 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel adaptation and unsupervised learning with non-stationary batch data under smooth concept drift
Feb 10, 2020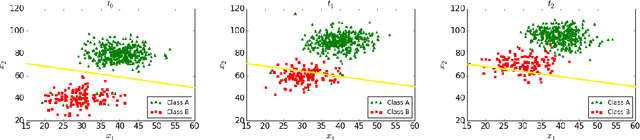
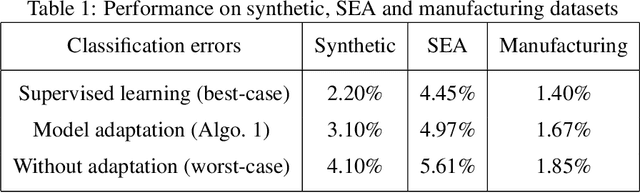
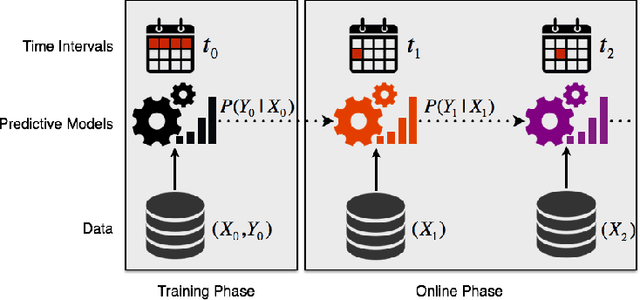
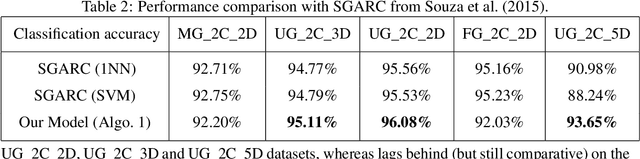
Most predictive models assume that training and test data are generated from a stationary process. However, this assumption does not hold true in practice. In this paper, we consider the scenario of a gradual concept drift due to the underlying non-stationarity of the data source. While previous work has investigated this scenario under a supervised-learning and adaption conditions, few have addressed the common, real-world scenario when labels are only available during training. We propose a novel, iterative algorithm for unsupervised adaptation of predictive models. We show that the performance of our batch adapted prediction algorithm is better than that of its corresponding unadapted version. The proposed algorithm provides similar (or better, in most cases) performance within significantly less run time compared to other state of the art methods. We validate our claims though extensive numerical evaluations on both synthetic and real data.
Efficient Approximate Solutions to Mutual Information Based Global Feature Selection
Jun 23, 2017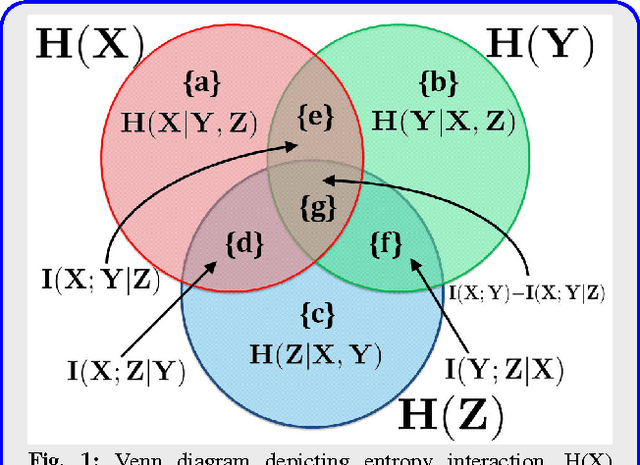
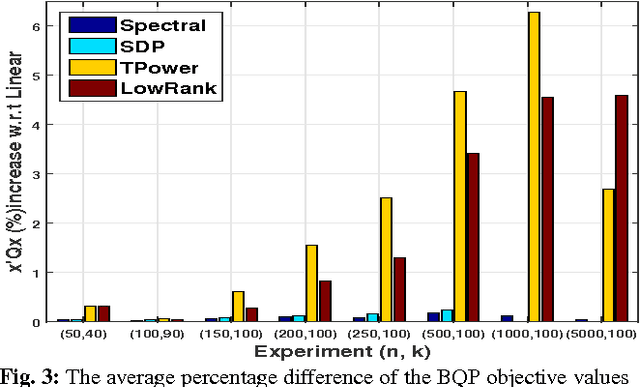
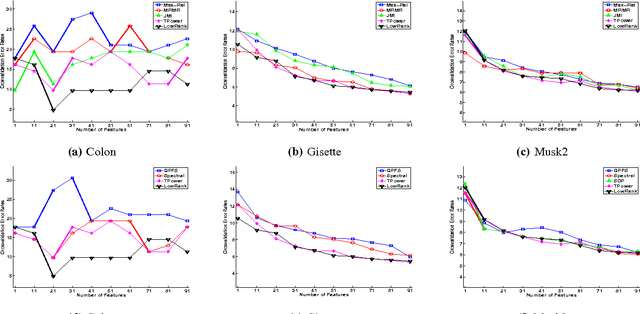
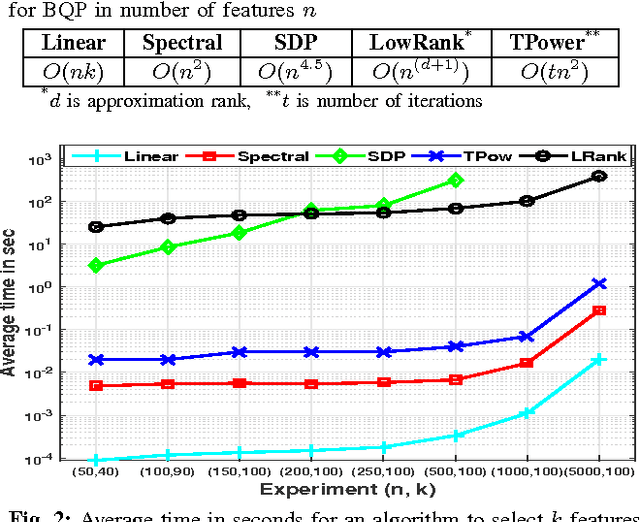
Mutual Information (MI) is often used for feature selection when developing classifier models. Estimating the MI for a subset of features is often intractable. We demonstrate, that under the assumptions of conditional independence, MI between a subset of features can be expressed as the Conditional Mutual Information (CMI) between pairs of features. But selecting features with the highest CMI turns out to be a hard combinatorial problem. In this work, we have applied two unique global methods, Truncated Power Method (TPower) and Low Rank Bilinear Approximation (LowRank), to solve the feature selection problem. These algorithms provide very good approximations to the NP-hard CMI based feature selection problem. We experimentally demonstrate the effectiveness of these procedures across multiple datasets and compare them with existing MI based global and iterative feature selection procedures.
Multiresolution Match Kernels for Gesture Video Classification
Jun 23, 2017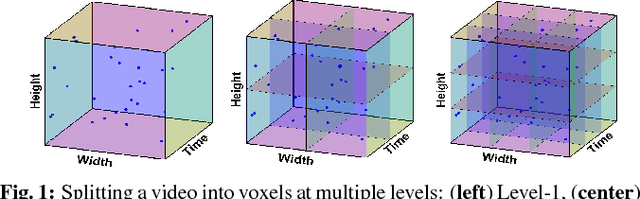
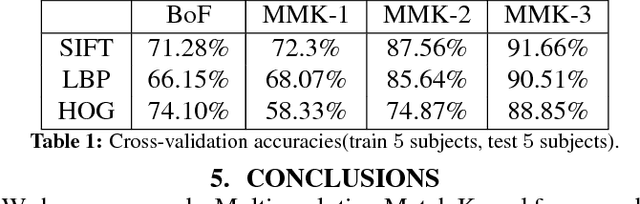
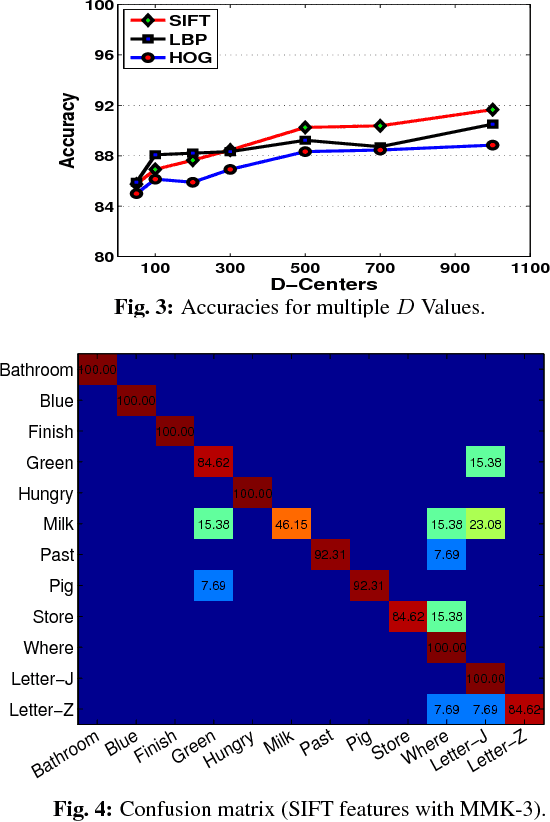
The emergence of depth imaging technologies like the Microsoft Kinect has renewed interest in computational methods for gesture classification based on videos. For several years now, researchers have used the Bag-of-Features (BoF) as a primary method for generation of feature vectors from video data for recognition of gestures. However, the BoF method is a coarse representation of the information in a video, which often leads to poor similarity measures between videos. Besides, when features extracted from different spatio-temporal locations in the video are pooled to create histogram vectors in the BoF method, there is an intrinsic loss of their original locations in space and time. In this paper, we propose a new Multiresolution Match Kernel (MMK) for video classification, which can be considered as a generalization of the BoF method. We apply this procedure to hand gesture classification based on RGB-D videos of the American Sign Language(ASL) hand gestures and our results show promise and usefulness of this new method.
Coupled Support Vector Machines for Supervised Domain Adaptation
Jun 22, 2017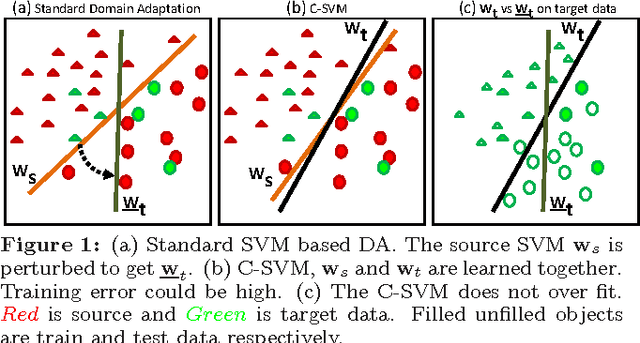
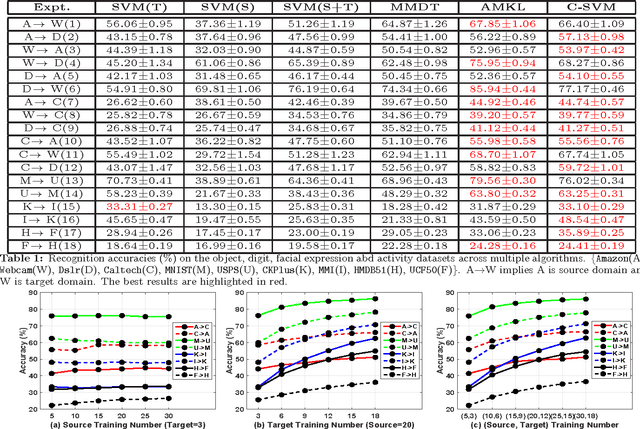
Popular domain adaptation (DA) techniques learn a classifier for the target domain by sampling relevant data points from the source and combining it with the target data. We present a Support Vector Machine (SVM) based supervised DA technique, where the similarity between source and target domains is modeled as the similarity between their SVM decision boundaries. We couple the source and target SVMs and reduce the model to a standard single SVM. We test the Coupled-SVM on multiple datasets and compare our results with other popular SVM based DA approaches.
Causal Discovery for Manufacturing Domains
Jun 13, 2016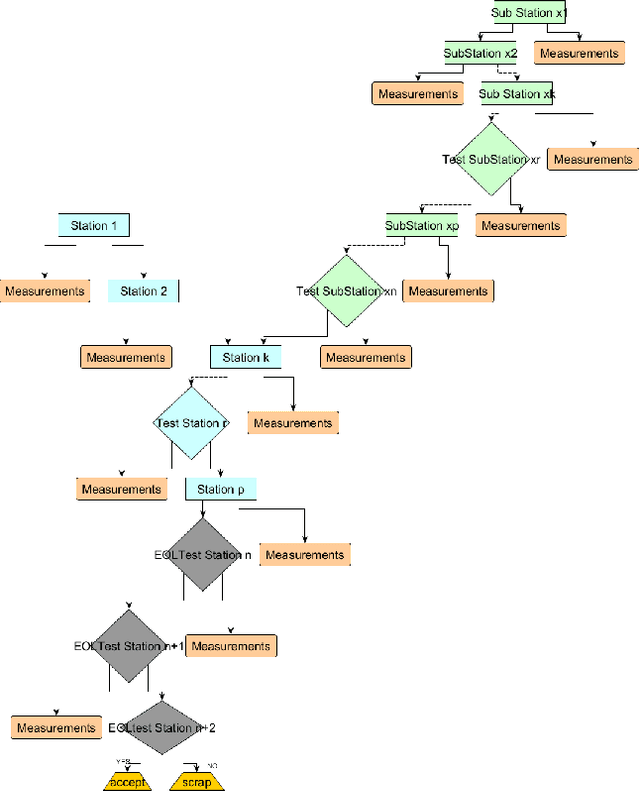

Yield and quality improvement is of paramount importance to any manufacturing company. One of the ways of improving yield is through discovery of the root causal factors affecting yield. We propose the use of data-driven interpretable causal models to identify key factors affecting yield. We focus on factors that are measured in different stages of production and testing in the manufacturing cycle of a product. We apply causal structure learning techniques on real data collected from this line. Specifically, the goal of this work is to learn interpretable causal models from observational data produced by manufacturing lines. Emphasis has been given to the interpretability of the models to make them actionable in the field of manufacturing. We highlight the challenges presented by assembly line data and propose ways to alleviate them.We also identify unique characteristics of data originating from assembly lines and how to leverage them in order to improve causal discovery. Standard evaluation techniques for causal structure learning shows that the learned causal models seem to closely represent the underlying latent causal relationship between different factors in the production process. These results were also validated by manufacturing domain experts who found them promising. This work demonstrates how data mining and knowledge discovery can be used for root cause analysis in the domain of manufacturing and connected industry.