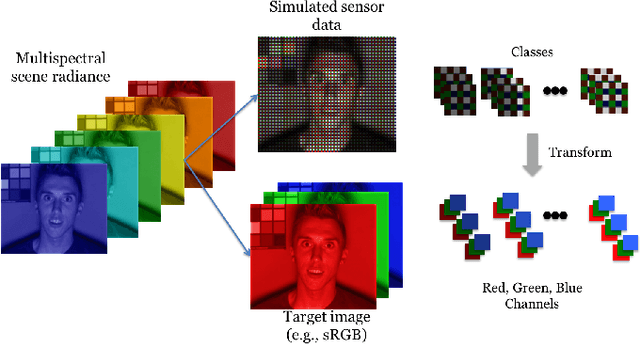
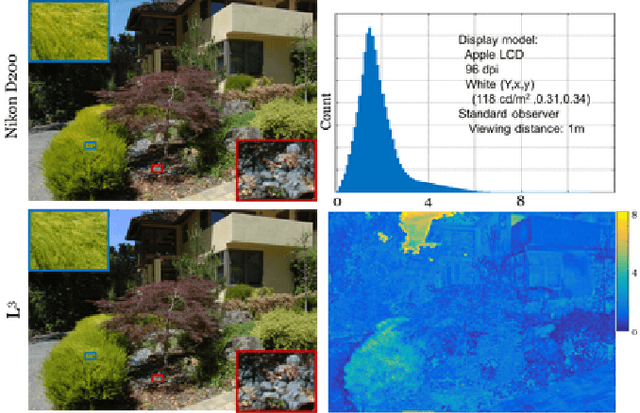

Many creative ideas are being proposed for image sensor designs, and these may be useful in applications ranging from consumer photography to computer vision. To understand and evaluate each new design, we must create a corresponding image processing pipeline that transforms the sensor data into a form that is appropriate for the application. The need to design and optimize these pipelines is time-consuming and costly. We explain a method that combines machine learning and image systems simulation that automates the pipeline design. The approach is based on a new way of thinking of the image processing pipeline as a large collection of local linear filters. We illustrate how the method has been used to design pipelines for novel sensor architectures in consumer photography applications.