 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Eval Judge: Towards a General Agentic Framework for Task Completion Evaluation
Aug 07, 2025



The increasing adoption of foundation models as agents across diverse domains necessitates a robust evaluation framework. Current methods, such as LLM-as-a-Judge, focus only on final outputs, overlooking the step-by-step reasoning that drives agentic decision-making. Meanwhile, existing Agent-as-a-Judge systems, where one agent evaluates another's task completion, are typically designed for narrow, domain-specific settings. To address this gap, we propose a generalizable, modular framework for evaluating agent task completion independent of the task domain. The framework emulates human-like evaluation by decomposing tasks into sub-tasks and validating each step using available information, such as the agent's output and reasoning. Each module contributes to a specific aspect of the evaluation process, and their outputs are aggregated to produce a final verdict on task completion. We validate our framework by evaluating the Magentic-One Actor Agent on two benchmarks, GAIA and BigCodeBench. Our Judge Agent predicts task success with closer agreement to human evaluations, achieving 4.76% and 10.52% higher alignment accuracy, respectively, compared to the GPT-4o based LLM-as-a-Judge baseline. This demonstrates the potential of our proposed general-purpose evaluation framework.
Concept Distillation from Strong to Weak Models via Hypotheses-to-Theories Prompting
Aug 18, 2024



Hand-crafting high quality prompts to optimize the performance of language models is a complicated and labor-intensive process. Furthermore, when migrating to newer, smaller, or weaker models (possibly due to latency or cost gains), prompts need to be updated to re-optimize the task performance. We propose Concept Distillation (CD), an automatic prompt optimization technique for enhancing weaker models on complex tasks. CD involves: (1) collecting mistakes made by weak models with a base prompt (initialization), (2) using a strong model to generate reasons for these mistakes and create rules/concepts for weak models (induction), and (3) filtering these rules based on validation set performance and integrating them into the base prompt (deduction/verification). We evaluated CD on NL2Code and mathematical reasoning tasks, observing significant performance boosts for small and weaker language models. Notably, Mistral-7B's accuracy on Multi-Arith increased by 20%, and Phi-3-mini-3.8B's accuracy on HumanEval rose by 34%. Compared to other automated methods, CD offers an effective, cost-efficient strategy for improving weak models' performance on complex tasks and enables seamless workload migration across different language models without compromising performance.
Two-phase Dual COPOD Method for Anomaly Detection in Industrial Control System
Apr 30, 2023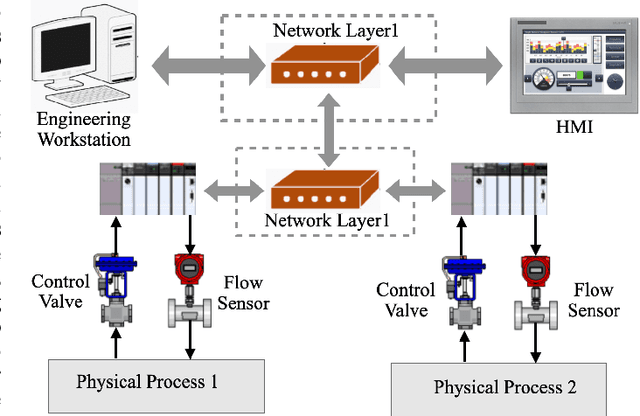

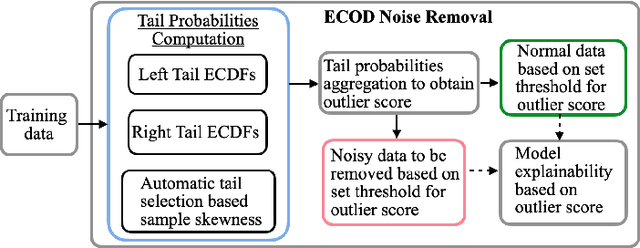

Critical infrastructures like water treatment facilities and power plants depend on industrial control systems (ICS) for monitoring and control, making them vulnerable to cyber attacks and system malfunctions. Traditional ICS anomaly detection methods lack transparency and interpretability, which make it difficult for practitioners to understand and trust the results. This paper proposes a two-phase dual Copula-based Outlier Detection (COPOD) method that addresses these challenges. The first phase removes unwanted outliers using an empirical cumulative distribution algorithm, and the second phase develops two parallel COPOD models based on the output data of phase 1. The method is based on empirical distribution functions, parameter-free, and provides interpretability by quantifying each feature's contribution to an anomaly. The method is also computationally and memory-efficient, suitable for low- and high-dimensional datasets. Experimental results demonstrate superior performance in terms of F1-score and recall on three open-source ICS datasets, enabling real-time ICS anomaly detection.
Unsupervised Ensemble Methods for Anomaly Detection in PLC-based Process Control
Feb 04, 2023Programmable logic controller (PLC) based industrial control systems (ICS) are used to monitor and control critical infrastructure. Integration of communication networks and an Internet of Things approach in ICS has increased ICS vulnerability to cyber-attacks. This work proposes novel unsupervised machine learning ensemble methods for anomaly detection in PLC-based ICS. The work presents two broad approaches to anomaly detection: a weighted voting ensemble approach with a learning algorithm based on coefficient of determination and a stacking-based ensemble approach using isolation forest meta-detector. The two ensemble methods were analyzed via an open-source PLC-based ICS subjected to multiple attack scenarios as a case study. The work considers four different learning models for the weighted voting ensemble method. Comparative performance analyses of five ensemble methods driven diverse base detectors are presented. Results show that stacking-based ensemble method using isolation forest meta-detector achieves superior performance to previous work on all performance metrics. Results also suggest that effective unsupervised ensemble methods, such as stacking-based ensemble having isolation forest meta-detector, can robustly detect anomalies in arbitrary ICS datasets. Finally, the presented results were validated by using statistical hypothesis tests.