 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on the Ambiguity in Human Annotation of German Oral History Interviews for Perceived Emotion Recognition and Sentiment Analysis
Jan 18, 2022
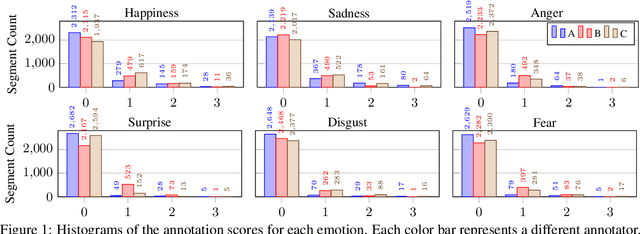
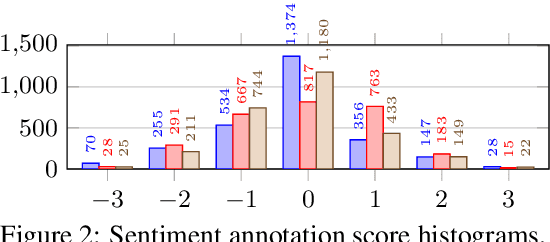
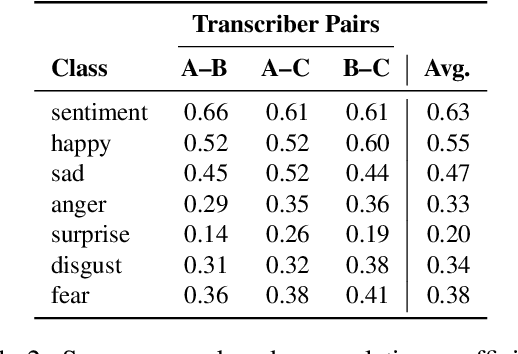
For research in audiovisual interview archives often it is not only of interest what is said but also how. Sentiment analysis and emotion recognition can help capture, categorize and make these different facets searchable. In particular, for oral history archives, such indexing technologies can be of great interest. These technologies can help understand the role of emotions in historical remembering. However, humans often perceive sentiments and emotions ambiguously and subjectively. Moreover, oral history interviews have multi-layered levels of complex, sometimes contradictory, sometimes very subtle facets of emotions. Therefore, the question arises of the chance machines and humans have capturing and assigning these into predefined categories. This paper investigates the ambiguity in human perception of emotions and sentiment in German oral history interviews and the impact on machine learning systems. Our experiments reveal substantial differences in human perception for different emotions. Furthermore, we report from ongoing machine learning experiments with different modalities. We show that the human perceptual ambiguity and other challenges, such as class imbalance and lack of training data, currently limit the opportunities of these technologies for oral history archives. Nonetheless, our work uncovers promising observations and possibilities for further research.
Human and Automatic Speech Recognition Performance on German Oral History Interviews
Jan 18, 2022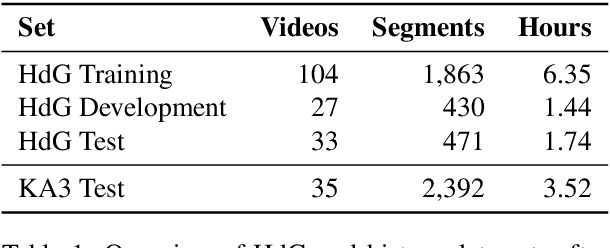
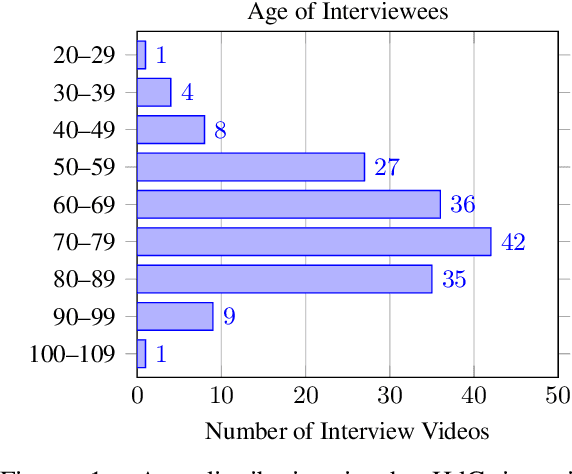
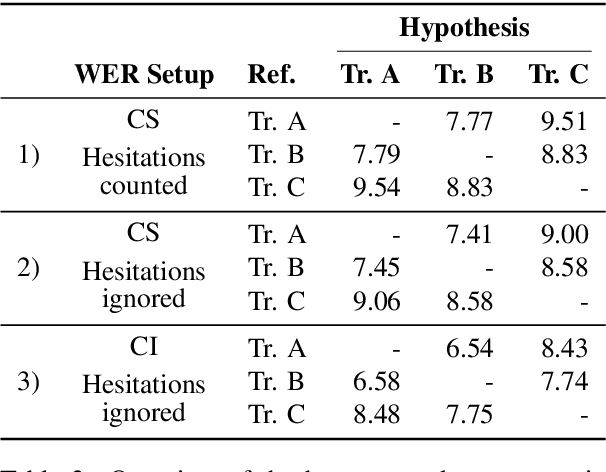
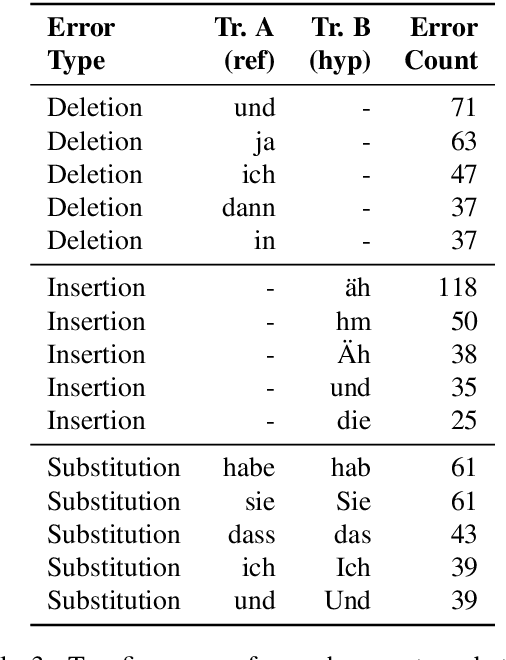
Automatic speech recognition systems have accomplished remarkable improvements in transcription accuracy in recent years. On some domains, models now achieve near-human performance. However, transcription performance on oral history has not yet reached human accuracy. In the present work, we investigate how large this gap between human and machine transcription still is. For this purpose, we analyze and compare transcriptions of three humans on a new oral history data set. We estimate a human word error rate of 8.7% for recent German oral history interviews with clean acoustic conditions. For comparison with recent machine transcription accuracy, we present experiments on the adaptation of an acoustic model achieving near-human performance on broadcast speech. We investigate the influence of different adaptation data on robustness and generalization for clean and noisy oral history interviews. We optimize our acoustic models by 5 to 8% relative for this task and achieve 23.9% WER on noisy and 15.6% word error rate on clean oral history interviews.