 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Knowledge Graph based Speech Interface
Paper and Code
May 23, 2017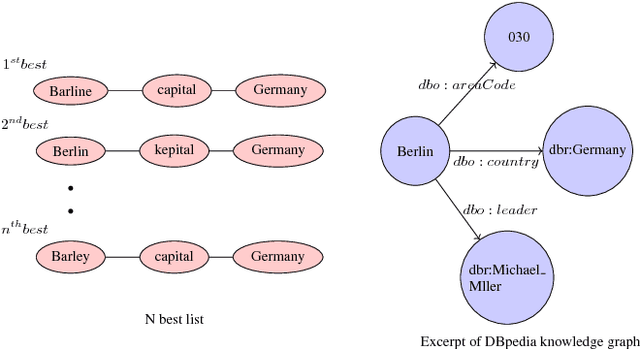

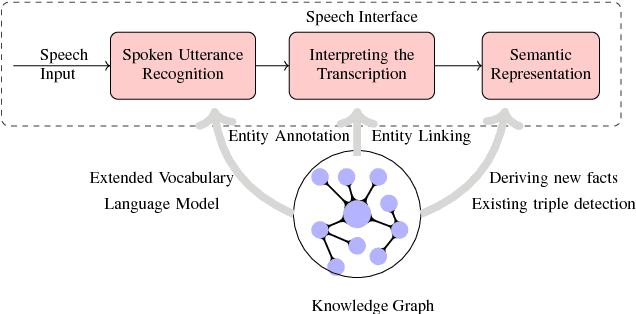
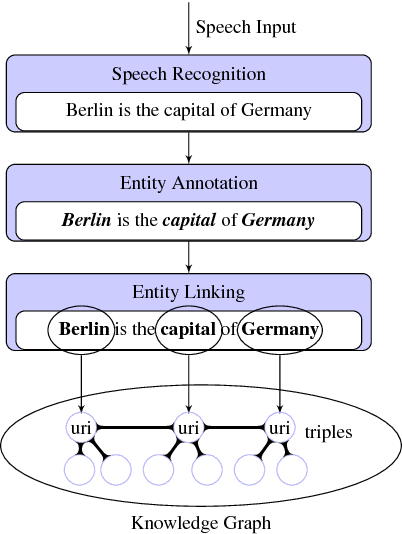
Applications which use human speech as an input require a speech interface with high recognition accuracy. The words or phrases in the recognised text are annotated with a machine-understandable meaning and linked to knowledge graphs for further processing by the target application. These semantic annotations of recognised words can be represented as a subject-predicate-object triples which collectively form a graph often referred to as a knowledge graph. This type of knowledge representation facilitates to use speech interfaces with any spoken input application, since the information is represented in logical, semantic form, retrieving and storing can be followed using any web standard query languages. In this work, we develop a methodology for linking speech input to knowledge graphs and study the impact of recognition errors in the overall process. We show that for a corpus with lower WER, the annotation and linking of entities to the DBpedia knowledge graph is considerable. DBpedia Spotlight, a tool to interlink text documents with the linked open data is used to link the speech recognition output to the DBpedia knowledge graph. Such a knowledge-based speech recognition interface is useful for applications such as question answering or spoken dialog systems.