 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of Large Language Models in a Computer Science Degree Program
Jul 24, 2023



Large language models such as ChatGPT-3.5 and GPT-4.0 are ubiquitous and dominate the current discourse. Their transformative capabilities have led to a paradigm shift in how we interact with and utilize (text-based) information. Each day, new possibilities to leverage the capabilities of these models emerge. This paper presents findings on the performance of different large language models in a university of applied sciences' undergraduate computer science degree program. Our primary objective is to assess the effectiveness of these models within the curriculum by employing them as educational aids. By prompting the models with lecture material, exercise tasks, and past exams, we aim to evaluate their proficiency across different computer science domains. We showcase the strong performance of current large language models while highlighting limitations and constraints within the context of such a degree program. We found that ChatGPT-3.5 averaged 79.9% of the total score in 10 tested modules, BingAI achieved 68.4%, and LLaMa, in the 65 billion parameter variant, 20%. Despite these convincing results, even GPT-4.0 would not pass the degree program - due to limitations in mathematical calculations.
A Study on the Ambiguity in Human Annotation of German Oral History Interviews for Perceived Emotion Recognition and Sentiment Analysis
Jan 18, 2022
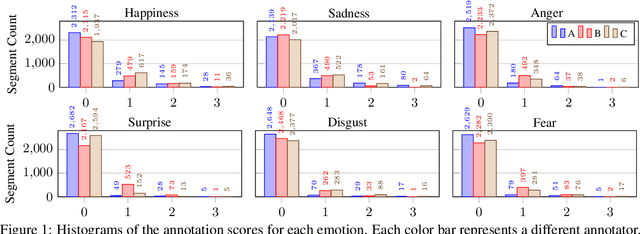
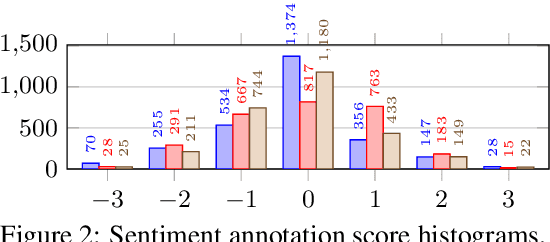
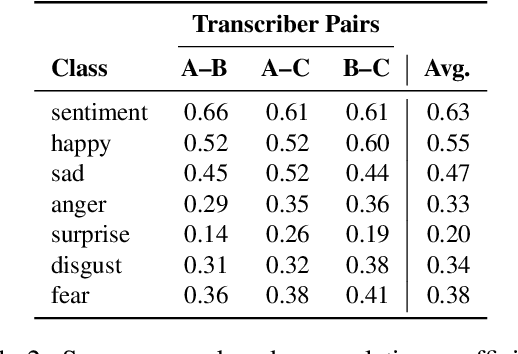
For research in audiovisual interview archives often it is not only of interest what is said but also how. Sentiment analysis and emotion recognition can help capture, categorize and make these different facets searchable. In particular, for oral history archives, such indexing technologies can be of great interest. These technologies can help understand the role of emotions in historical remembering. However, humans often perceive sentiments and emotions ambiguously and subjectively. Moreover, oral history interviews have multi-layered levels of complex, sometimes contradictory, sometimes very subtle facets of emotions. Therefore, the question arises of the chance machines and humans have capturing and assigning these into predefined categories. This paper investigates the ambiguity in human perception of emotions and sentiment in German oral history interviews and the impact on machine learning systems. Our experiments reveal substantial differences in human perception for different emotions. Furthermore, we report from ongoing machine learning experiments with different modalities. We show that the human perceptual ambiguity and other challenges, such as class imbalance and lack of training data, currently limit the opportunities of these technologies for oral history archives. Nonetheless, our work uncovers promising observations and possibilities for further research.
Human and Automatic Speech Recognition Performance on German Oral History Interviews
Jan 18, 2022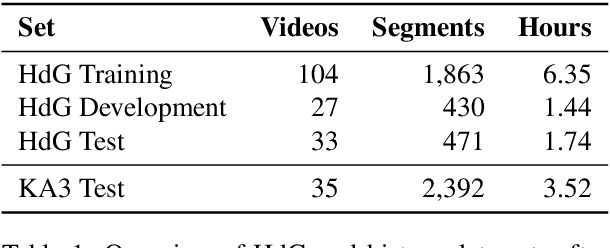
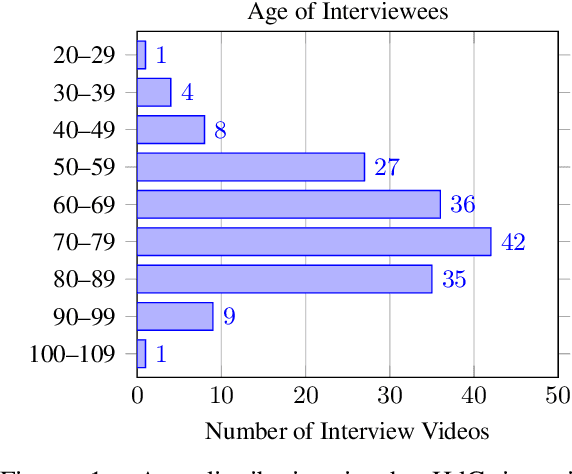
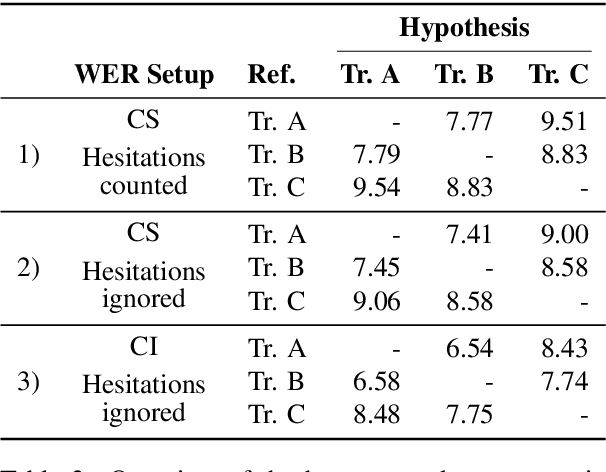
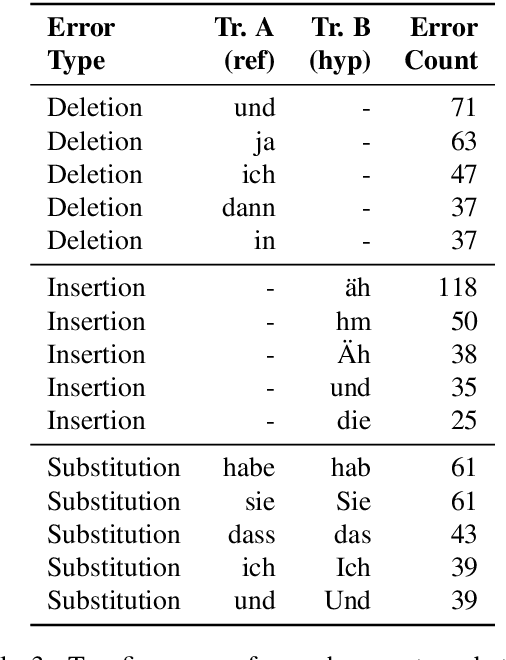
Automatic speech recognition systems have accomplished remarkable improvements in transcription accuracy in recent years. On some domains, models now achieve near-human performance. However, transcription performance on oral history has not yet reached human accuracy. In the present work, we investigate how large this gap between human and machine transcription still is. For this purpose, we analyze and compare transcriptions of three humans on a new oral history data set. We estimate a human word error rate of 8.7% for recent German oral history interviews with clean acoustic conditions. For comparison with recent machine transcription accuracy, we present experiments on the adaptation of an acoustic model achieving near-human performance on broadcast speech. We investigate the influence of different adaptation data on robustness and generalization for clean and noisy oral history interviews. We optimize our acoustic models by 5 to 8% relative for this task and achieve 23.9% WER on noisy and 15.6% word error rate on clean oral history interviews.
Multitask Learning for Grapheme-to-Phoneme Conversion of Anglicisms in German Speech Recognition
May 26, 2021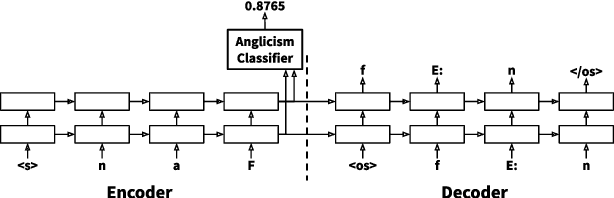

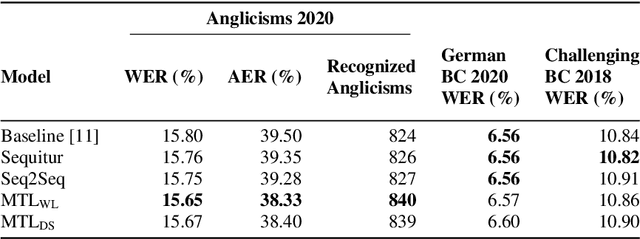

Loanwords, such as Anglicisms, are a challenge in German speech recognition. Due to their irregular pronunciation compared to native German words, automatically generated pronunciation dictionaries often include faulty phoneme sequences for Anglicisms. In this work, we propose a multitask sequence-to-sequence approach for grapheme-to-phoneme conversion to improve the phonetization of Anglicisms. We extended a grapheme-to-phoneme model with a classifier to distinguish Anglicisms from native German words. With this approach, the model learns to generate pronunciations differently depending on the classification result. We used our model to create supplementary Anglicism pronunciation dictionaries that are added to an existing German speech recognition model. Tested on a dedicated Anglicism evaluation set, we improved the recognition of Anglicisms compared to a baseline model, reducing the word error rate by 1 % and the Anglicism error rate by 3 %. We show that multitask learning can help solving the challenge of loanwords in German speech recognition.
Two-Staged Acoustic Modeling Adaption for Robust Speech Recognition by the Example of German Oral History Interviews
Aug 19, 2019


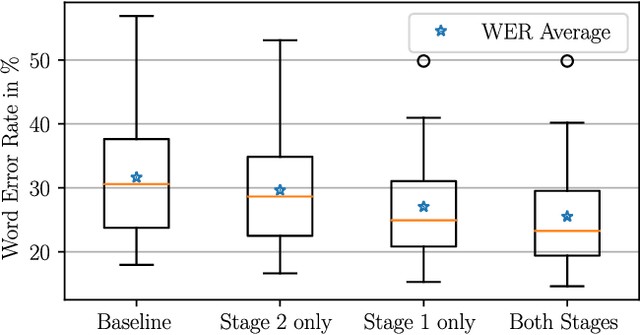
In automatic speech recognition, often little training data is available for specific challenging tasks, but training of state-of-the-art automatic speech recognition systems requires large amounts of annotated speech. To address this issue, we propose a two-staged approach to acoustic modeling that combines noise and reverberation data augmentation with transfer learning to robustly address challenges such as difficult acoustic recording conditions, spontaneous speech, and speech of elderly people. We evaluate our approach using the example of German oral history interviews, where a relative average reduction of the word error rate by 19.3% is achieved.
* Accepted for IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, July 2019