 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Jan 06, 2026In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
Auto-Eval Judge: Towards a General Agentic Framework for Task Completion Evaluation
Aug 07, 2025



The increasing adoption of foundation models as agents across diverse domains necessitates a robust evaluation framework. Current methods, such as LLM-as-a-Judge, focus only on final outputs, overlooking the step-by-step reasoning that drives agentic decision-making. Meanwhile, existing Agent-as-a-Judge systems, where one agent evaluates another's task completion, are typically designed for narrow, domain-specific settings. To address this gap, we propose a generalizable, modular framework for evaluating agent task completion independent of the task domain. The framework emulates human-like evaluation by decomposing tasks into sub-tasks and validating each step using available information, such as the agent's output and reasoning. Each module contributes to a specific aspect of the evaluation process, and their outputs are aggregated to produce a final verdict on task completion. We validate our framework by evaluating the Magentic-One Actor Agent on two benchmarks, GAIA and BigCodeBench. Our Judge Agent predicts task success with closer agreement to human evaluations, achieving 4.76% and 10.52% higher alignment accuracy, respectively, compared to the GPT-4o based LLM-as-a-Judge baseline. This demonstrates the potential of our proposed general-purpose evaluation framework.
Concept Distillation from Strong to Weak Models via Hypotheses-to-Theories Prompting
Aug 18, 2024



Hand-crafting high quality prompts to optimize the performance of language models is a complicated and labor-intensive process. Furthermore, when migrating to newer, smaller, or weaker models (possibly due to latency or cost gains), prompts need to be updated to re-optimize the task performance. We propose Concept Distillation (CD), an automatic prompt optimization technique for enhancing weaker models on complex tasks. CD involves: (1) collecting mistakes made by weak models with a base prompt (initialization), (2) using a strong model to generate reasons for these mistakes and create rules/concepts for weak models (induction), and (3) filtering these rules based on validation set performance and integrating them into the base prompt (deduction/verification). We evaluated CD on NL2Code and mathematical reasoning tasks, observing significant performance boosts for small and weaker language models. Notably, Mistral-7B's accuracy on Multi-Arith increased by 20%, and Phi-3-mini-3.8B's accuracy on HumanEval rose by 34%. Compared to other automated methods, CD offers an effective, cost-efficient strategy for improving weak models' performance on complex tasks and enables seamless workload migration across different language models without compromising performance.
Lights, Camera, Action! A Framework to Improve NLP Accuracy over OCR documents
Aug 06, 2021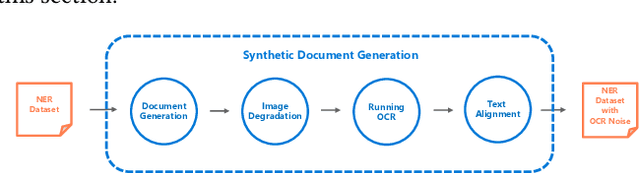
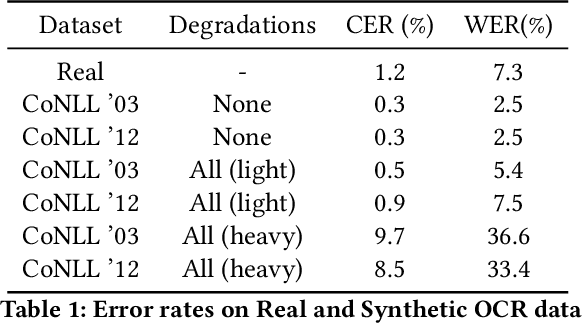
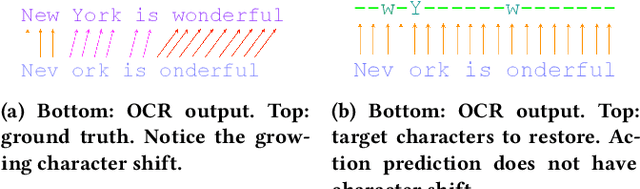

Document digitization is essential for the digital transformation of our societies, yet a crucial step in the process, Optical Character Recognition (OCR), is still not perfect. Even commercial OCR systems can produce questionable output depending on the fidelity of the scanned documents. In this paper, we demonstrate an effective framework for mitigating OCR errors for any downstream NLP task, using Named Entity Recognition (NER) as an example. We first address the data scarcity problem for model training by constructing a document synthesis pipeline, generating realistic but degraded data with NER labels. We measure the NER accuracy drop at various degradation levels and show that a text restoration model, trained on the degraded data, significantly closes the NER accuracy gaps caused by OCR errors, including on an out-of-domain dataset. For the benefit of the community, we have made the document synthesis pipeline available as an open-source project.
Evaluating Tree Explanation Methods for Anomaly Reasoning: A Case Study of SHAP TreeExplainer and TreeInterpreter
Oct 13, 2020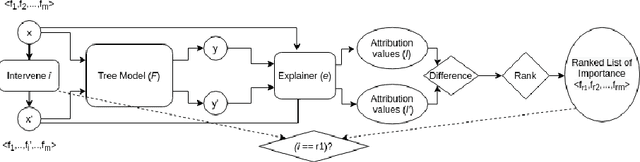
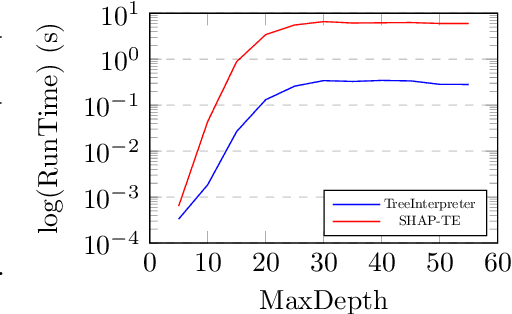
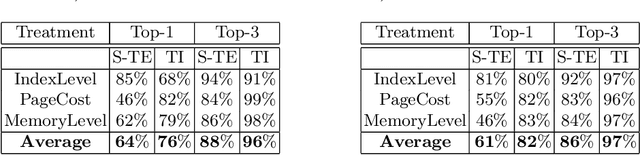
Understanding predictions made by Machine Learning models is critical in many applications. In this work, we investigate the performance of two methods for explaining tree-based models- Tree Interpreter (TI) and SHapley Additive exPlanations TreeExplainer (SHAP-TE). Using a case study on detecting anomalies in job runtimes of applications that utilize cloud-computing platforms, we compare these approaches using a variety of metrics, including computation time, significance of attribution value, and explanation accuracy. We find that, although the SHAP-TE offers consistency guarantees over TI, at the cost of increased computation, consistency does not necessarily improve the explanation performance in our case study.
Examination and Extension of Strategies for Improving Personalized Language Modeling via Interpolation
Jun 09, 2020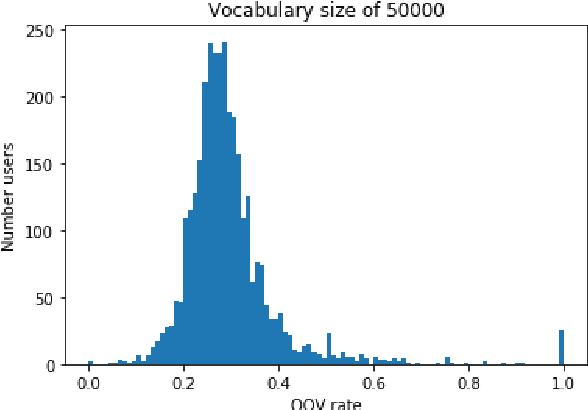
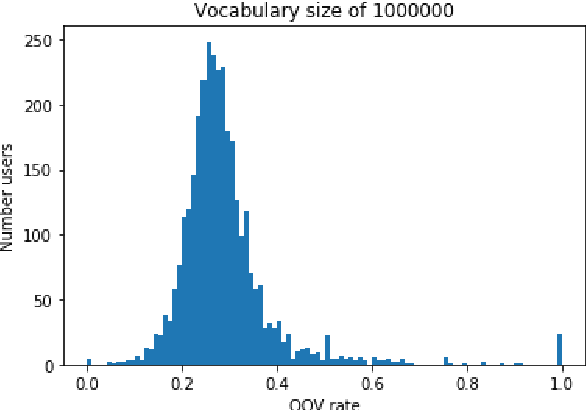

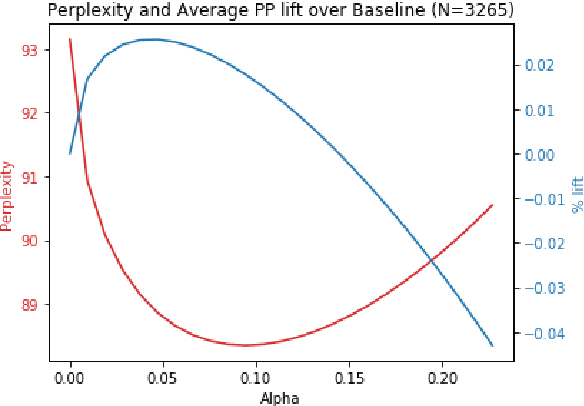
In this paper, we detail novel strategies for interpolating personalized language models and methods to handle out-of-vocabulary (OOV) tokens to improve personalized language models. Using publicly available data from Reddit, we demonstrate improvements in offline metrics at the user level by interpolating a global LSTM-based authoring model with a user-personalized n-gram model. By optimizing this approach with a back-off to uniform OOV penalty and the interpolation coefficient, we observe that over 80% of users receive a lift in perplexity, with an average of 5.2% in perplexity lift per user. In doing this research we extend previous work in building NLIs and improve the robustness of metrics for downstream tasks.
Model adaptation and unsupervised learning with non-stationary batch data under smooth concept drift
Feb 10, 2020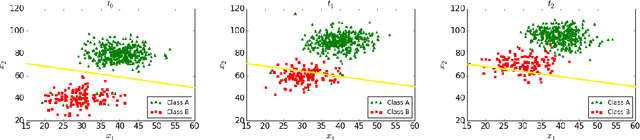
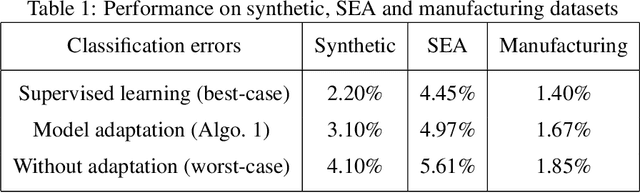
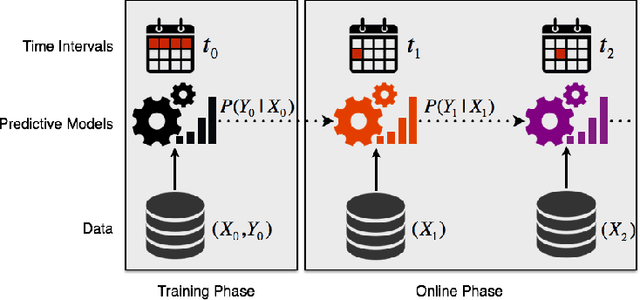
Most predictive models assume that training and test data are generated from a stationary process. However, this assumption does not hold true in practice. In this paper, we consider the scenario of a gradual concept drift due to the underlying non-stationarity of the data source. While previous work has investigated this scenario under a supervised-learning and adaption conditions, few have addressed the common, real-world scenario when labels are only available during training. We propose a novel, iterative algorithm for unsupervised adaptation of predictive models. We show that the performance of our batch adapted prediction algorithm is better than that of its corresponding unadapted version. The proposed algorithm provides similar (or better, in most cases) performance within significantly less run time compared to other state of the art methods. We validate our claims though extensive numerical evaluations on both synthetic and real data.
Griffon: Reasoning about Job Anomalies with Unlabeled Data in Cloud-based Platforms
Aug 23, 2019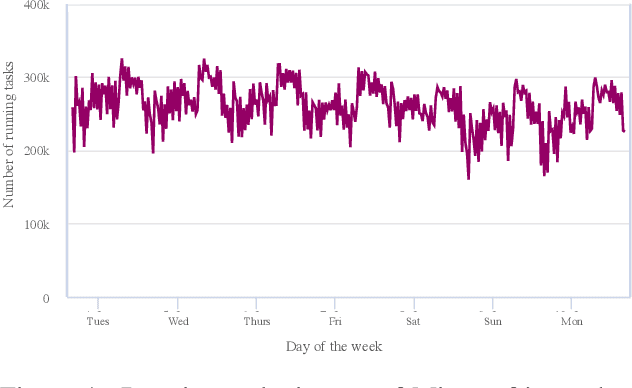

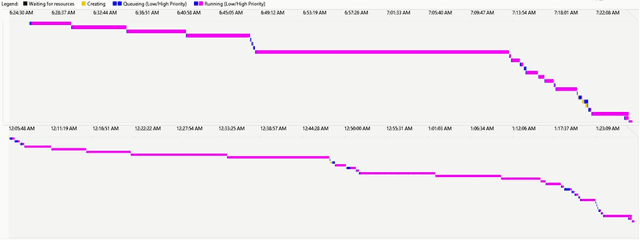
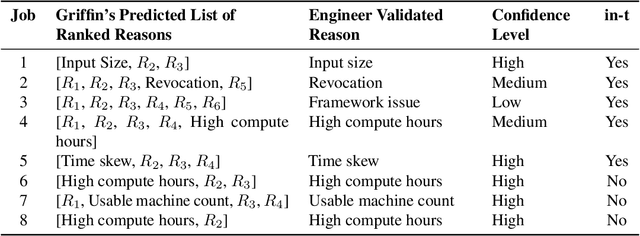
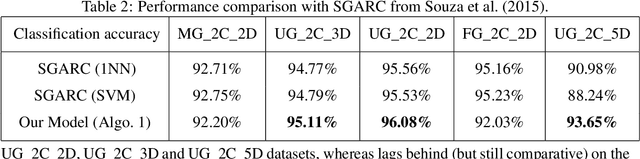
Microsoft's internal big data analytics platform is comprised of hundreds of thousands of machines, serving over half a million jobs daily, from thousands of users. The majority of these jobs are recurring and are crucial for the company's operation. Although administrators spend significant effort tuning system performance, some jobs inevitably experience slowdowns, i.e., their execution time degrades over previous runs. Currently, the investigation of such slowdowns is a labor-intensive and error-prone process, which costs Microsoft significant human and machine resources, and negatively impacts several lines of businesses. In this work, we present Griffin, a system we built and have deployed in production last year to automatically discover the root cause of job slowdowns. Existing solutions either rely on labeled data (i.e., resolved incidents with labeled reasons for job slowdowns), which is in most cases non-existent or non-trivial to acquire, or on time-series analysis of individual metrics that do not target specific jobs holistically. In contrast, in Griffin we cast the problem to a corresponding regression one that predicts the runtime of a job, and show how the relative contributions of the features used to train our interpretable model can be exploited to rank the potential causes of job slowdowns. Evaluated over historical incidents, we show that Griffin discovers slowdown causes that are consistent with the ones validated by domain-expert engineers, in a fraction of the time required by them.
Dealing with Class Imbalance using Thresholding
Jul 10, 2016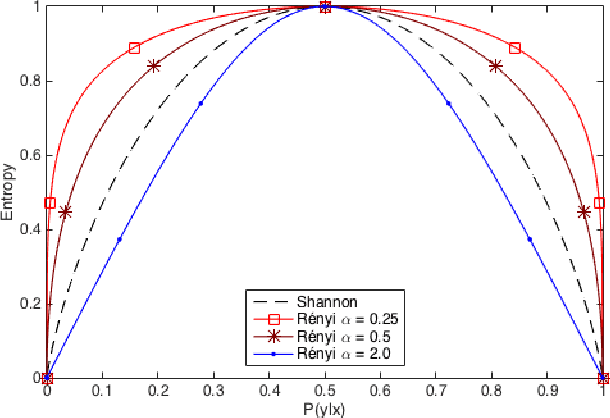
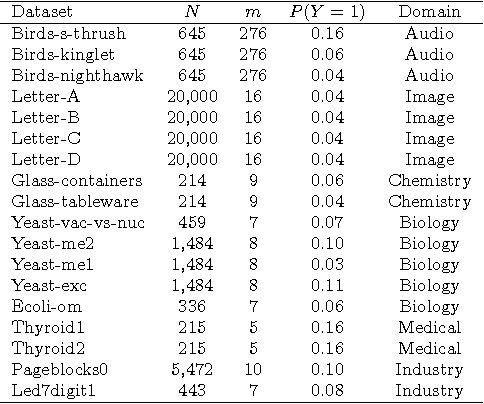
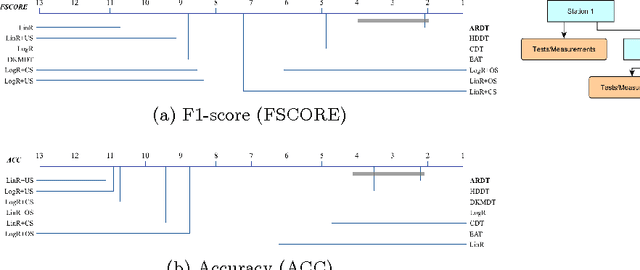
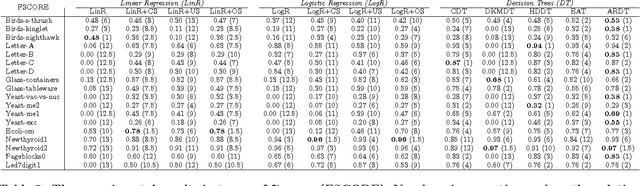
We propose thresholding as an approach to deal with class imbalance. We define the concept of thresholding as a process of determining a decision boundary in the presence of a tunable parameter. The threshold is the maximum value of this tunable parameter where the conditions of a certain decision are satisfied. We show that thresholding is applicable not only for linear classifiers but also for non-linear classifiers. We show that this is the implicit assumption for many approaches to deal with class imbalance in linear classifiers. We then extend this paradigm beyond linear classification and show how non-linear classification can be dealt with under this umbrella framework of thresholding. The proposed method can be used for outlier detection in many real-life scenarios like in manufacturing. In advanced manufacturing units, where the manufacturing process has matured over time, the number of instances (or parts) of the product that need to be rejected (based on a strict regime of quality tests) becomes relatively rare and are defined as outliers. How to detect these rare parts or outliers beforehand? How to detect combination of conditions leading to these outliers? These are the questions motivating our research. This paper focuses on prediction of outliers and conditions leading to outliers using classification. We address the problem of outlier detection using classification. The classes are good parts (those passing the quality tests) and bad parts (those failing the quality tests and can be considered as outliers). The rarity of outliers transforms this problem into a class-imbalanced classification problem.