 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman and Automatic Speech Recognition Performance on German Oral History Interviews
Jan 18, 2022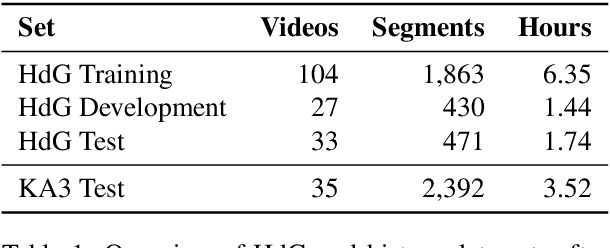
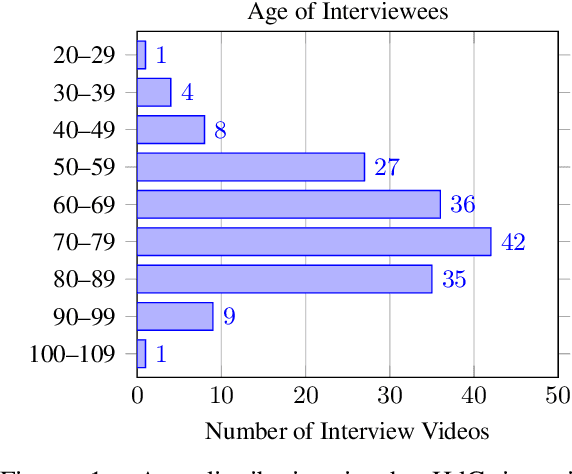
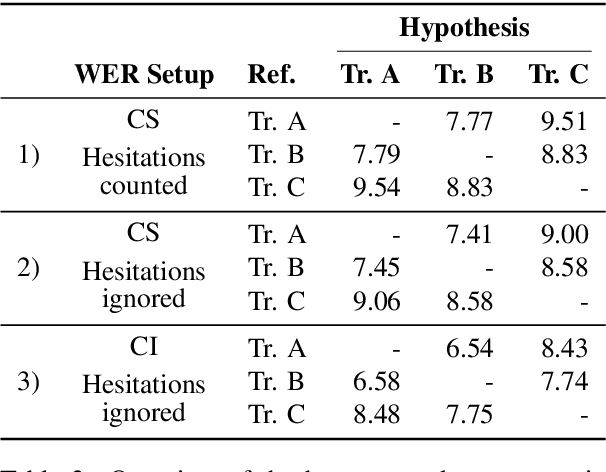
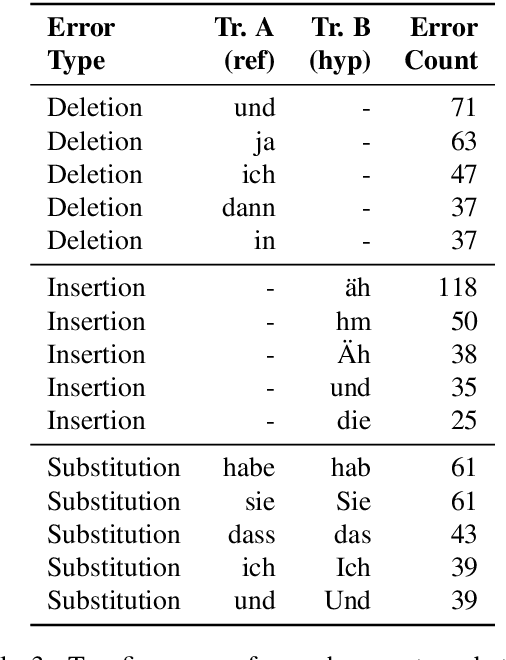
Automatic speech recognition systems have accomplished remarkable improvements in transcription accuracy in recent years. On some domains, models now achieve near-human performance. However, transcription performance on oral history has not yet reached human accuracy. In the present work, we investigate how large this gap between human and machine transcription still is. For this purpose, we analyze and compare transcriptions of three humans on a new oral history data set. We estimate a human word error rate of 8.7% for recent German oral history interviews with clean acoustic conditions. For comparison with recent machine transcription accuracy, we present experiments on the adaptation of an acoustic model achieving near-human performance on broadcast speech. We investigate the influence of different adaptation data on robustness and generalization for clean and noisy oral history interviews. We optimize our acoustic models by 5 to 8% relative for this task and achieve 23.9% WER on noisy and 15.6% word error rate on clean oral history interviews.
Multitask Learning for Grapheme-to-Phoneme Conversion of Anglicisms in German Speech Recognition
May 26, 2021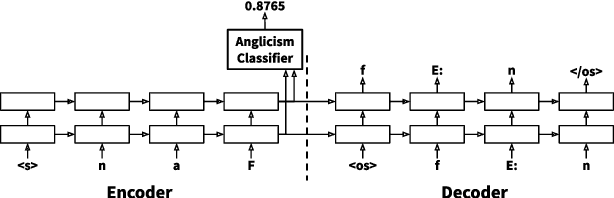

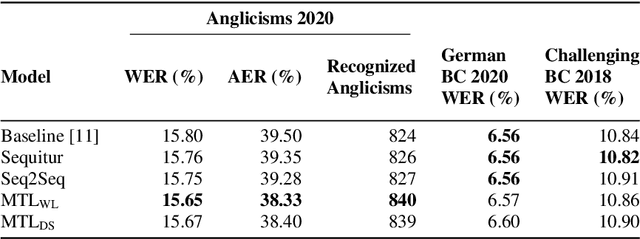

Loanwords, such as Anglicisms, are a challenge in German speech recognition. Due to their irregular pronunciation compared to native German words, automatically generated pronunciation dictionaries often include faulty phoneme sequences for Anglicisms. In this work, we propose a multitask sequence-to-sequence approach for grapheme-to-phoneme conversion to improve the phonetization of Anglicisms. We extended a grapheme-to-phoneme model with a classifier to distinguish Anglicisms from native German words. With this approach, the model learns to generate pronunciations differently depending on the classification result. We used our model to create supplementary Anglicism pronunciation dictionaries that are added to an existing German speech recognition model. Tested on a dedicated Anglicism evaluation set, we improved the recognition of Anglicisms compared to a baseline model, reducing the word error rate by 1 % and the Anglicism error rate by 3 %. We show that multitask learning can help solving the challenge of loanwords in German speech recognition.
Two-Staged Acoustic Modeling Adaption for Robust Speech Recognition by the Example of German Oral History Interviews
Aug 19, 2019


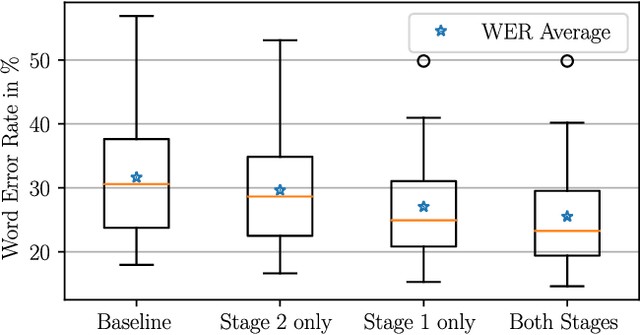
In automatic speech recognition, often little training data is available for specific challenging tasks, but training of state-of-the-art automatic speech recognition systems requires large amounts of annotated speech. To address this issue, we propose a two-staged approach to acoustic modeling that combines noise and reverberation data augmentation with transfer learning to robustly address challenges such as difficult acoustic recording conditions, spontaneous speech, and speech of elderly people. We evaluate our approach using the example of German oral history interviews, where a relative average reduction of the word error rate by 19.3% is achieved.
* Accepted for IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, July 2019
Towards a Knowledge Graph based Speech Interface
May 23, 2017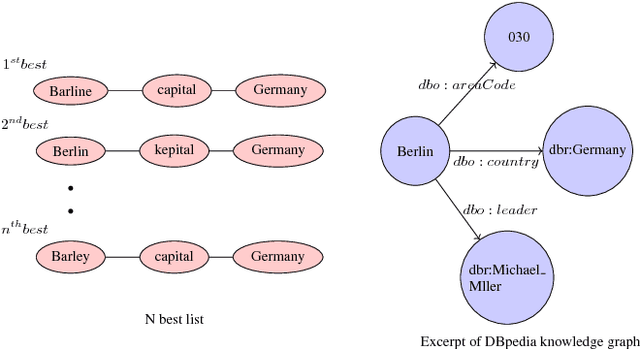

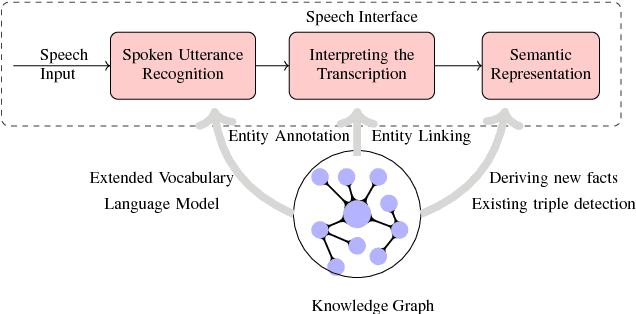
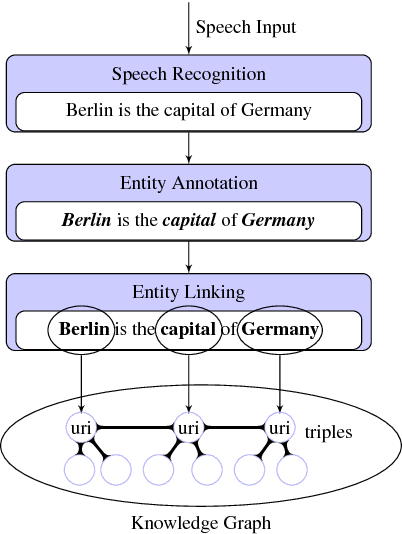
Applications which use human speech as an input require a speech interface with high recognition accuracy. The words or phrases in the recognised text are annotated with a machine-understandable meaning and linked to knowledge graphs for further processing by the target application. These semantic annotations of recognised words can be represented as a subject-predicate-object triples which collectively form a graph often referred to as a knowledge graph. This type of knowledge representation facilitates to use speech interfaces with any spoken input application, since the information is represented in logical, semantic form, retrieving and storing can be followed using any web standard query languages. In this work, we develop a methodology for linking speech input to knowledge graphs and study the impact of recognition errors in the overall process. We show that for a corpus with lower WER, the annotation and linking of entities to the DBpedia knowledge graph is considerable. DBpedia Spotlight, a tool to interlink text documents with the linked open data is used to link the speech recognition output to the DBpedia knowledge graph. Such a knowledge-based speech recognition interface is useful for applications such as question answering or spoken dialog systems.
Use of Knowledge Graph in Rescoring the N-Best List in Automatic Speech Recognition
May 22, 2017
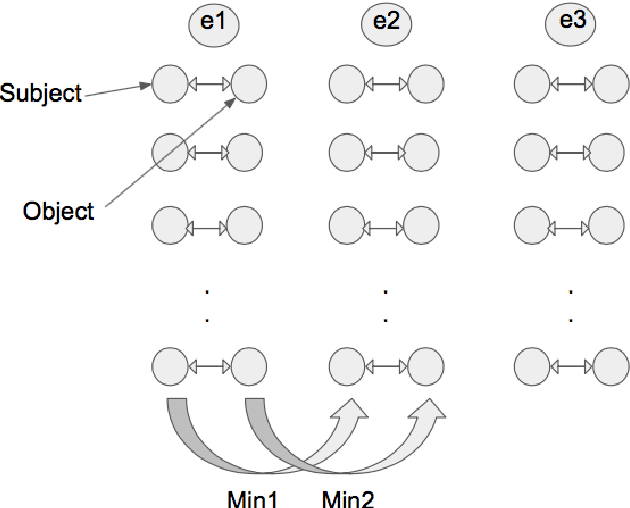
With the evolution of neural network based methods, automatic speech recognition (ASR) field has been advanced to a level where building an application with speech interface is a reality. In spite of these advances, building a real-time speech recogniser faces several problems such as low recognition accuracy, domain constraint, and out-of-vocabulary words. The low recognition accuracy problem is addressed by improving the acoustic model, language model, decoder and by rescoring the N-best list at the output of the decoder. We are considering the N-best list rescoring approach to improve the recognition accuracy. Most of the methods in the literature use the grammatical, lexical, syntactic and semantic connection between the words in a recognised sentence as a feature to rescore. In this paper, we have tried to see the semantic relatedness between the words in a sentence to rescore the N-best list. Semantic relatedness is computed using TransE~\cite{bordes2013translating}, a method for low dimensional embedding of a triple in a knowledge graph. The novelty of the paper is the application of semantic web to automatic speech recognition.