 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Intelligent Microservices
Sep 17, 2020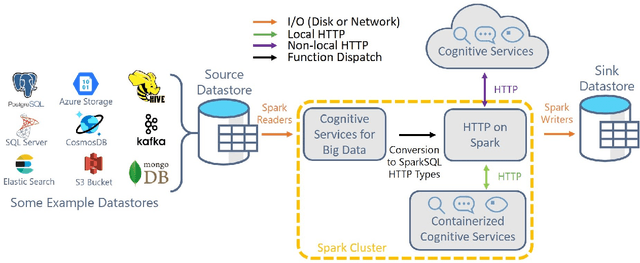
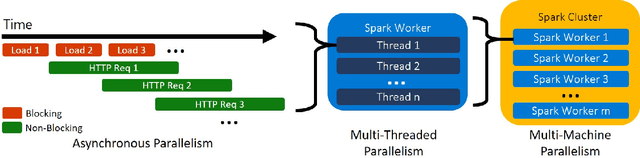
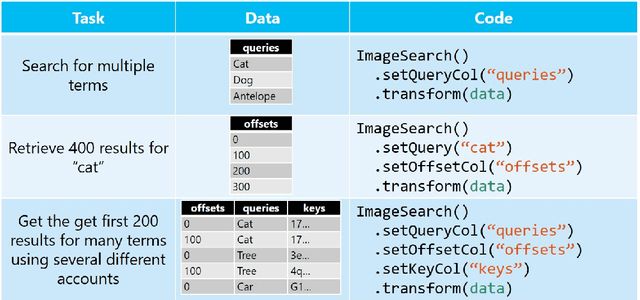
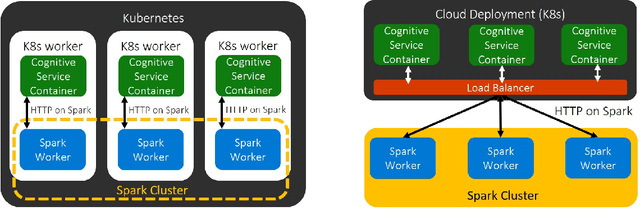
Deploying Machine Learning (ML) algorithms within databases is a challenge due to the varied computational footprints of modern ML algorithms and the myriad of database technologies each with their own restrictive syntax. We introduce an Apache Spark-based micro-service orchestration framework that extends database operations to include web service primitives. Our system can orchestrate web services across hundreds of machines and takes full advantage of cluster, thread, and asynchronous parallelism. Using this framework, we provide large scale clients for intelligent services such as speech, vision, search, anomaly detection, and text analysis. This allows users to integrate ready-to-use intelligence into any datastore with an Apache Spark connector. To eliminate the majority of overhead from network communication, we also introduce a low-latency containerized version of our architecture. Finally, we demonstrate that the services we investigate are competitive on a variety of benchmarks, and present two applications of this framework to create intelligent search engines, and real time auto race analytics systems.
MMLSpark: Unifying Machine Learning Ecosystems at Massive Scales
Oct 20, 2018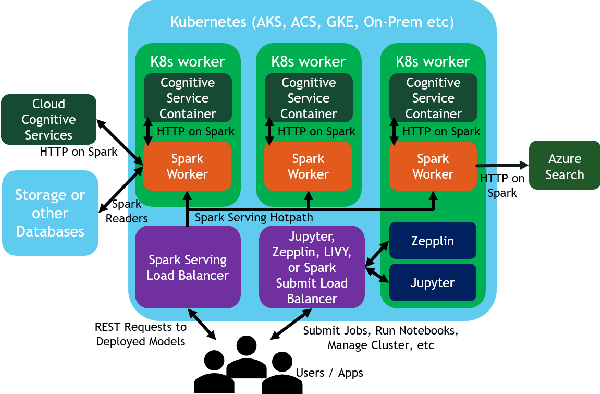

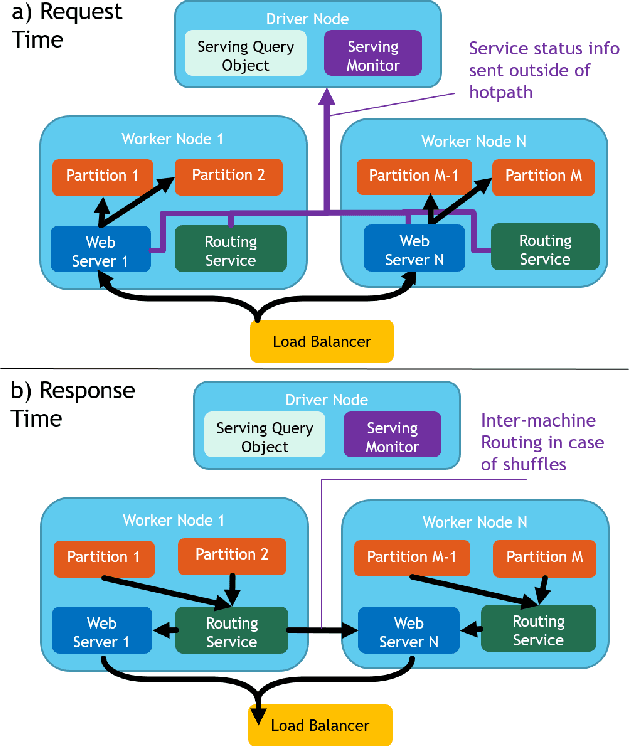
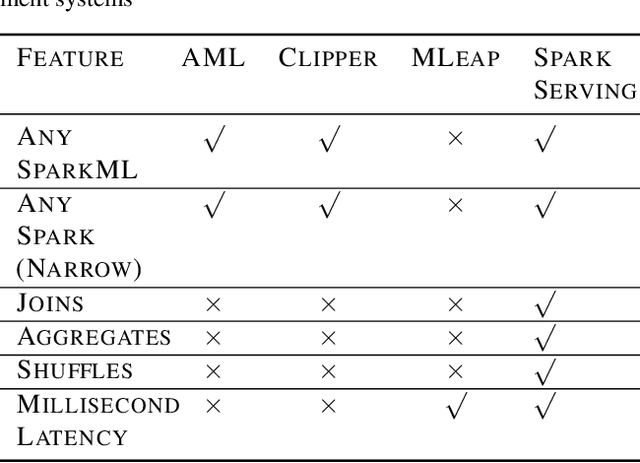
We introduce Microsoft Machine Learning for Apache Spark (MMLSpark), an ecosystem of enhancements that expand the Apache Spark distributed computing library to tackle problems in Deep Learning, Micro-Service Orchestration, Gradient Boosting, Model Interpretability, and other areas of modern computation. Furthermore, we present a novel system called Spark Serving that allows users to run any Apache Spark program as a distributed, sub-millisecond latency web service backed by their existing Spark Cluster. All MMLSpark contributions have the same API to enable simple composition across frameworks and usage across batch, streaming, and RESTful web serving scenarios on static, elastic, or serverless clusters. We showcase MMLSpark by creating a method for deep object detection capable of learning without human labeled data and demonstrate its effectiveness for Snow Leopard conservation.
A complexity measure for diachronic Chinese phonology
Aug 20, 1997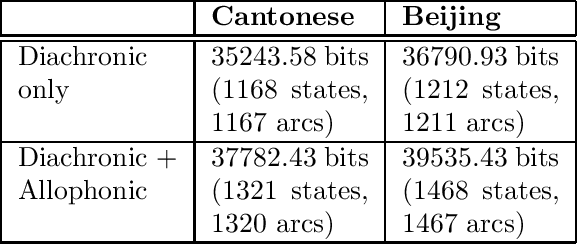
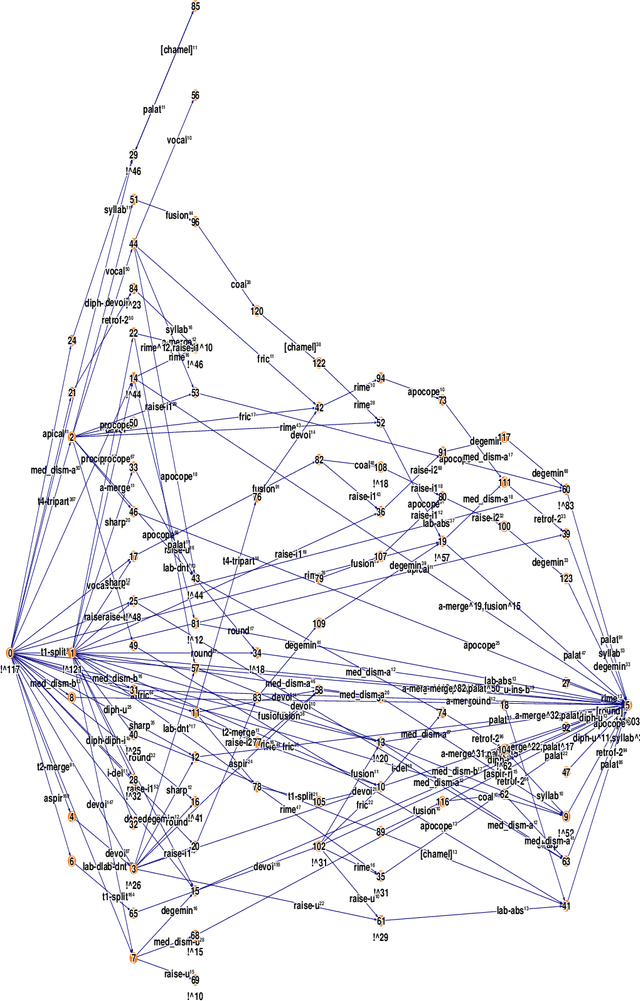
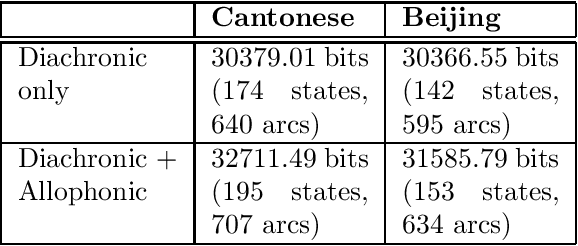
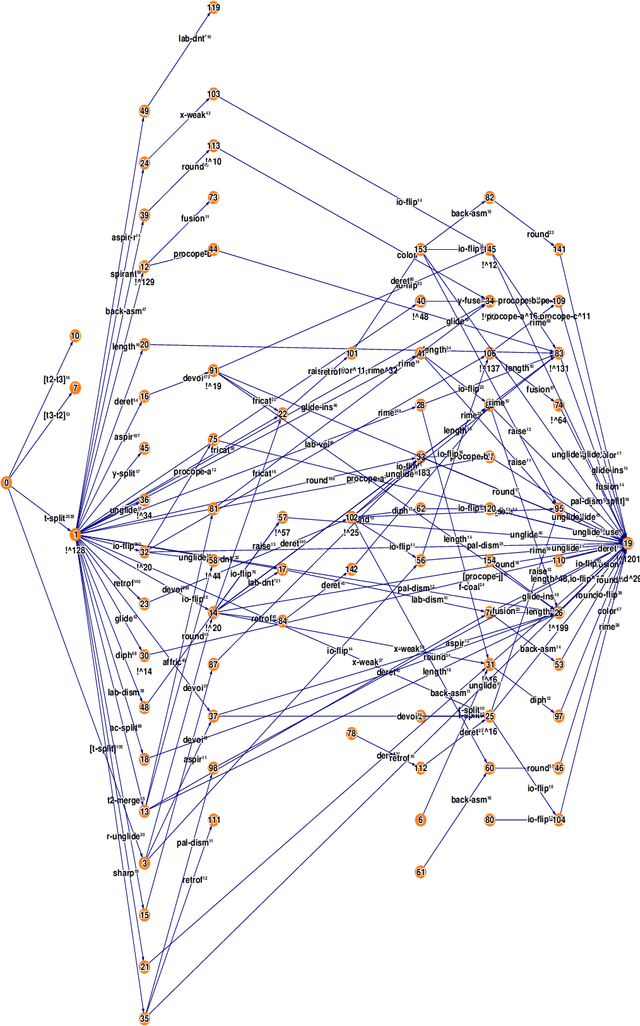
This paper addresses the problem of deriving distance measures between parent and daughter languages with specific relevance to historical Chinese phonology. The diachronic relationship between the languages is modelled as a Probabilistic Finite State Automaton. The Minimum Message Length principle is then employed to find the complexity of this structure. The idea is that this measure is representative of the amount of dissimilarity between the two languages.