 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDealing with Class Imbalance using Thresholding
Jul 10, 2016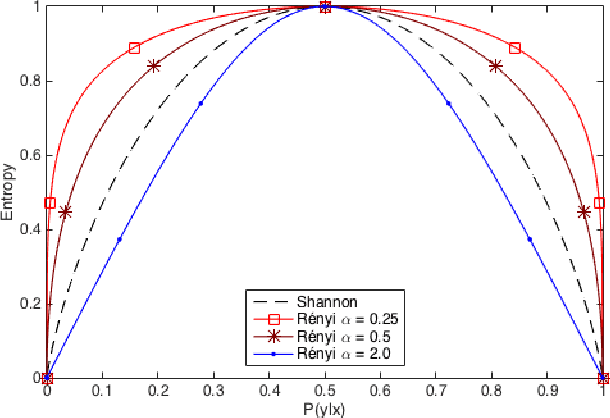
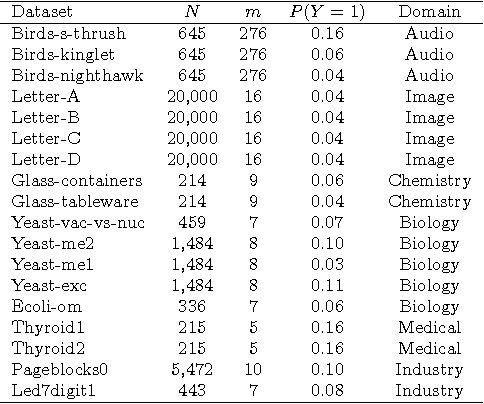
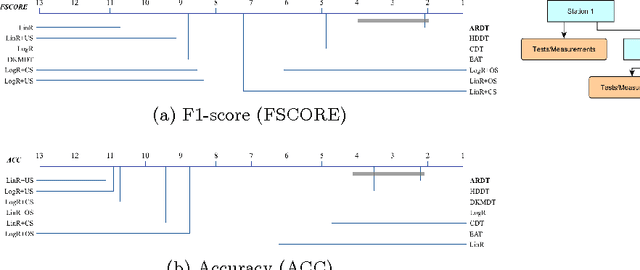
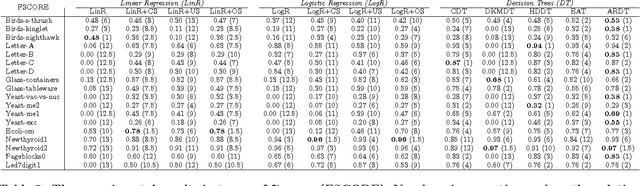
We propose thresholding as an approach to deal with class imbalance. We define the concept of thresholding as a process of determining a decision boundary in the presence of a tunable parameter. The threshold is the maximum value of this tunable parameter where the conditions of a certain decision are satisfied. We show that thresholding is applicable not only for linear classifiers but also for non-linear classifiers. We show that this is the implicit assumption for many approaches to deal with class imbalance in linear classifiers. We then extend this paradigm beyond linear classification and show how non-linear classification can be dealt with under this umbrella framework of thresholding. The proposed method can be used for outlier detection in many real-life scenarios like in manufacturing. In advanced manufacturing units, where the manufacturing process has matured over time, the number of instances (or parts) of the product that need to be rejected (based on a strict regime of quality tests) becomes relatively rare and are defined as outliers. How to detect these rare parts or outliers beforehand? How to detect combination of conditions leading to these outliers? These are the questions motivating our research. This paper focuses on prediction of outliers and conditions leading to outliers using classification. We address the problem of outlier detection using classification. The classes are good parts (those passing the quality tests) and bad parts (those failing the quality tests and can be considered as outliers). The rarity of outliers transforms this problem into a class-imbalanced classification problem.
Causal Discovery for Manufacturing Domains
Jun 13, 2016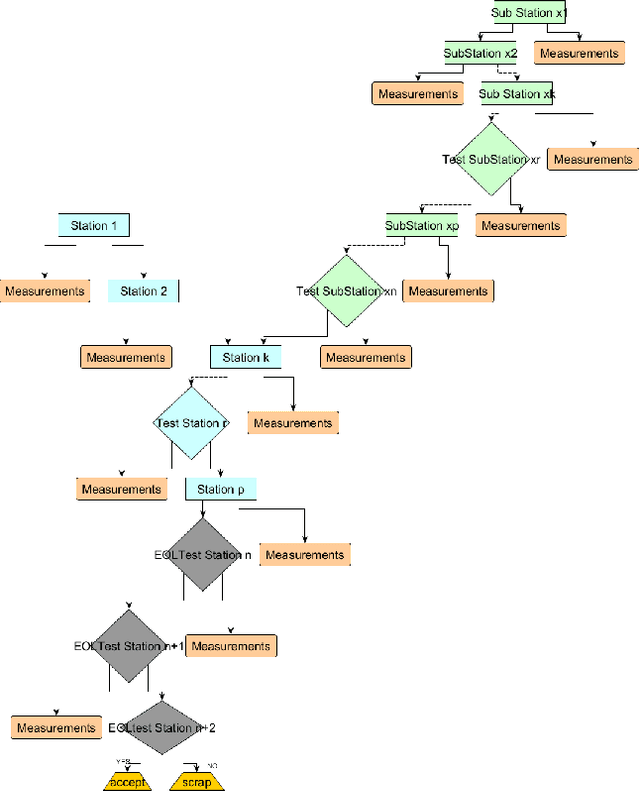

Yield and quality improvement is of paramount importance to any manufacturing company. One of the ways of improving yield is through discovery of the root causal factors affecting yield. We propose the use of data-driven interpretable causal models to identify key factors affecting yield. We focus on factors that are measured in different stages of production and testing in the manufacturing cycle of a product. We apply causal structure learning techniques on real data collected from this line. Specifically, the goal of this work is to learn interpretable causal models from observational data produced by manufacturing lines. Emphasis has been given to the interpretability of the models to make them actionable in the field of manufacturing. We highlight the challenges presented by assembly line data and propose ways to alleviate them.We also identify unique characteristics of data originating from assembly lines and how to leverage them in order to improve causal discovery. Standard evaluation techniques for causal structure learning shows that the learned causal models seem to closely represent the underlying latent causal relationship between different factors in the production process. These results were also validated by manufacturing domain experts who found them promising. This work demonstrates how data mining and knowledge discovery can be used for root cause analysis in the domain of manufacturing and connected industry.
Spectral Clustering with Epidemic Diffusion
Oct 04, 2013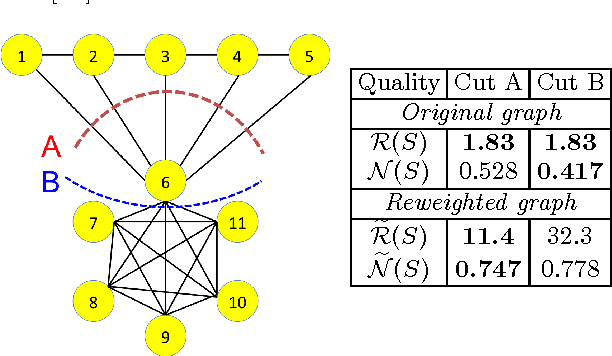
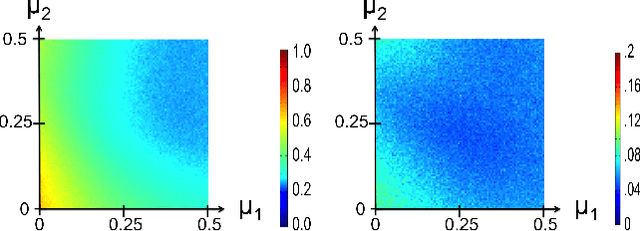
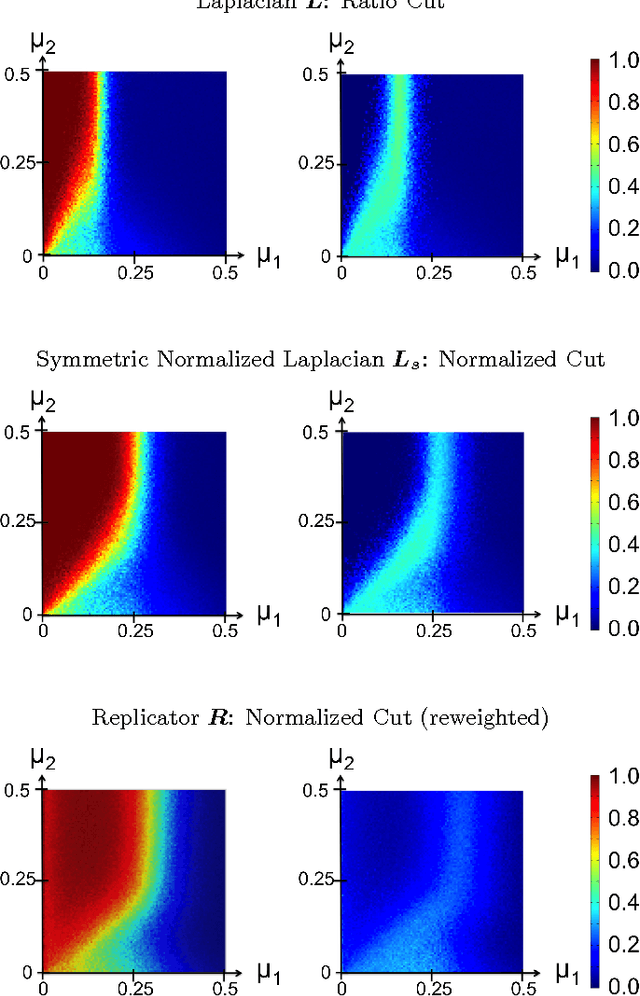
Spectral clustering is widely used to partition graphs into distinct modules or communities. Existing methods for spectral clustering use the eigenvalues and eigenvectors of the graph Laplacian, an operator that is closely associated with random walks on graphs. We propose a new spectral partitioning method that exploits the properties of epidemic diffusion. An epidemic is a dynamic process that, unlike the random walk, simultaneously transitions to all the neighbors of a given node. We show that the replicator, an operator describing epidemic diffusion, is equivalent to the symmetric normalized Laplacian of a reweighted graph with edges reweighted by the eigenvector centralities of their incident nodes. Thus, more weight is given to edges connecting more central nodes. We describe a method that partitions the nodes based on the componentwise ratio of the replicator's second eigenvector to the first, and compare its performance to traditional spectral clustering techniques on synthetic graphs with known community structure. We demonstrate that the replicator gives preference to dense, clique-like structures, enabling it to more effectively discover communities that may be obscured by dense intercommunity linking.