 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Tree Explanation Methods for Anomaly Reasoning: A Case Study of SHAP TreeExplainer and TreeInterpreter
Oct 13, 2020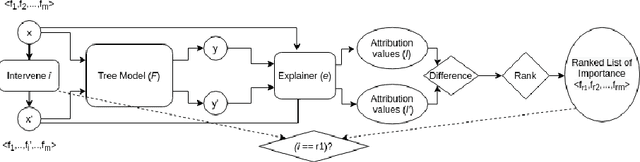
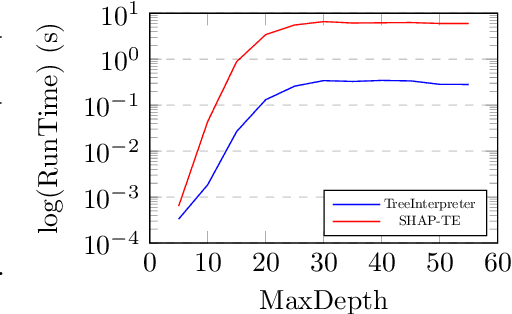
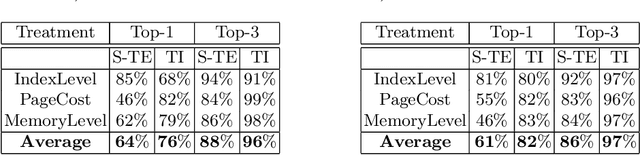
Understanding predictions made by Machine Learning models is critical in many applications. In this work, we investigate the performance of two methods for explaining tree-based models- Tree Interpreter (TI) and SHapley Additive exPlanations TreeExplainer (SHAP-TE). Using a case study on detecting anomalies in job runtimes of applications that utilize cloud-computing platforms, we compare these approaches using a variety of metrics, including computation time, significance of attribution value, and explanation accuracy. We find that, although the SHAP-TE offers consistency guarantees over TI, at the cost of increased computation, consistency does not necessarily improve the explanation performance in our case study.
Griffon: Reasoning about Job Anomalies with Unlabeled Data in Cloud-based Platforms
Aug 23, 2019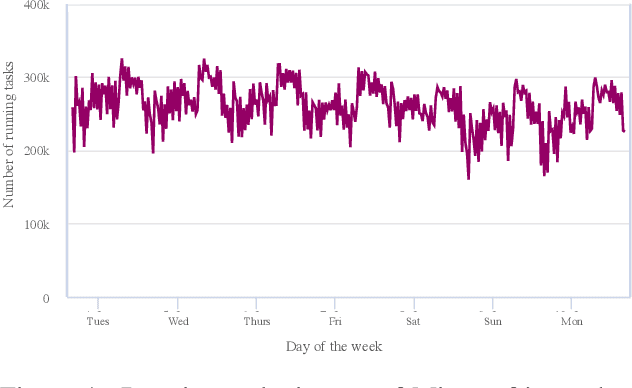

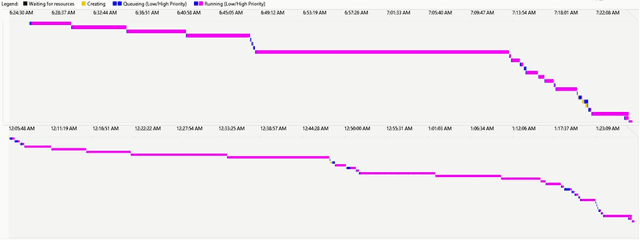
Microsoft's internal big data analytics platform is comprised of hundreds of thousands of machines, serving over half a million jobs daily, from thousands of users. The majority of these jobs are recurring and are crucial for the company's operation. Although administrators spend significant effort tuning system performance, some jobs inevitably experience slowdowns, i.e., their execution time degrades over previous runs. Currently, the investigation of such slowdowns is a labor-intensive and error-prone process, which costs Microsoft significant human and machine resources, and negatively impacts several lines of businesses. In this work, we present Griffin, a system we built and have deployed in production last year to automatically discover the root cause of job slowdowns. Existing solutions either rely on labeled data (i.e., resolved incidents with labeled reasons for job slowdowns), which is in most cases non-existent or non-trivial to acquire, or on time-series analysis of individual metrics that do not target specific jobs holistically. In contrast, in Griffin we cast the problem to a corresponding regression one that predicts the runtime of a job, and show how the relative contributions of the features used to train our interpretable model can be exploited to rank the potential causes of job slowdowns. Evaluated over historical incidents, we show that Griffin discovers slowdown causes that are consistent with the ones validated by domain-expert engineers, in a fraction of the time required by them.
MMLSpark: Unifying Machine Learning Ecosystems at Massive Scales
Oct 20, 2018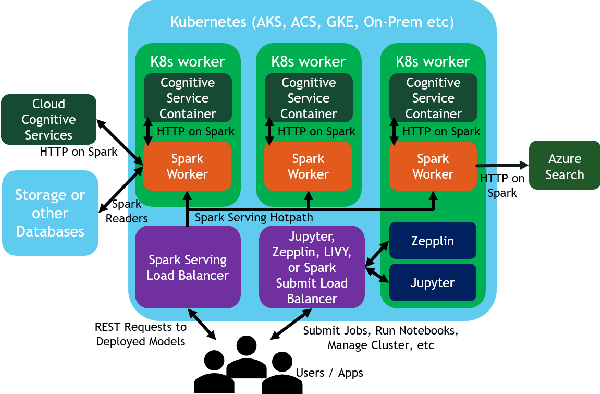

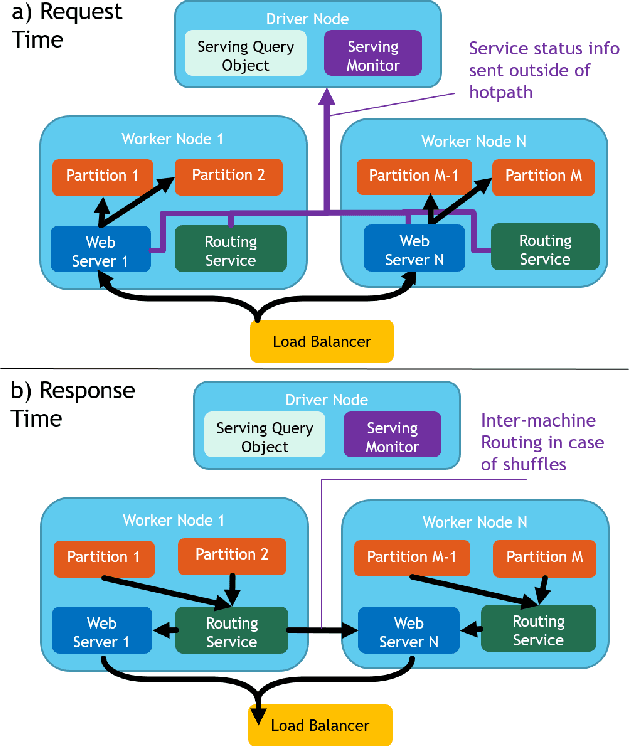
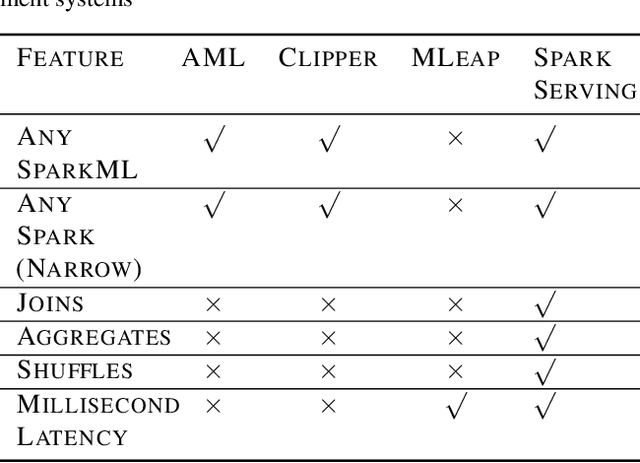
We introduce Microsoft Machine Learning for Apache Spark (MMLSpark), an ecosystem of enhancements that expand the Apache Spark distributed computing library to tackle problems in Deep Learning, Micro-Service Orchestration, Gradient Boosting, Model Interpretability, and other areas of modern computation. Furthermore, we present a novel system called Spark Serving that allows users to run any Apache Spark program as a distributed, sub-millisecond latency web service backed by their existing Spark Cluster. All MMLSpark contributions have the same API to enable simple composition across frameworks and usage across batch, streaming, and RESTful web serving scenarios on static, elastic, or serverless clusters. We showcase MMLSpark by creating a method for deep object detection capable of learning without human labeled data and demonstrate its effectiveness for Snow Leopard conservation.