 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the robustness of LLM evaluation to the distributional assumptions of benchmarks
Apr 25, 2024

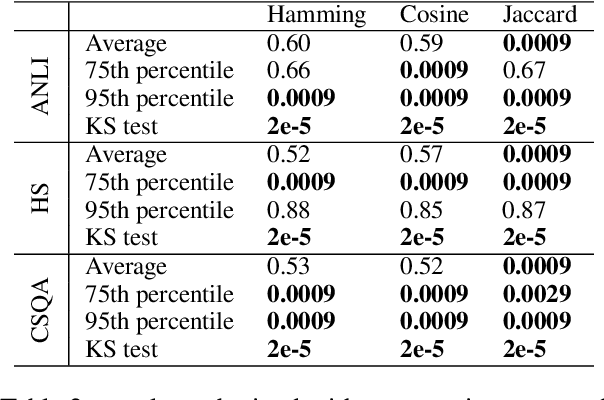

Benchmarks have emerged as the central approach for evaluating Large Language Models (LLMs). The research community often relies on a model's average performance across the test prompts of a benchmark to evaluate the model's performance. This is consistent with the assumption that the test prompts within a benchmark represent a random sample from a real-world distribution of interest. We note that this is generally not the case; instead, we hold that the distribution of interest varies according to the specific use case. We find that (1) the correlation in model performance across test prompts is non-random, (2) accounting for correlations across test prompts can change model rankings on major benchmarks, (3) explanatory factors for these correlations include semantic similarity and common LLM failure points.
Causal Discovery for Manufacturing Domains
Jun 13, 2016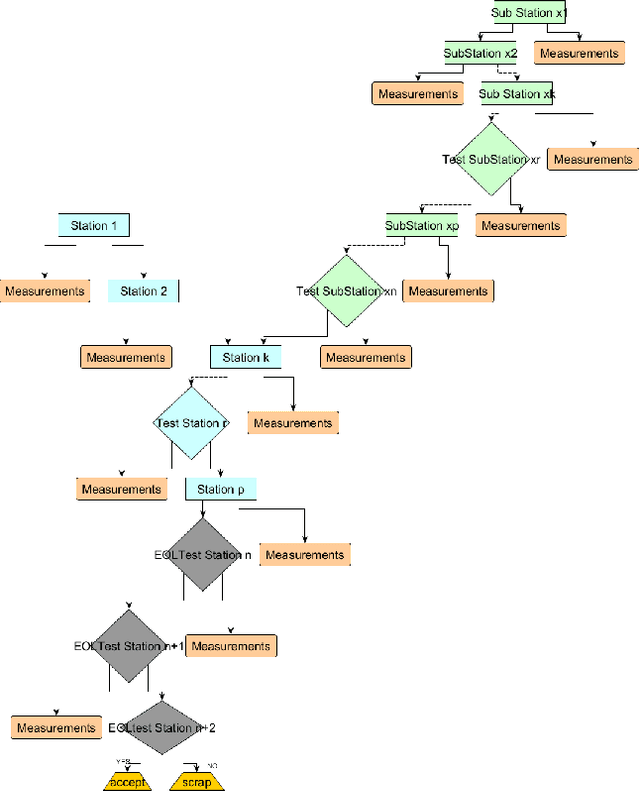

Yield and quality improvement is of paramount importance to any manufacturing company. One of the ways of improving yield is through discovery of the root causal factors affecting yield. We propose the use of data-driven interpretable causal models to identify key factors affecting yield. We focus on factors that are measured in different stages of production and testing in the manufacturing cycle of a product. We apply causal structure learning techniques on real data collected from this line. Specifically, the goal of this work is to learn interpretable causal models from observational data produced by manufacturing lines. Emphasis has been given to the interpretability of the models to make them actionable in the field of manufacturing. We highlight the challenges presented by assembly line data and propose ways to alleviate them.We also identify unique characteristics of data originating from assembly lines and how to leverage them in order to improve causal discovery. Standard evaluation techniques for causal structure learning shows that the learned causal models seem to closely represent the underlying latent causal relationship between different factors in the production process. These results were also validated by manufacturing domain experts who found them promising. This work demonstrates how data mining and knowledge discovery can be used for root cause analysis in the domain of manufacturing and connected industry.
Reasoning about Independence in Probabilistic Models of Relational Data
Jan 06, 2014
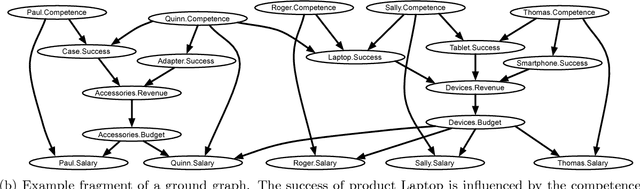

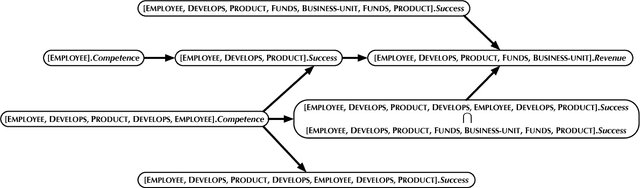
We extend the theory of d-separation to cases in which data instances are not independent and identically distributed. We show that applying the rules of d-separation directly to the structure of probabilistic models of relational data inaccurately infers conditional independence. We introduce relational d-separation, a theory for deriving conditional independence facts from relational models. We provide a new representation, the abstract ground graph, that enables a sound, complete, and computationally efficient method for answering d-separation queries about relational models, and we present empirical results that demonstrate effectiveness.
A Sound and Complete Algorithm for Learning Causal Models from Relational Data
Sep 26, 2013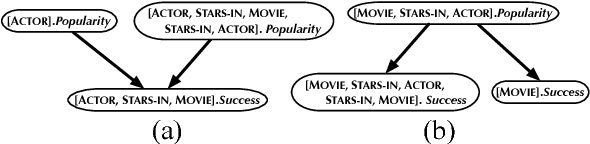

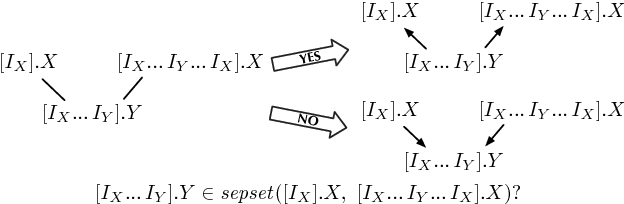
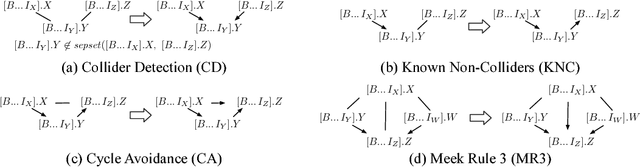
The PC algorithm learns maximally oriented causal Bayesian networks. However, there is no equivalent complete algorithm for learning the structure of relational models, a more expressive generalization of Bayesian networks. Recent developments in the theory and representation of relational models support lifted reasoning about conditional independence. This enables a powerful constraint for orienting bivariate dependencies and forms the basis of a new algorithm for learning structure. We present the relational causal discovery (RCD) algorithm that learns causal relational models. We prove that RCD is sound and complete, and we present empirical results that demonstrate effectiveness.