 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID CT-Net: Predicting Covid-19 From Chest CT Images Using Attentional Convolutional Network
Sep 10, 2020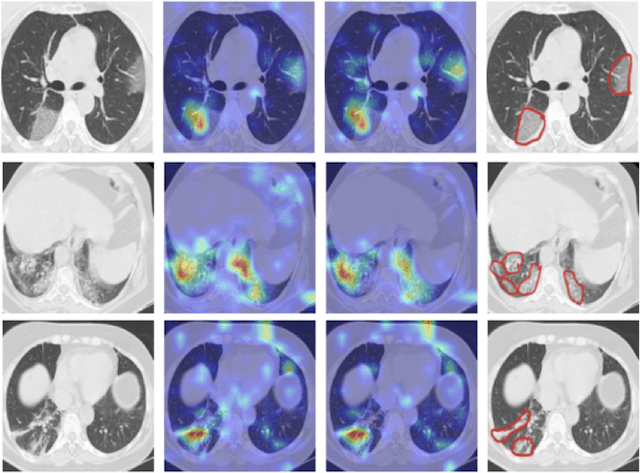
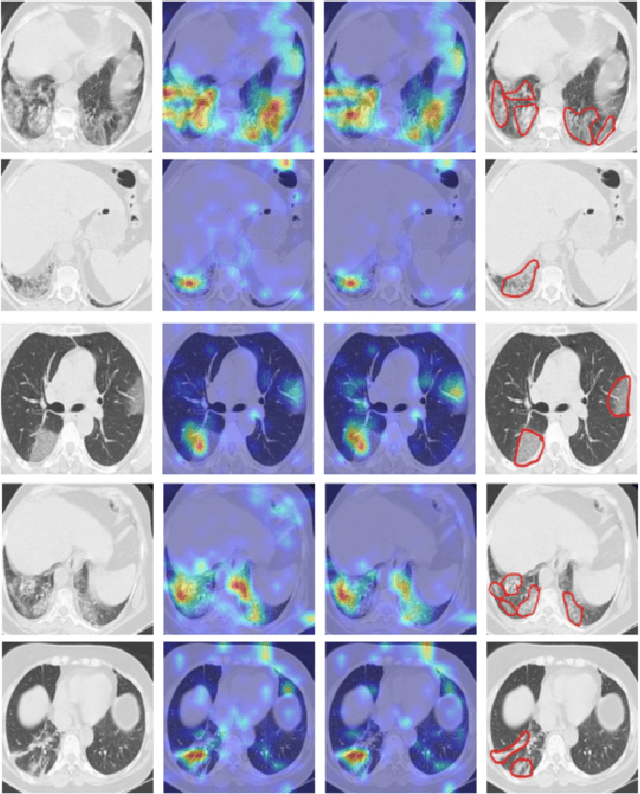
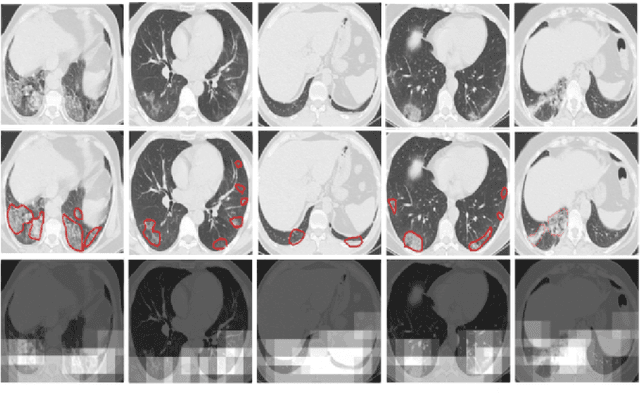
The novel corona-virus disease (COVID-19) pandemic has caused a major outbreak in more than 200 countries around the world, leading to a severe impact on the health and life of many people globally. As of Aug 25th of 2020, more than 20 million people are infected, and more than 800,000 death are reported. Computed Tomography (CT) images can be used as a as an alternative to the time-consuming "reverse transcription polymerase chain reaction (RT-PCR)" test, to detect COVID-19. In this work we developed a deep learning framework to predict COVID-19 from CT images. We propose to use an attentional convolution network, which can focus on the infected areas of chest, enabling it to perform a more accurate prediction. We trained our model on a dataset of more than 2000 CT images, and report its performance in terms of various popular metrics, such as sensitivity, specificity, area under the curve, and also precision-recall curve, and achieve very promising results. We also provide a visualization of the attention maps of the model for several test images, and show that our model is attending to the infected regions as intended. In addition to developing a machine learning modeling framework, we also provide the manual annotation of the potentionally infected regions of chest, with the help of a board-certified radiologist, and make that publicly available for other researchers.
COVID TV-UNet: Segmenting COVID-19 Chest CT Images Using Connectivity Imposed U-Net
Aug 06, 2020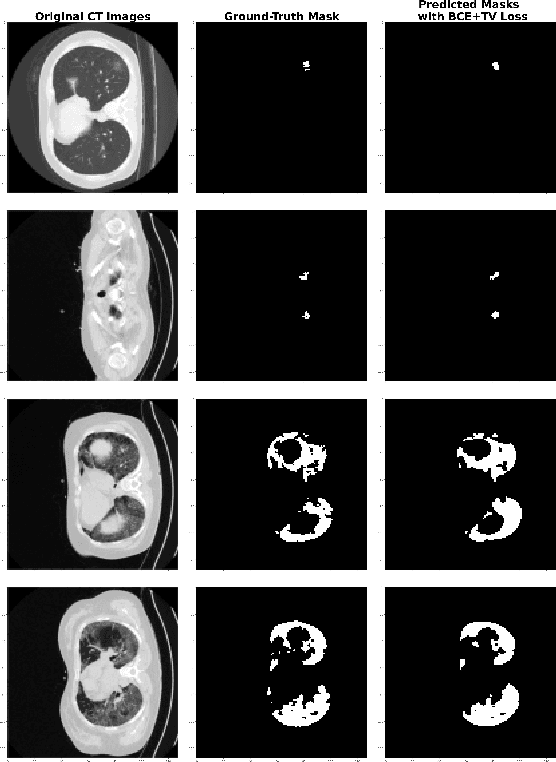
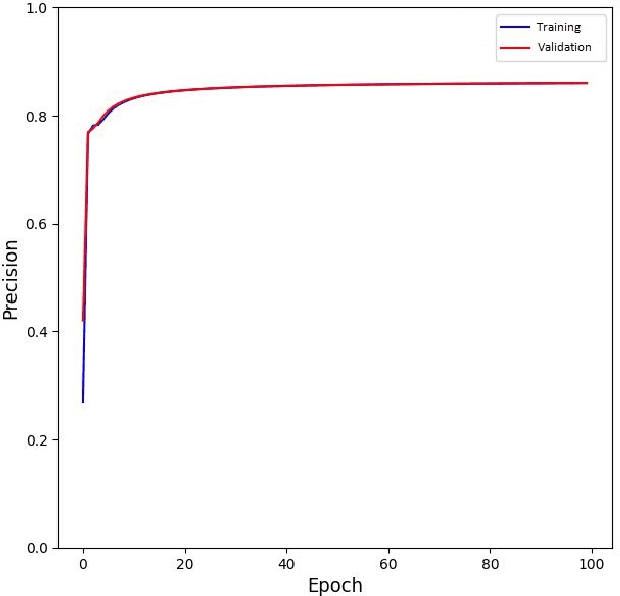
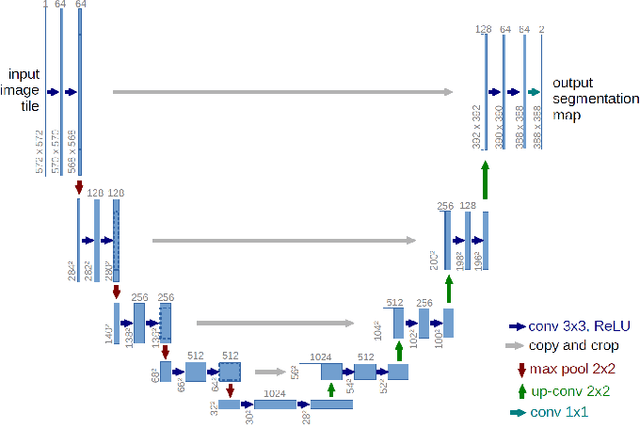
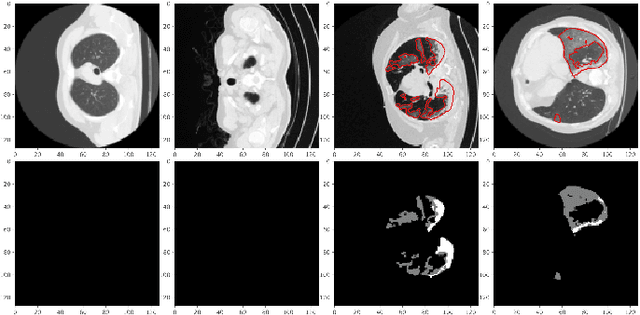
The novel corona-virus disease (COVID-19) pandemic has caused a major outbreak in more than 200 countries around the world, leading to a severe impact on the health and life of many people globally. As of mid-July 2020, more than 12 million people were infected, and more than 570,000 death were reported. Computed Tomography (CT) images can be used as an alternative to the time-consuming RT-PCR test, to detect COVID-19. In this work we propose a segmentation framework to detect chest regions in CT images, which are infected by COVID-19. We use an architecture similar to U-Net model, and train it to detect ground glass regions, on pixel level. As the infected regions tend to form a connected component (rather than randomly distributed pixels), we add a suitable regularization term to the loss function, to promote connectivity of the segmentation map for COVID-19 pixels. 2D-anisotropic total-variation is used for this purpose, and therefore the proposed model is called "TV-UNet". Through experimental results on a relatively large-scale CT segmentation dataset of around 900 images, we show that adding this new regularization term leads to 2\% gain on overall segmentation performance compared to the U-Net model. Our experimental analysis, ranging from visual evaluation of the predicted segmentation results to quantitative assessment of segmentation performance (precision, recall, Dice score, and mIoU) demonstrated great ability to identify COVID-19 associated regions of the lungs, achieving a mIoU rate of over 99\%, and a Dice score of around 86\%.
Deep-COVID: Predicting COVID-19 From Chest X-Ray Images Using Deep Transfer Learning
Apr 20, 2020
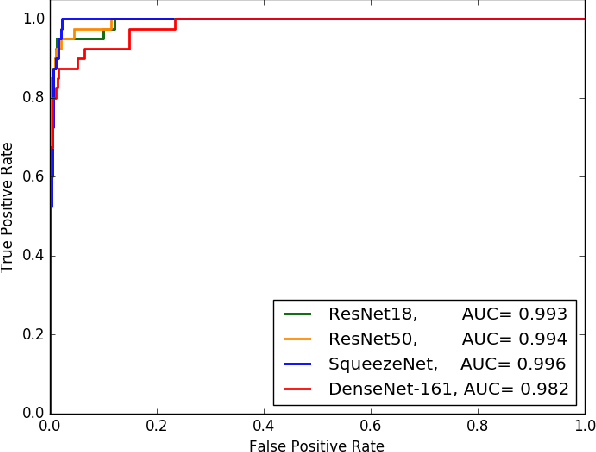
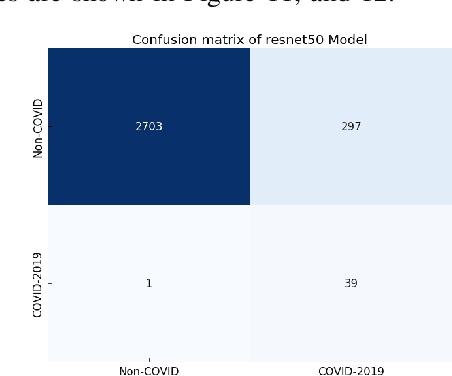
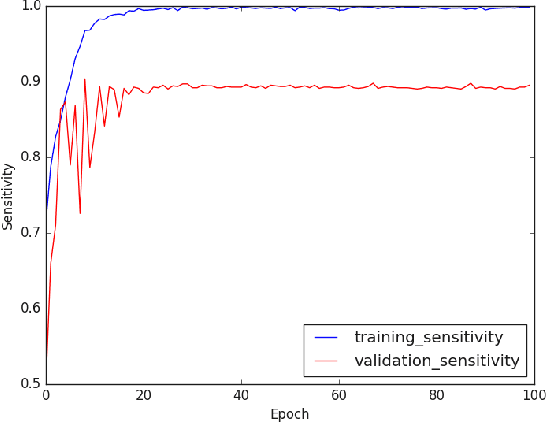
The COVID-19 pandemic is causing a major outbreak in more than 150 countries around the world, having a severe impact on the health and life of many people globally. One of the crucial step in fighting COVID-19 is the ability to detect the infected patients early enough, and put them under special care. Detecting this disease from radiography and radiology images is perhaps one of the fastest way to diagnose the patients. Some of the early studies showed specific abnormalities in the chest radiograms of patients infected with COVID-19. Inspired by earlier works, we study the application of deep learning models to detect COVID-19 patients from their chest radiography images. We first prepare a dataset of 5,000 Chest X-rays from the publicly available datasets. Images exhibiting COVID-19 disease presence were identified by board-certified radiologist. Transfer learning on a subset of 2,000 radiograms was used to train four popular convolutional neural networks, including ResNet18, ResNet50, SqueezeNet, and DenseNet-121, to identify COVID-19 disease in the analyzed chest X-ray images. We evaluated these models on the remaining 3,000 images, and most of these networks achieved a sensitivity rate of 97\%($\pm$ 5\%), while having a specificity rate of around 90\%. While the achieved performance is very encouraging, further analysis is required on a larger set of COVID-19 images, to have a more reliable estimation of accuracy rates. Besides sensitivity and specificity rates, we also present the receiver operating characteristic (ROC), area under the curve (AUC), and confusion matrix of each model. The dataset, model implementations (in PyTorch), and evaluations, are all made publicly available for research community, here: https://github.com/shervinmin/DeepCovid.git
Classification of dry age-related macular degeneration and diabetic macular edema from optical coherence tomography images using dictionary learning
Mar 16, 2019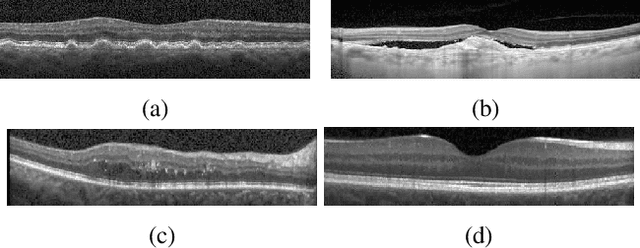
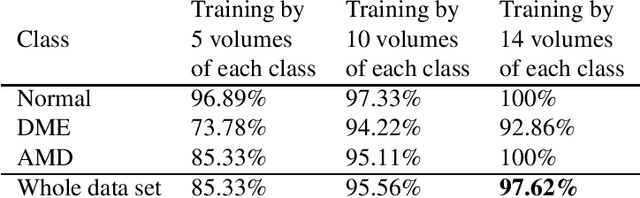
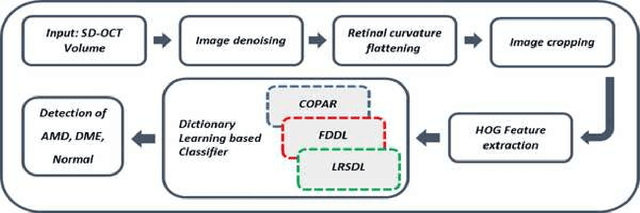
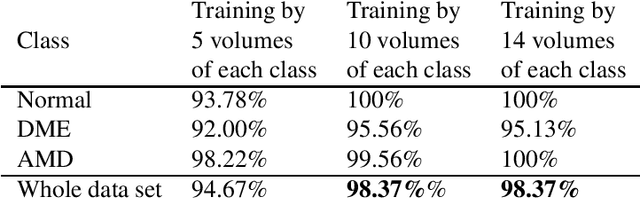
Age-related Macular Degeneration (AMD) and Diabetic Macular Edema (DME) are the major causes of vision loss in developed countries. Alteration of retinal layer structure and appearance of exudate are the most significant signs of these diseases. With the aim of automatic classification of DME, AMD and normal subjects from Optical Coherence Tomography (OCT) images, we proposed a classification algorithm. The two important issues intended in this approach are, not utilizing retinal layer segmentation which by itself is a challenging task and attempting to identify diseases in their early stages, where the signs of diseases appear in a small fraction of B-Scans. We used a histogram of oriented gradients (HOG) feature descriptor to well characterize the distribution of local intensity gradients and edge directions. In order to capture the structure of extracted features, we employed different dictionary learning-based classifiers. Our dataset consists of 45 subjects: 15 patients with AMD, 15 patients with DME and 15 normal subjects. The proposed classifier leads to an accuracy of 95.13%, 100.00%, and 100.00% for DME, AMD, and normal OCT images, respectively, only by considering the 4% of all B-Scans of a volume which outperforms the state of the art methods.